
.png)
Xiake
Sun
Enable 2D Lip Sync Wav2Lip Pipeline with OpenVINO Runtime
Authors: Xiake Sun, Kunda Xu
1. Introduction
Lip sync technologies are widely used for digital human use cases, which enhance the user experience in dialog scenarios.
Wav2Lip is a novel approach to generate accurate 2D lip-synced videos in the wild with only one video and an audio clip. Wav2Lip leverages an accurate lip-sync “expert" model and consecutive face frames for accurate, natural lip motion generation.
In this blog, we introduce how to enable and optimize Wav2Lippipeline with OpenVINOTM.
Here is Wav2Lip pipeline overview:
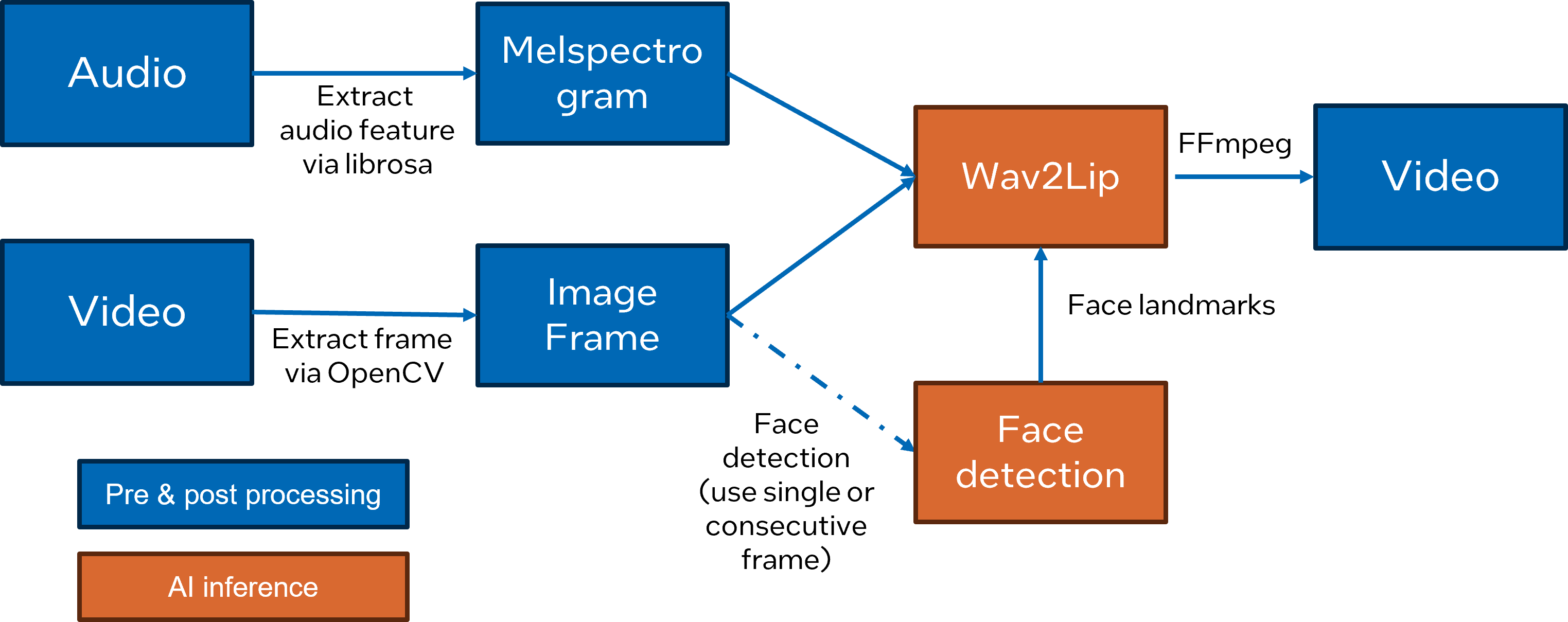
2. Setup Environment
Download the Wav2lip pytorch model from link and move it to the checkpoints folder.
3. Pytorch to OpenVINOTM Model Conversion
The exported OpenVINOTM model will be saved in the checkpoints folder.
4. Run pipeline inference with OpenVINOTM Runtime
Here are the parameters with descriptions:
--face_detection_path: path of face detection OpenVINOTMIR
--wav2lip_path: path of wav2lip openvinoTM IR
--inference_device: specify the device to run OpenVINOTMinference.
--face: input video with face information
--audio: input audio with voice information
--static: set True to use single frame for face detection for fast inference
The generated video will be saved as results/result_voice.mp4
Here is an example to compare original video and generated video after the Wav2Lip pipeline:
.gif)

5. Conclusion
In this blog, we introduce how to deploy wav2lip pipeline with OpenVINOTM as follows:
- Support Pytorch model to OpenVINOTM model conversion.
- Run and optimize wav2lip pipeline with OpenVINOTM runtime.