
.png)
Kunda
Xu
OpenVINO Enable Digital Human-TTS (GPT-SoVITs)
Authors : Kunda, Xu / Aidova, Ekaterina
Introduction
GPT-SoVITS is a powerful voice cloning model that supports a small amount of voice conversion and text-to-speech. It supports voice reasoning in Chinese, English, and Japanese.
You only need to provide a 5-second voice sample to experience voice cloning with 80%~95% similarity. If you provide a 1-minute voice sample, you can get close to the effect of a real person and train a high-quality TTS model!
As the founder of RVC Voice Changer (GitHub nickname: RVC-Boss), he recently opened up a cross-language voice cloning project. GPT-SoVITs has attracted highly praised recommendations from the industry as soon as it went online, and it has received 1.4k Stars on GitHub in less than two days. Its voice cloning effect close to that of a real person and the use of Zero-short have made GPT-SoVITs highly recognized in the field of digital humans.
Although there are many tutorials on how to use GPT-SoVITs online, in this article I will show you how to optimize it through OpenVINO and deploy it on the CPU. GPT-SoVITs belongs to the category of TTS tasks, but the difference is that it can add sound features to the generated audio by introducing additional reference audio (ref_wav), making the output audio effect closer to real people speaking.
The pipeline structure of GPT-SoVITs
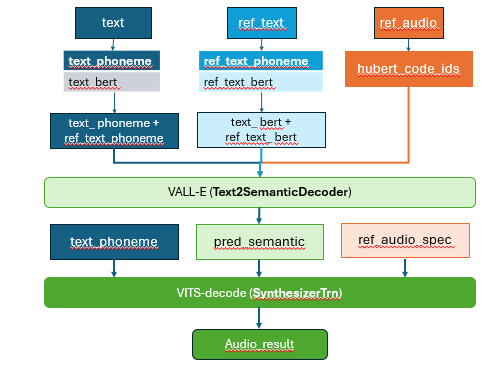
GPT-SOVITS adds a residual quantization layer to the original SOVITS input. Referring to VALL-E, the input of this quantization layer contains the text features and timbre features of the audio. GPT-SoVITs mainly consists of four parts: text preprocessing, audio preprocessing, VALL-E, VITS-decode
- Text preprocessing :
Convert text encoding information (text_ids) into pronunciation encoding information (phoneme_ids)
Use the Bert model to encode the phoneme_ids information, and take the third-to-last layer tensor as the result output
Phoneme features and Bert features are phoneme features for text, similar to pinyin
- Audio preprocessing :
Use the cn_hubert_encoder model to sample the audio information and extract the code_ids of ref_audio
Based on ref_audio, extract the frequency ref_audio_spec frame feature
- VALL-E:
Use for predict pred_sementic and idx, The idx is used to truncate pred_sementic (remove the features of the reference audio)
- VITs-decode :
Use VITS-decode to decode and get the output
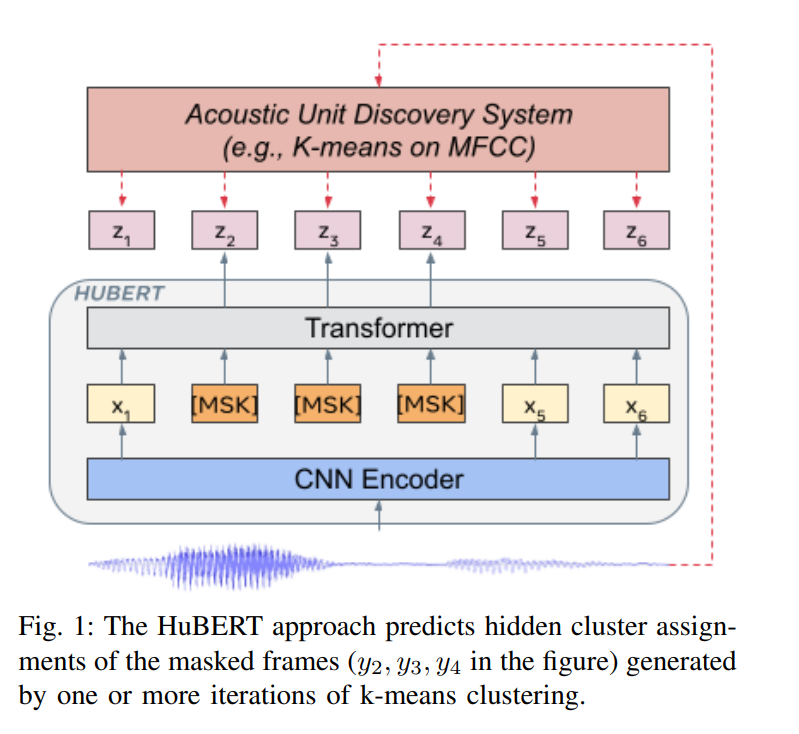
HuBert sub model
The HuBert model is designed to extract audio autoencoder features and is developed by the Facebook AI research team. The goal is to learn a universal speech representation that can capture important information in speech signals, such as speech content, speaker identity, emotional state, etc. These representations can be used in a variety of downstream tasks, such as automatic speech recognition (ASR), speaker identification, sentiment analysis, etc.
Reference paper : https://arxiv.org/pdf/2106.07447
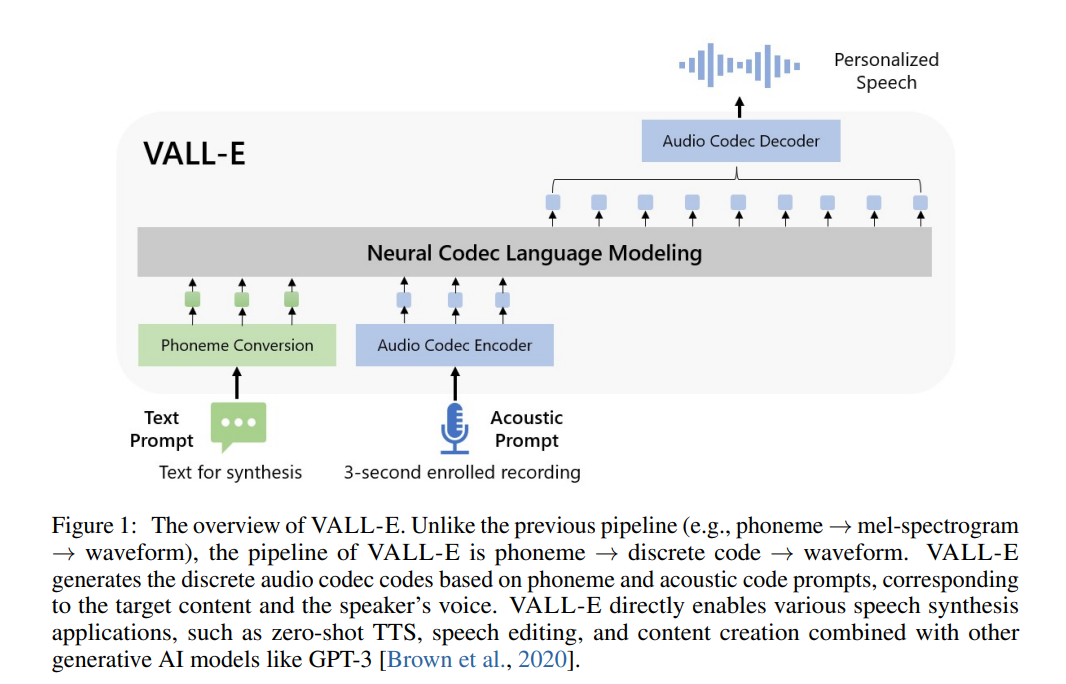
VALL-E sub model
VALL-E is a neural codec model developed by Microsoft Research, focusing on the field of speech synthesis. The characteristic of VALL-E is that it can generate synthesized speech that meets the speech characteristics of the target speaker through a small number of target speech samples (such as a 3-second speech clip). VALL-E completes the generation of speech coding based on Encoder. The GPT module of GPT-SOVITS implements the process from text to speech coding. Referring to SOVITS, a residual quantization layer is added to the original entrance. The input of this quantization layer contains the text features and timbre features of the audio.
Reference paper : https://arxiv.org/pdf/2301.02111
SoVITs sub model
The core module of GPT-SOVITS is not much different from SOVITS, which is an end-to-end text-to-speech(TTS) synthesis model. It combines variational inference and adversarial learning to generate high-quality, natural-sounding speech. It is still divided into two parts:
- Generator based on VAE + FLOW
- Discriminator based on multi-scale classifier
Reference paper : https://arxiv.org/pdf/2106.06103

By counting the inference time of the entire GPT-SoVITs pipeline, we found that the two models with the largest time overhead are text2sementic (VALL-E) and vits (VITs-decode). The total overhead of the two models accounts for 87% of the entire pipeline. Therefore, optimizing these two models through OpenVINO is very necessary to improve the performance of the entire pipeline.
You canrefer to the sample code snippet to achieve this. OpenVINO enables HuBert, Bert, VALL-E, VITs 4 sub models, and builds the pipeline based on OpenVINO.
Reference GitHub project : 18582088138/GPT-SoVITS-OpenVINO:[OpenVINO Enable]1 min voice data can also be used to train a good TTS model! (few shot voice cloning) (github.com)
Export HuBert model code snippet
HuBert sub model definition
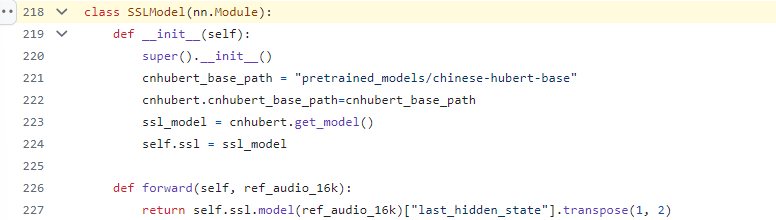
HuBert sub model convert

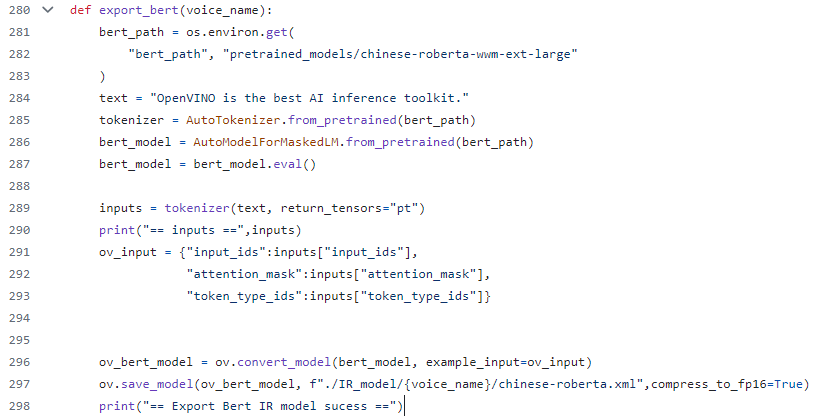
Export Bert model code snippet
Bert sub model definition and convert
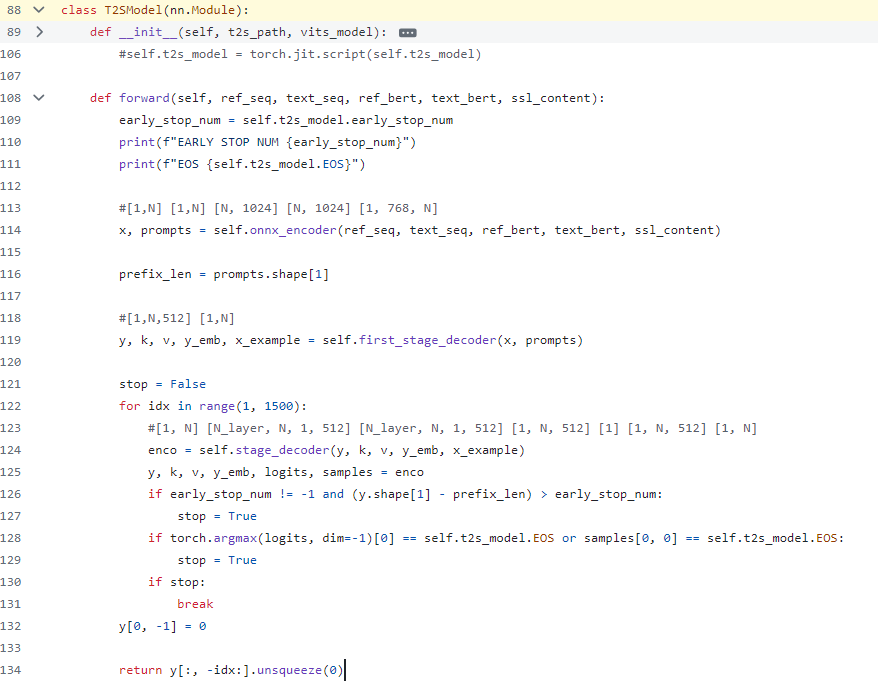
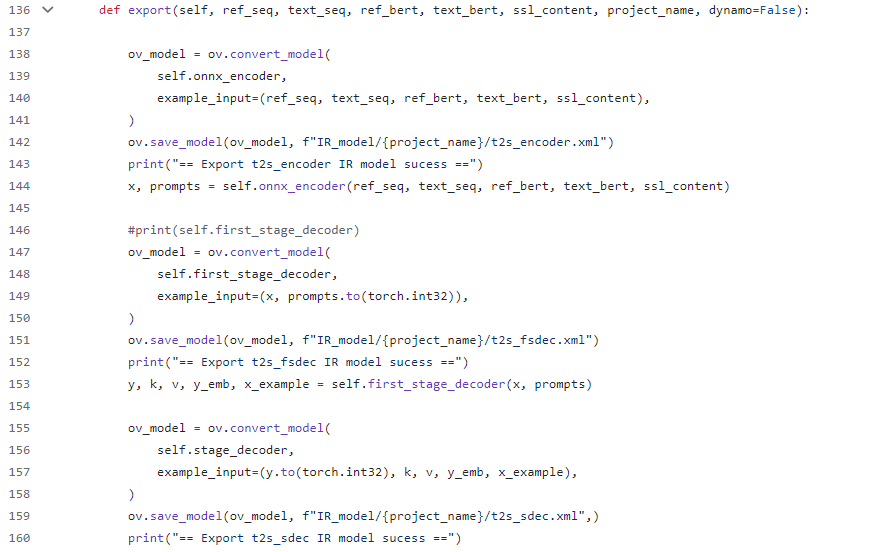
Export VALL-E model code snippet
Since t2sis defined as three modules in the source code: t2s_encoder, first_stage_decoder, stage_decoder, refer to its source code implementation and convert these three modules into corresponding IR models through OpenVINO.
However, if the generated class model can refer to the Transformer basic model for KV cache optimization, the performance of the t2s model will be further improved, but this requires some code development work, and I will add this function in subsequent work (To Do).
VALL-E sub model definition
VALL-E sub model convert
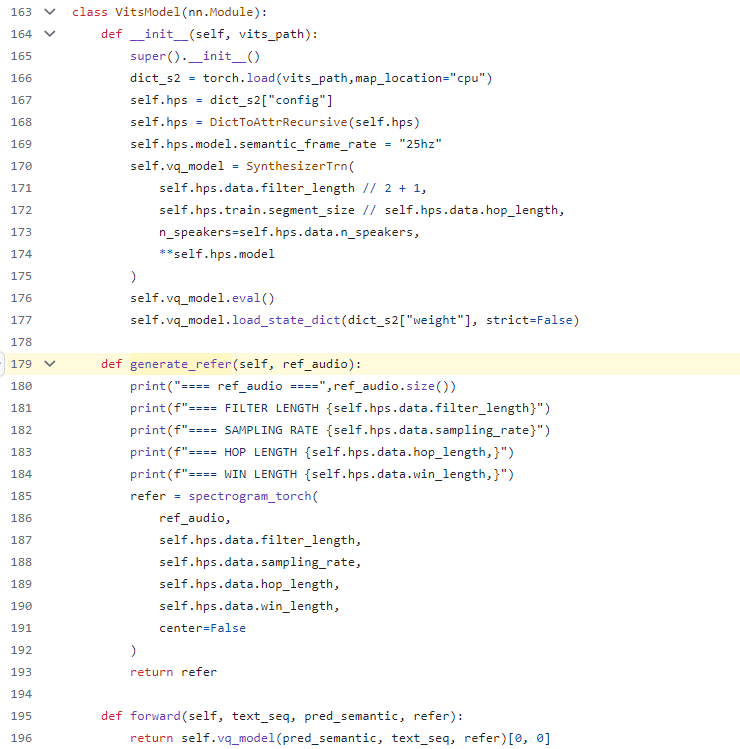
Export VITs sub model code snippet
In the VITs model, the spectrogram torch function has two operators "torch.hann_window" and "torch.stft". Currently, OpenVINO opset does not support these two operators. Therefore, this part temporarily needs to use the operators in torch opset and redefine the original VITs sub-model. After the subsequent operators are successfully supported, OpenVINO will re-enable the VITs model (To Do).
VITs sub model definition
VITs sub model convert

Finally, we rebuilt the GPT-SoVITs pipeline through the four sub models enabled by OpenVINO. You can refer to the implementation of the pipeline:
Reference link : GPT-SoVITS-OpenVINO/GPT_SoVITS/ov_pipeline_gpt_sovit.py at 18582088138/GPT-SoVITS-OpenVINO(github.com)