
.png)
Kunda
Xu
OpenVINO Optimization-LLM Distributed
Author : Kunda,Xu / Zhai, Xiuchuan / Sun, Xiaoxia / Li, Tingqian / Shen, Wanglei
Introduction
With the continuous development of deep learning technology, large models have become key technologies in many fields, such as LLM, Multimodal, etc. The training of large models requires a lot of computing resources, and the reasoning and deployment of LLM also require a lot of resources, which promotes the widespread application of distributed parallel technology. Distributed parallel technology can distribute a large model to multiple computing nodes and accelerate the training and reasoning process of the model through parallel computing. It mainly includes strategies such as Model Parallel(MP), Data Parallel(DP), Pipeline Parallel(PP), and Tensor Parallel(TP).
In this blog we will focus on OpenVINO's distributed optimization of LLM by tensor parallel.
Tensor parallel is a technique used to fit a large model in multiple device. For example, when multiplying the input tensors with the first weight tensor, the matrix multiplication is equivalent to splitting the weight tensor column-wise, multiplying each column with the input separately, and then concatenating the separate outputs. These outputs are then transferred from the CPUs/GPUs and concatenated together to get the final result.
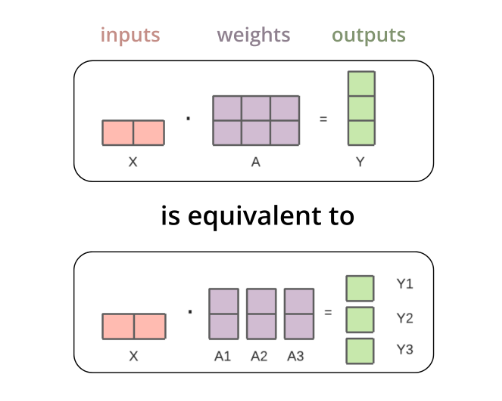
Taking the implementation of Fully Connect(FC) layer tensor parallel as an example, we introduce OpenVINO's distributed optimization of LLM. In the statistics of the inference time overhead of LLM tasks, we found that due to the large parameter size of LLM, the FC layer will take up a large time overhead. By optimizing the latency of the FC layer, the LLM first token/second token latency can be effectively reduced.
Fully connect layer refers to a neural network in which each neuron applies a linear transformation to the input vector through a weights matrix. As a result, all possible connections layer-to-layer are present, meaning every input of the input vector influences every output of the output vector.
In OpenVINO, SplitFC is used to split the FC layer into two device nodes to implement tensor parallelism.
SplitFC detects FC CPU operation with and without compressed weights. And then splits the FC into several small FCs by output channel according to sub stream number. The goal is that the executor can dispatch the split FCs to different numa nodes in the system. As a result, the split FCs can be executed at the parallel level.
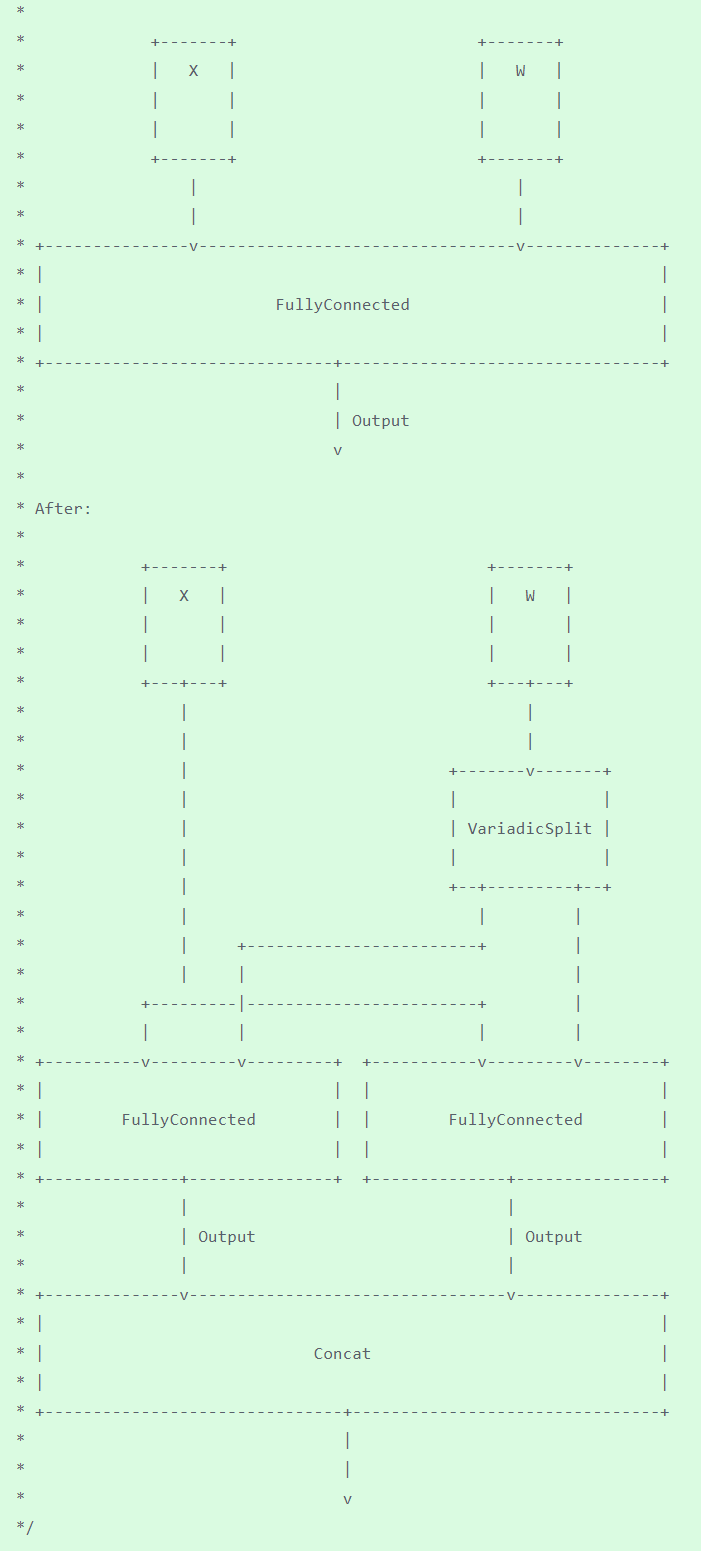
The following describes how to use the distributed features in OpenVINO to deploy the model on two CPU nodes to improve the performance of LLM.
Step 1. setup environment
Step 2. clone openvino.genai source code and install requirement
Step 3. prepare OpenVINO IR LLM model
The conversion script for preparing benchmarking models, convert.py allows to reproduce IRs stored on shared drive. Make sure the prerequisty requirements.txt has already install.
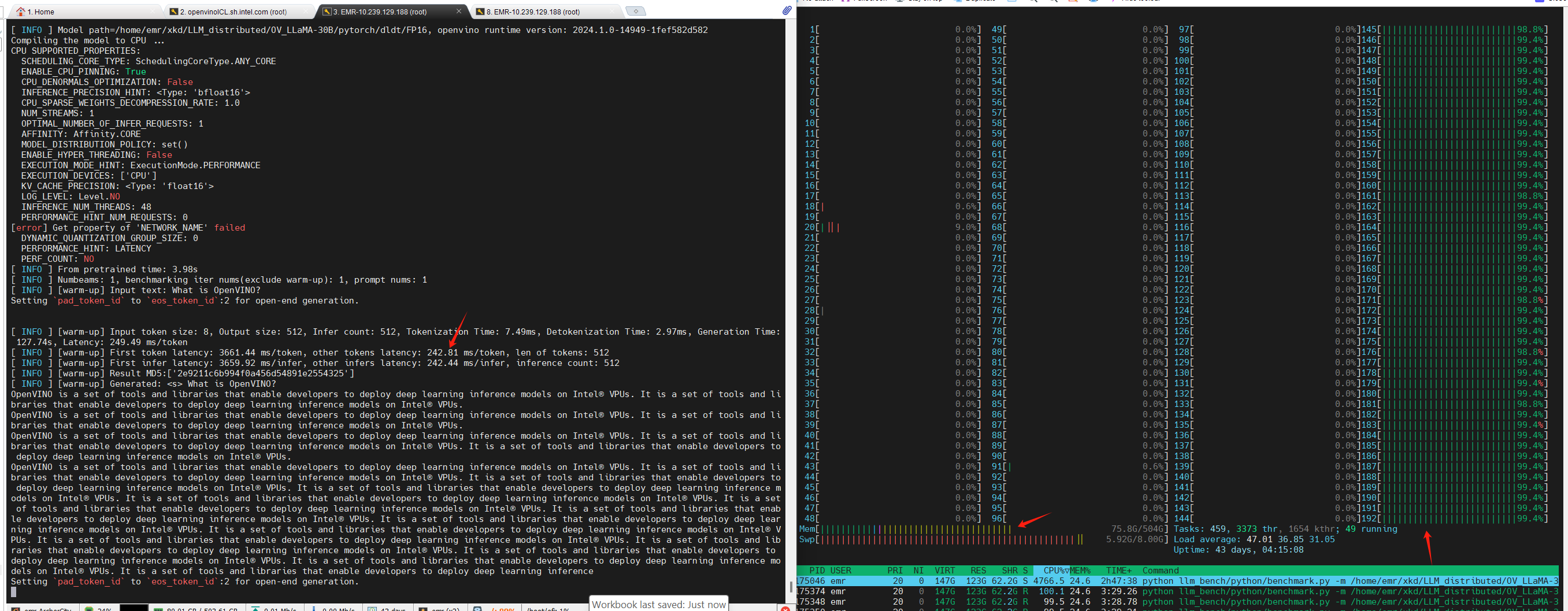
Step 4. LLM run pipe OpenVINO genai benchmark on single socket
Step 5. LLM run pipe OpenVINO genai benchmark distributed on double sockets
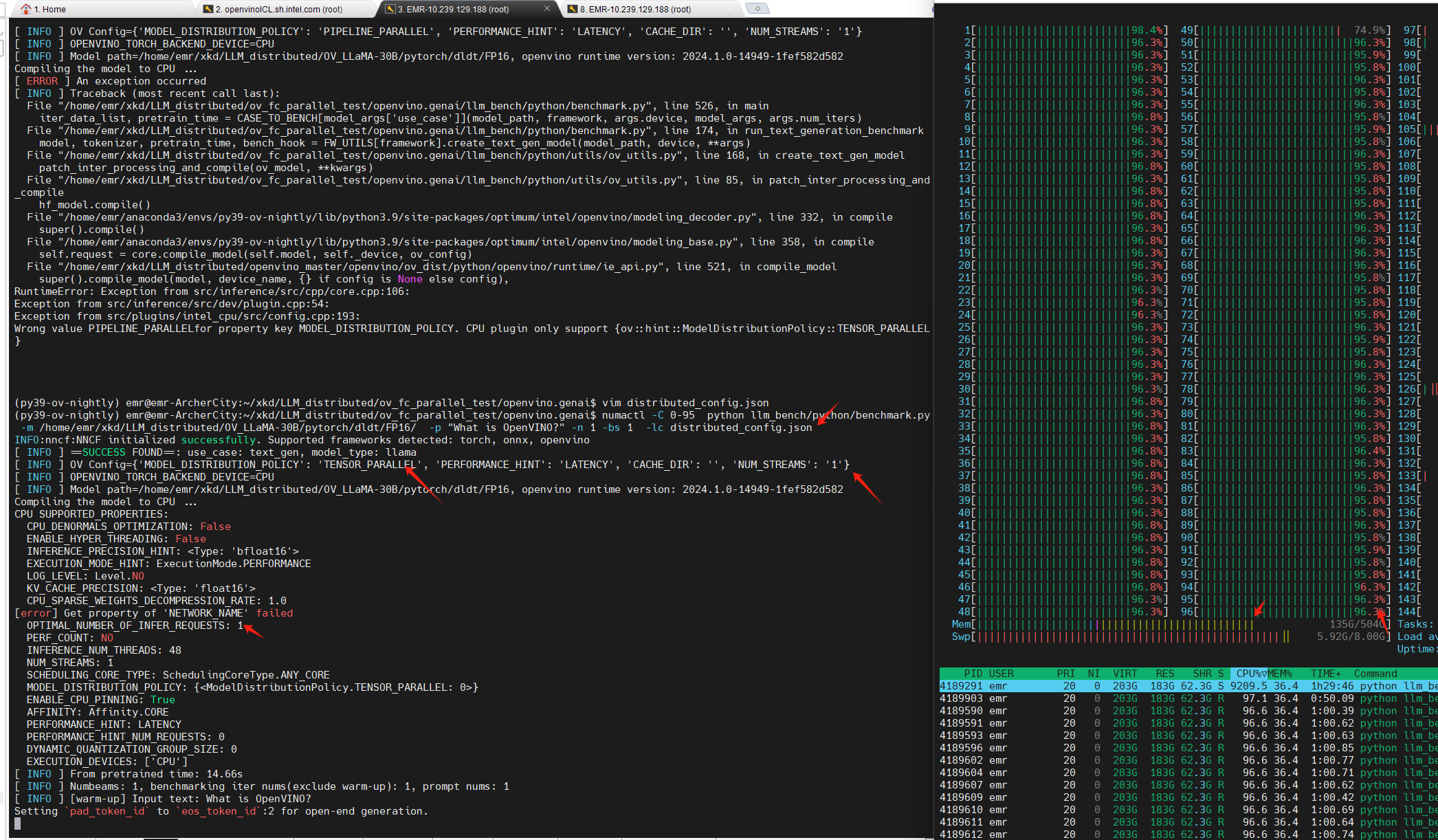
As can be seen from the figure above, nstream=1, nireq=1,LLM runs on two sockets, and from the printout of OV_config, we can see that MODEL_DISTRIBUED_POLICY has turned on the TENSOR_PARALLEL feature;
Using OpenVINO distributed feature can significantly reduce the first token/second token latency for general LLM models.