Authors: Su Yang, Tianmeng Chen, Hongbo Zhao This blog focuses on OpenVINO GenAI GGUF Reader updates. The model link, usage and technical details are in the previous blog: OpenVINO GenAI Supports GGUF Model
1. New Model: Qwen3
Model Graph supports Qwen3 architecture: load attn_q_norm attn_k_norm weight and add rms_norm.
2. New Pipeline Capabilities: OV Model Serialization and Logging Printing
The new enable_save_ov_model property enables serialization of the OV model generated from a GGUF model (including the tokenizer) to the same path as the GGUF file in XML/BIN format for reuse. After OV IR serialization, the path to the GGUF-converted OV model can be used directly as input.
Set environment variable to print loading and serializing time via OPENVINO_LOG_LEVEL. Example:
[GGUF Reader]: Loading and unpacking model from: gguf_models/qwen2.5-0.5b-instruct-q4_0.gguf
[GGUF Reader]: Loading and unpacking model done. Time: 196ms
[GGUF Reader]: Start generating OpenVINO model...
[GGUF Reader]: Save generated OpenVINO model to: gguf_models/openvino_model.xml done. Time: 466 ms
[GGUF Reader]: Model generation done. Time: 757ms
3. New Feature: GGUF Tokenizers and Detokenizers
Create a computation graph for tokenizers/detokenizers read from a GGUF file via the tokenizer node factory.
Downloading OV tokenizers IR and replacing the GGUF-converted OV tokenizer/detokenizer IR could be a workaround for generation anomalies.
4. Enhanced Support for GPU Plugin
Removes zero-point array modification workaround for Q4_0 weights. Supports dynamic quantization for GGUF-converted models.
Notes: Llama.cpp’s quantization GGUF block size differs from OpenVINO NNCF’s weight compression group size, so generation bias is expected. For better performance, using OV NNCF quantized model IR is recommended, as the GGUF reader still needs to dequantize Q4_0/Q4KM’s q6k tensor to FP16.
Sample Code Update:
Use GGUF file as the only input and save model via enable_save_ov_model.
Modify the file samples/cpp/text_generation/greedy_causal_lm.cpp of OV GenAI package (validated OV 25.3 nightly 20250727).
Authors: Fiona Zhao, Xiake Sun, Su Yang, Tianmeng Chen
1. Introduction:
This blog introduces the technical details of OpenVINO GenAI GGUF Reader and provides the Python and C++ implementations of OpenVINO GenAI pipeline that loads GGUF models, create OpenVINO graphs, and run GPU inference on-the-fly. To help customers integrate their existing llama.cpp-based LLM applications with OpenVINO inference, OpenVINO provides two approaches for GGUF support currently. Users can access the preview feature of the online GGUF Reader starting from the OpenVINO GenAI 2025.2 release.
GGUF (GGML Universal File Format) is the model format used by llama.cpp, a C/C++-based LLM inference framework. Models are typically trained in PyTorch, then converted and quantized into GGUF for use with llama.cpp.
The offline GGUF-to-OpenVINO approach converts and dequantizes the GGUF file into an FP16 PyTorch model. Subsequently, you can convert the PyTorch model into OpenVINO INT4 model via optimum-cli. The advantage of offline conversion is that it generates a unified OV model, which can be deployed with the C++/Python GenAI pipeline on different Intel platforms (including NPU). The drawback is the additional storage and processing overhead for PyTorch model dequantization and OV NNCF quantization. In this blog, we will focus on the second approach: Online GGUF Reader.
Key Features:
- One-Step Loading: Directly read, unpack, and convert GGUF-compressed tensors to OpenVINO format in a single API call.
- On-The-Fly Graph Creation: No intermediate PyTorch model and offline conversion with optimum-cli.
- Integrated Dequantization: Handle dequantization during inference, eliminating extra storage and preprocessing steps.
- Simplified Dependency Management: Zero PyTorch/Optimum dependencies.
2. Model library:
Validated model scope and platforms:
Quantization
Models
Validated Platforms
Q4_0
Qwen2.5--1.5B, 3B, 7B
CPU/GPU on MTL / LNL / ARL
Q4_K_M
Qwen2.5-1.5B, 3B, 7B, Llama-3.1,3.2-1B,3B,8B
CPU/GPU on MTL / LNL / ARL
Q8_0
Qwen2.5/ Llama-3.1,3.2
All CPU, GPU on MTL only*
FP16
Qwen2.5/ Llama-3.1,3.2
CPU/GPU on MTL / LNL / ARL
*Q8_0 GGUF is limited to MTL GPU, while FP16 GGUF works across MTL, LNL, and ARL GPUs.
Qwen/Qwen2.5-0.5B-Instruct-GGUF is a corner case, because Qwen2.5-0.5B-Q4KM contains a rarely used and unsupported q5_0 tensor.
In the OpenVINO GenAI 2025.2 release, the GGUF Reader does not support Qwen3 GGUF models. Support for Qwen3 GGUF is currently a work in progress (WIP) and will be added in a future update.
Our validation focuses on the widely used quantization type Q4_K_M.
Below is the list of Q4_K_M GGUF models validated on both CPU and GPU platforms (MTL, LNL, and ARL).
OpenVINO GenAI provides implicit GGUF support based on the file extension, rather than through a separate GenAI GGUF sample. Users can create an LLMPipeline directly from a .gguf file.
Python Usage:
We provide a single Python script that downloads the GGUF model and runs it with the GenAI pipeline on-the-fly.
Copy the above code into Notepad and save it as download_file.bat (ensure the file extension is .bat, not .txt). Run it by typing download_file.bat in the Command Prompt.
Or convert OpenVINO Tokenizers for the latest or other llama-based models (optional)
In GenAI 2025.2, online conversion of GGUF tokenizers to OpenVINO (OV) format is not yet supported. This capability is a work in progress and is planned for inclusion in a future release.
As a workaround, we can download the OpenVINO tokenizer or perform offline conversion for use with the C++ pipeline, as shown in the usage section.
2.GPU INT8 kernel Group-size issues for q6_k and q8_0
Both Q4_0 model (last layer) and Q4KM GGUF model have q6_k GGUF tensor. Q8_0 GGUF has q8_0.
These GGUF-converted OpenVINO IR models work with CPU inference but fail on LNL and ARL GPUs.
OV INT8 is channel-wise by default, but q6_k’s group-size is 16, while q8_0’s group-size is 32. Currently INT8 dequantization has oneDNN issue.
To support Q4_0 and Q4KM, workaround for q6_k is to convert q6_k to f16 instead of q6_k-to-int8. This has an impact on Q4KM performance (most tensors of Q4KM are q4_k). It is recommended to use Q4_0 GGUF for better performance.
GGUF Tensors Conversion Matrix
GGUF tensor type
Ideal OV type
WA OV type
q4_0
INT4
INT4
q4_k
INT4
INT4
q6_k
INT8
FP16
q8_0
INT8
*
fp16
FP16
FP16
* Q8_0 has a oneDNN accuracy issue on LNL and ARL GPUs, and currently, no workaround is available for these platforms.
5. Technical Details
OpenVINO GenAI GGUF Reader: Simplify LLM deployment with direct GGUF model loading and optimizedinference. No PyTorch dependencies, no additional conversions with intermediate PyTorch model, just high-performance inference out of the box.
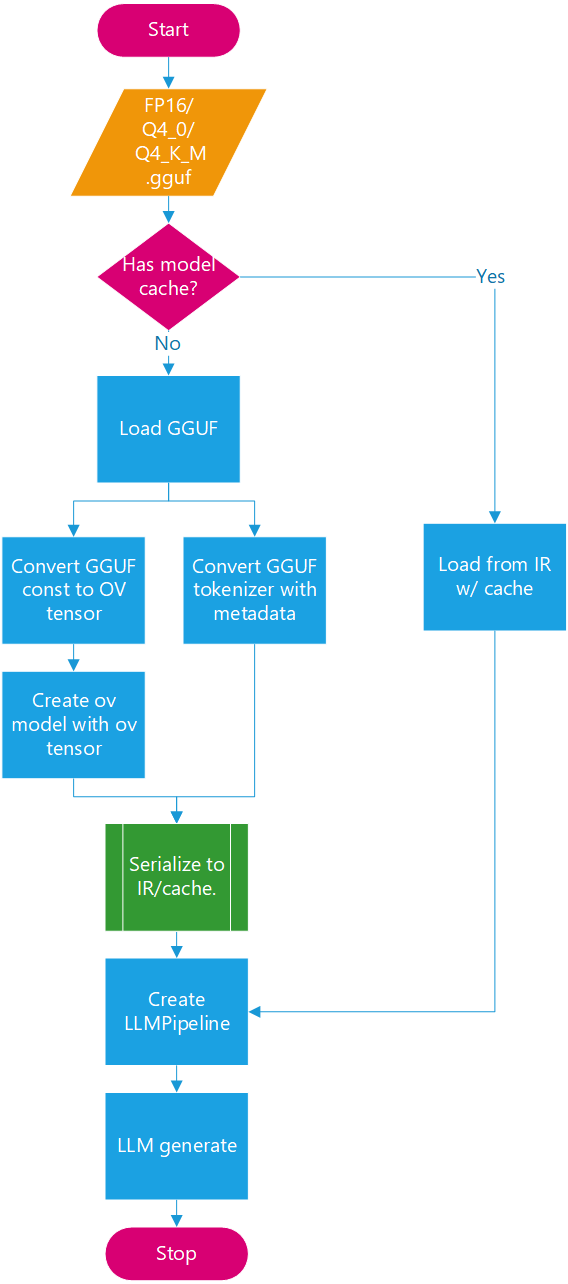
Future Architecture Workflow: In GenAI 25.2, the LLMPipeline reads GGUF files during each initialization by default. In addition to supporting online tokenizer conversion, future updates will introduce optimizations to the GGUF LLMPipeline with configuration option to save converted OpenVINO models.
Figure 1: GGUF Reader Workflow
With the architecture defined, attention turns to the quantization formats.
To analyze the characteristics of Q4_K_M, it is helpful first to distinguish it from Q4_0, Q4_1, and Q8_0. These are lightweight, pure 4- or 8-bit quantization formats designed primarily for fast loading and minimal model size.
In contrast, Q4_K_M adopts a mixed-precision 4/6-bit scheme with a super-block structure that incorporates both block_scale and block_min, enabling higher accuracy while maintaining a compact footprint.
A deeper understanding of Q4_K_M can be achieved by comparing it directly with Q4_0. Notably, Q4_K_M encompasses two distinct GGUF tensor types: q4_k and q6_k. These tensors differ not only in precision but also in group size.
Q4_K_M vs Q4_0 Comparison
Aspect
Q4_K_M
Q4_0
Quantization Type
Mixed: q4_k + q6_k (Mostly q4_k)
Pure q4_0*
Structure
Super-block with block_scale block_min
Simple linear block structure
Weight Formula
w = q × block_scale + block_min
w = q × block_scale
Group Size
q4_k: 32, q6_k: 16
32
Bit-width
4-bit (q4_k) and 6-bit (q6_k)
4-bit
Accuracy
Higher (due to mixed precision and finer quant)
Lower (compared to Q4_K_M)
* Both Qwen2.5 Q4_0 and Q4KM GGUF have q6_k GGUF tensor. Q4_0 model’s last layer “output.weight” is the only one q6_k tensor.
So, what does this look like in practice? Qwen2.5 offers a clear example.
Qwen2.5 Q4_0 and Q4_K_M GGUF models both include q6_k tensors. In Q4_0, the only q6_k tensor is typically the final layer (output.weight). While OpenVINO shares embedding weights with lm_head, GGUF keeps them separate. For certain Qwen Q4_0 models (e.g., 3B/7B), lm_head is stored as a q6_k tensor in GGUF. To align with llama.cpp behavior and improve accuracy, this weight is loaded directly from GGUF instead of using shared embeddings.
Since INT6 is not supported by OpenVINO, all q6_k tensors are converted to INT8 for both Q4_0 and Q4_K_M models. Currently, to bypass GPU limitations with group-wise INT8 dequantization, q6_k tensors are converted to FP16 at load time on CPU. The q6_k workaround introduces some loading and inference performance overhead.
Model Quantization Breakdown
Model
Quantization Type
q4_0 / q4_k Tensors
q6_k Tensors
Qwen2.5-3B-Q4_0
Q4_0
253 (q4_0)
1
Qwen2.5-3B-Q4_K_M
Q4_K_M
217 (q4_k)
37
Qwen2.5-7B-Q4_0
Q4_0
171 (q4_0)
1
Qwen2.5-7B-Q4_K_M
Q4_K_M
144 (q4_k)
20
Q4_K_M models typically contain approximately six times more q4_k tensors than q6_k tensors. As a result, q6_k to fp16 workaround is relatively acceptable in terms of performance impact.
By leveraging common optimization techniques during the model loading phase, the overall pipeline latency can be further minimized.
Loading optimizations:
- Parallel Parsing: Uses ov::parallel_for for multi-threaded.
- Split-File Support: Compatible with llama.cpp’s sharding scheme for loading large GGUF models.
Loading performance results show that the Qwen2.5-7B-Q4_K_M model can be extracted and generated into an OpenVINO model graph in under 10 seconds on an Intel LNL U7 268V, dramatically outperforming the offline GGUF-to-OpenVINO approach, which takes about 4 minutes and over 15 GB of memory to save the PyTorch FP16 model (e.g., Llama-3.1-8b-Q4_K_M).
Thank you to all authors! Additionally, thanks to Kozlov, Alexander, and Lavrenov, Ilya for their contributions to the GGUF reader.

.png)