
.png)
Kunda
Xu
OpenVINO™ model transformation –MHA subgraph optimization
Authors:Kunda Xu, Yi Zhang, Chenhu Wang
Introduction
Due to significant advancements in microprocessor technologies, computational ability has grown faster than the memory bandwidth over the past decades. As a result, most linear operations in vector space are memory-bounded, so the execution time is limited by the memory bandwidth. The rare exceptions include convolutions and matrix multiplications. These exceptions could be especially important for some workloads, so a lot of vectorization and parallelization works are done to increase their computational throughput (Advanced Matrix Registers for example). In this blog, let’s focus on the optimization methods on low parallel efficiency and memory-bounded operations which are widely used in transformers models. And we will introduce how to use OpenVINO™ transformations feature and will use a sample with MHA fusion optimization to show.
In this blog, we will introduce optimization technics of OpenVINO™ for model structure from the following angles.
- MHA subgraph structure and optimization method.
- OpenVINO™ model transformation introduction- new feature Snippets
- Case study: MHA subgraph OpenVINO optimization
Requirement
OpenVINO >= 2023.0
OpenVINO™ is an open-source toolkit for optimizing and deploying AI inference which can boost deep learning performance in computer vision, automatic speech recognition, natural language processing and other common tasks.
Reference: OpenVINO™ install guide - Linux
MHA structure and optimization method
Multi-Head Attention (MHA) is a key component in the Transformer model used in NLP. It enhances representation and modeling by learning multiple sets of attention weights simultaneously, allowing the model to capture diverse patterns and dependencies. MHA enables parallel computation, improves robustness by filtering out noise, and scales well for longer sequences. Overall, MHA enhances the Transformer model's capabilities and improves performance in various NLP tasks.
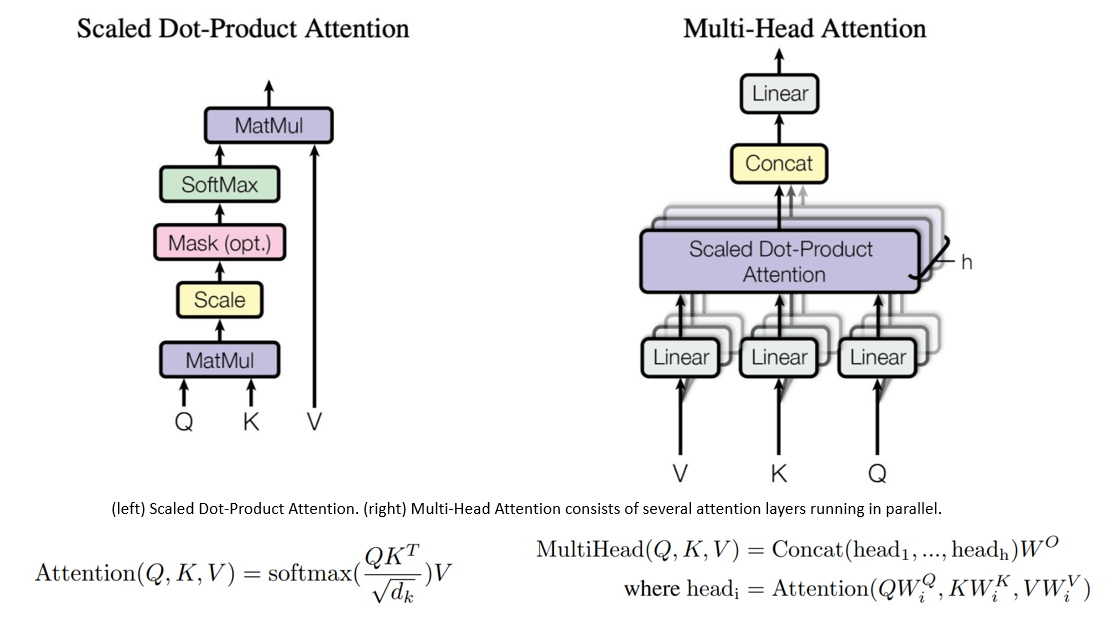
Each "head" of MHA may focus on different parts of the input, thus enabling the model to capture richer and more diverse information. The characteristics of the attention structure that its excellent context-related ability needs to be exchanged for a large amount of computational complexity and memory resources and will be more complicated during the model training process. An inappropriate learning rate may lead to overfitting of the model or difficulty in converging the model loss function.
Transformers are slow and memory-hungry on long sequences since the time and memory complexity of self-attention are quadratic in sequence length. Approximate attention methods have attempted to address this problem by trading off model quality to reduce the computing complexity.
For the mainly optimized workflow, there are two main optimization points:
- MHA calculation logic optimization, optimize the utilization rate of CPU cache in the model calculation process, reduce the time overhead of data copy, improve the utilization rate of data in the cache and improve the performance of hot point operator attention.
- MHA operator fusion optimization, through the operation of operator fusion and subgraph fusion, the IO cost of data will be reduced, and the inference performance of the model will be improved.
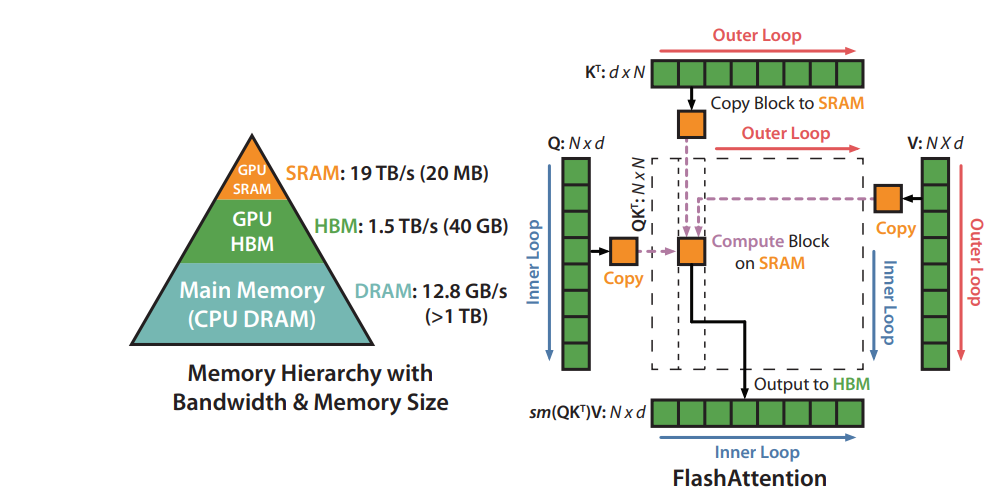
Based on above two optimization points, we found a mature solution called “FlashAttention” which already been proposed for discrete GPU(dGPU) computing optimization. So that we reference FlashAttention, a new attention algorithm that computes exact attention with far fewer memory accesses, to optimize the attention subgraph on CPU.
FlashAttention subgraph optimization workflow
The original FlashAttention algorithm on dGPU uses tiling to prevent materialization of the large 𝑁 × 𝑁 attention matrix (dotted box) on (relatively) slow GPU HBM. In the outer loop (red arrows), FlashAttention loops through blocks of the K and V matrices and loads them to fast on-chip SRAM. In each block, FlashAttention loops over blocks of Q matrix (blue arrows), loading them to SRAM, and writing the output of the attention computation back to HBM.
Using OpenVINO transformation feature instruction, we optimize the data flow about MHA subgraph, Since the algorithm is planned to use on the CPU, we need to optimize the memory usage and calculation process between the caches at each level of the CPU. And the optimized data workflow about MHA subgraph which integrated in the OpenVINO, the graph is shown like below.
OpenVINO MHA subgraph optimization workflow
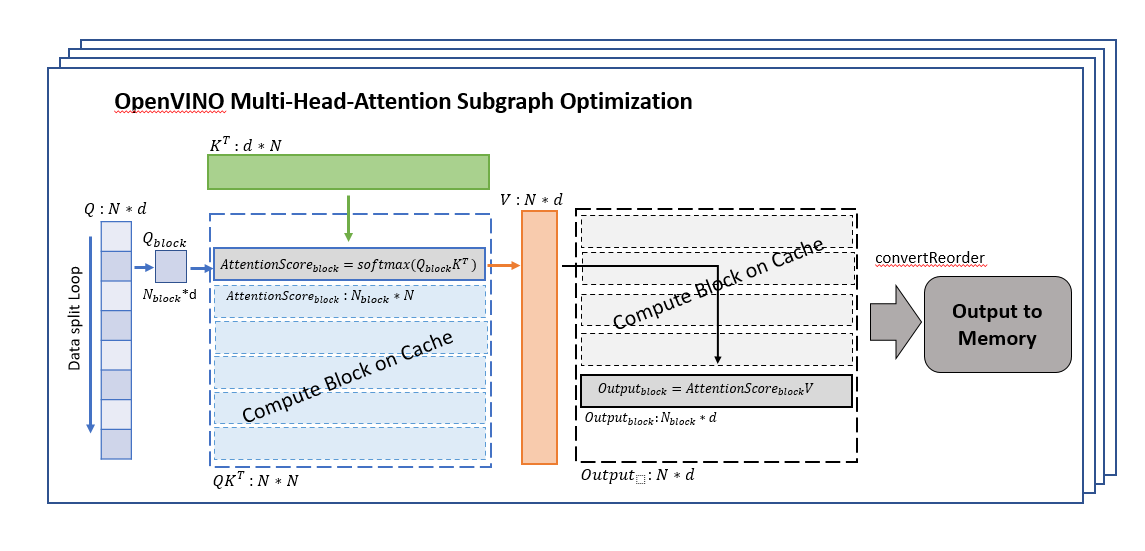
We divide the Q matrix into Q_block (shape is N_block*d) in the dimension of N (sequence tokens length), because the calculation characteristics of SoftMax can support us to calculate the data of each row separately, so that we can ensure that the K matrix is consistent with each During the calculation of Q_block, the data of the K matrix can be stored in the CPU cache, reducing the time overhead caused by data transfer in memory and cache, and processing the data of one block at a time can make full use of the computing resources of each core.
An other point to note is that to ensure that the data of each set of K*Q_block can be in the same cache, we need to manually specify that each set of calculations is completed in one thread (OneDNN creates multiple threads for single block computing which the cache cannot be reused, and lead to a worse performance in memory-bound scenarios. It is the main reason do not adopt OneDNN for transformers).
After getting AttentionSorce_block, it can be directly calculated with V matrix, because the size of AttentionSorce_block is N_block*N, the size of the V matrix is N*d, so there is no need to wait until all AttentionSorce calculations completed, and Output_block can be directly calculated, which can reduce the waiting time for data synchronization and further improve calculation efficiency.
After waiting for the calculation of all divided block data to be completed, all the results are spliced, and reorder the output data structure to meet the following node input shape request, and then the data will be copied to the memory.
During the entire MHA subgraph calculation process, by balancing the relationship between the amount of data and the size of the CPU cache, the utilization rate of data in the cache is improved, the time overhead of data transfer is reduced, the utilization rate of advanced caches is fully utilized, the calculation time is reduced, and the performance for computational performance of the operator.
If you want to know more detail about the MHA subgraph optimization implementation, reference MHA node source code.
Reference : MHA node source code
OpenVINO transformations optimization
In OpenVINO's optimization process for the model structure, we can organize it into a pipeline as shown in the figure below. The whole process includes two parts: the structural transformation of nGraph and the transformation of internal plugin graph.
During the nGraph transformation process, modules including common transformations and LPT (Low Precision Transformations) Snippets Tokenizer, etc. will perform some rule-based or automatic compilation structure replacement and optimization on the graph of the model
In the process of internal plugin graph transformation, the optimized nGraph will be deeply optimized for the platform through the optimizer and generator and compiled into kernel execute code that can run on the target platform
In this blog, we will focus on the characteristics and usage of Snippets.
Snippets Architecture
Snippets is known as a graph compiler, a highly specialized compiler for computational graphs.
.png)
Below graph is the detail workflow of Snippets
.png)
Snippets take nGraph model as an input, instead of a source code, the workflow consists of three major blocks: Tokenizer, Optimizer and Generator:
- Tokenizer (the Snippets Frontend) optimize nGraph model and tries to convert to an nGraph IR and stores inside a Subgraph node.
- Optimizer (the Snippets body), to improve the program in a desired way without modification of its meaning.
- Generator (the Snippets Backend) uses the optimized IR to produce executable code.
Snippets Tokenizer algorithm
Tokenizer run on an nGraph model and the main purpose is to identify subgraphs that are suitable for code generation.
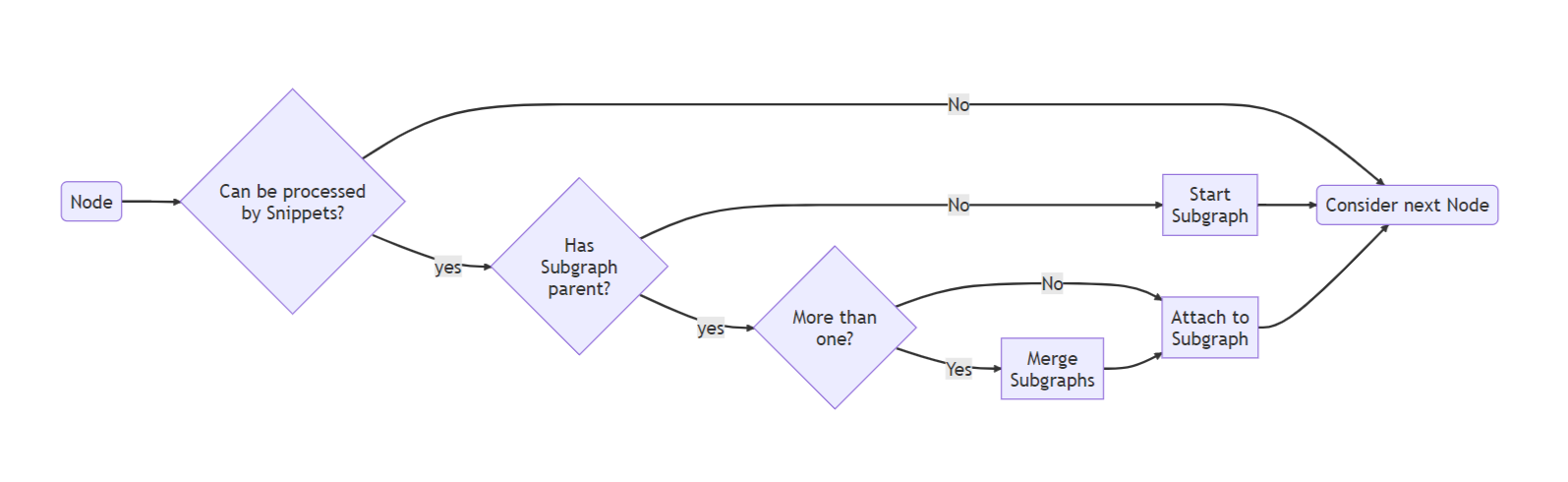
Pattern matching can indeed process only a limited set of predefined operations' configurations, so the relations between the operations are fixed in this case. Thus, the tokenizer's flexibility becomes a significant advantage when the number of new ML topologies increase srapidly, so it becomes more and more expensive to support and extend a large set of patterns.
Snippets Optimizer algorithm
Optimizer consists of three subunits and two are major units: one is performing data flow optimization, and one is focused on control flow,
Data flow optimizer
- Inserts utility operations to make the dataflow explicit and suitable for further optimizations and code generation.
- Replaces some Ops to allow for generation of amore efficient code
IR converts
- Convert from data-flow-oriented representation(nGraph IR) to control-flow-focused IR (Linear IR).
Control flow optimizer
- Common pipeline, auto matic loop injection and loop optimizations
- Buffer pipeline, managing buffer identify and allocate
- Final pipeline, connect Generator modules and release redundant resources.
Case study: MHA subgraph OpenVINO optimization
In this chapter, we take the Bert model as the object of explanation, automatically download and convert the model through the open model zoo, use the Netron tool to view the topology of the model, use the benchmark_app to test the model and save the exec graph of the model, or manually The way to adjust the parameter is to turn on and off the optimization to compare the impact of the MHA operator optimization on the OpenVINO IR model.
First of all, you need to make sure that openvino and openvino-dev packages have been installed. I won’t go into details here. If you don’t know how to install the environment, you can refer to the previous blog content.
Step 1. Models prepare and model convert
Open Model Zoo is a useful toolkit which include model downloader, model converter, model quantization etc. to easily enable model by OpenVINO™,
Using following commend-line (cmd) to download “bert-base-ner” original model by omz_downloader
bert-base-ner is a fine-tuned BERT model that is ready to use for Named Entity Recognition and achieves state-of-the-art performance for the NER task.
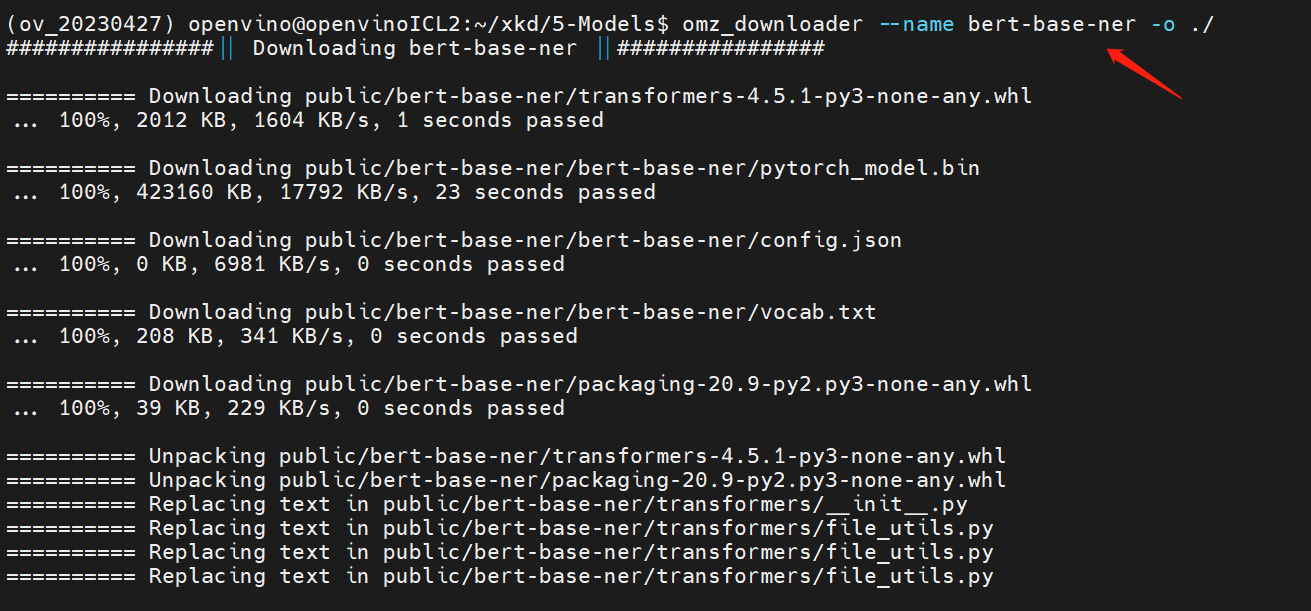
Using following commend-line (cmd) to auto convert “bert-base-ner” original model to OpenVINO™ IR model by omz_converter
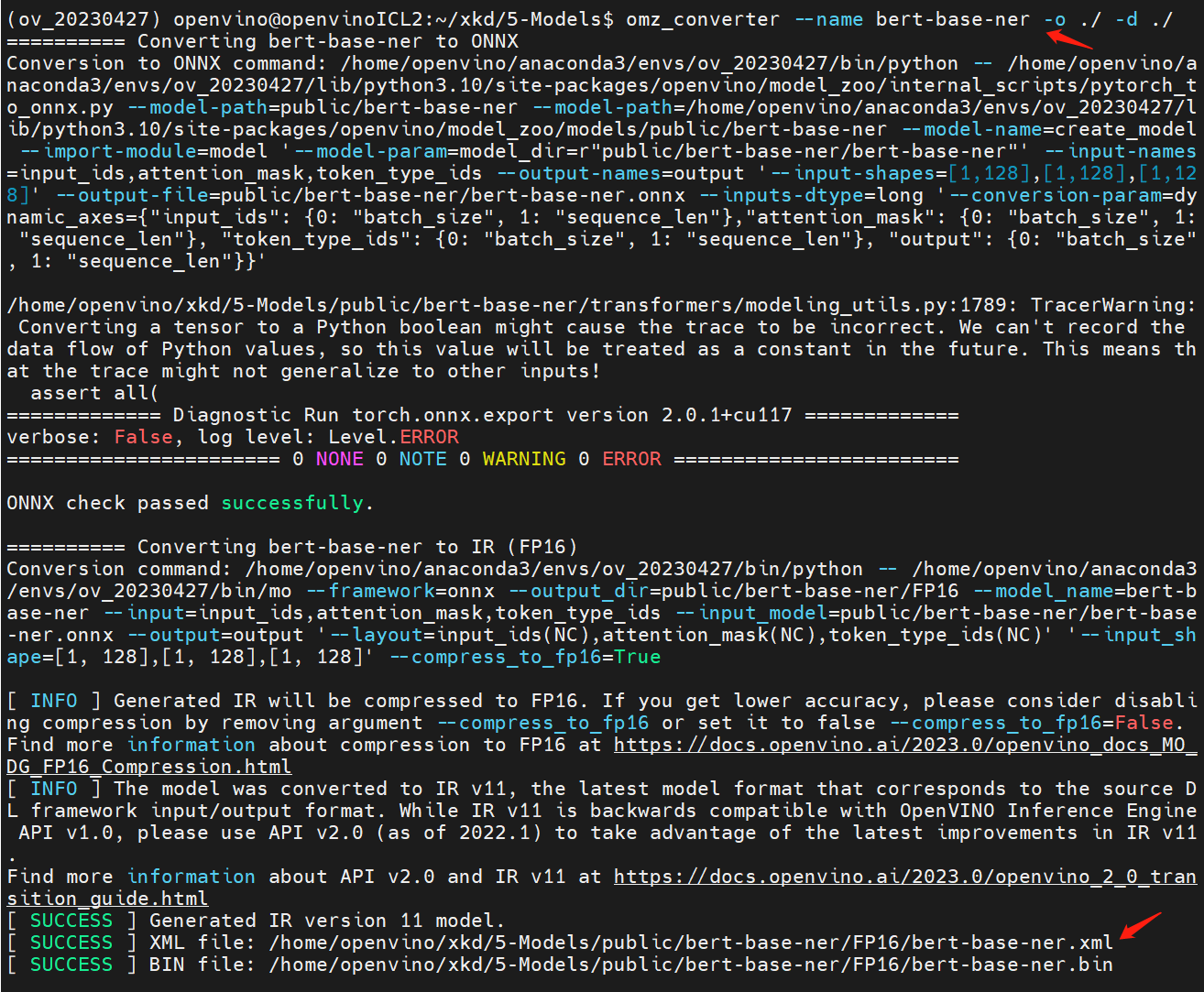
Now, we get the “bert-base-ner” IR model , and we can use benchmark_app to evaluate it on our device.
Step 2. Check model exec-graph
OpenVINO™ benchmark_app is a versatile tool, it can evaluate model’s performance ,analysis model hotspot operate, and also can help us to analysis to model’s topology graph. IR save the topology graph in .xml file, but this graph is not including all optimization graph, so that we can save the execution graph to check the runtime graph on target device.
The exec-graph will save as “bert-base-ner-exec.xml”, and use Netron to check the original IR graph and the execution IR graph
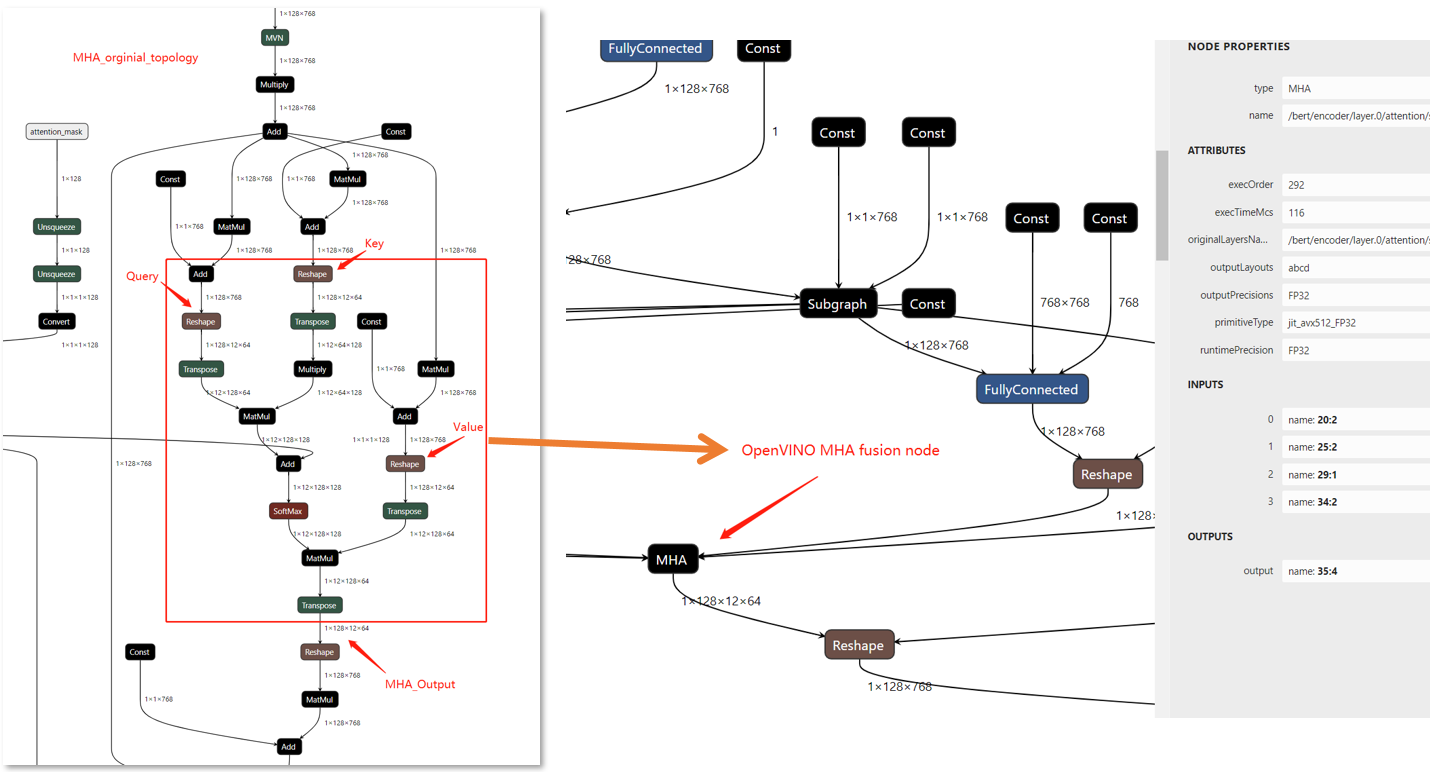
In the compare figure, we can find that the MHA subgraph as been optimize as a fusion graph named MHA, but there is only a single node, If we want to check the fusion node inside we should add some config in OpenVINO to show the detail information about it.
So that, we can simply insert below serialization code
after code line https://github.com/openvinotoolkit/openvino/blob/master/src/plugins/intel_cpu/src/nodes/subgraph.cpp#L81
which will dump all subgraphs topology with it's friendly name in execution graph.
Now, re-build OpenVINO™ from source code and save the execution graph we will find the subgraph include the parameter “originalLayersName” which means that which layers are fusion in MHA subgraph.
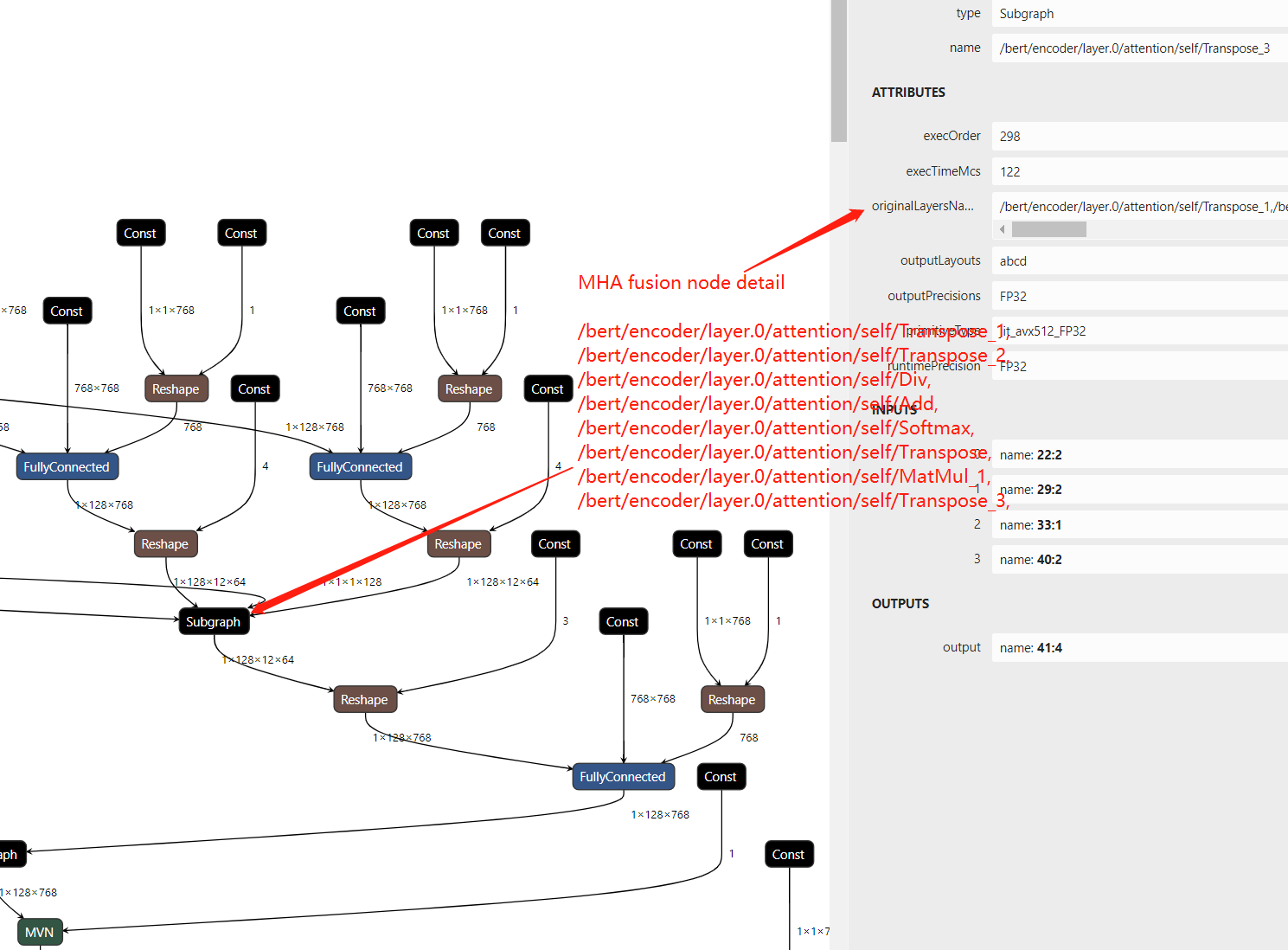
Step 3. Close Snippets optimization
Snippets as an automate optimization method which default open at every time. And if you don’t want to use automatic method and replace by any custom algometric, Snippets can be open/close by config in the model compile process, so that we can change the Snippets config key by “KEY_SNIPPETS_MODE” for expected values parameter “ENABLE(default) / DISABLE / IGNORE_CALLBACK”.
In benchmark_app case we should edit a config .json file to save the ov::config
And then use the config file by “-load_config” parameter to run benchmark_app and save a exec-graph, we will find the MHA fusion node is deconstruct.
Now open the new execution graph we can find the transformation optimized MHA fusion node has remove.
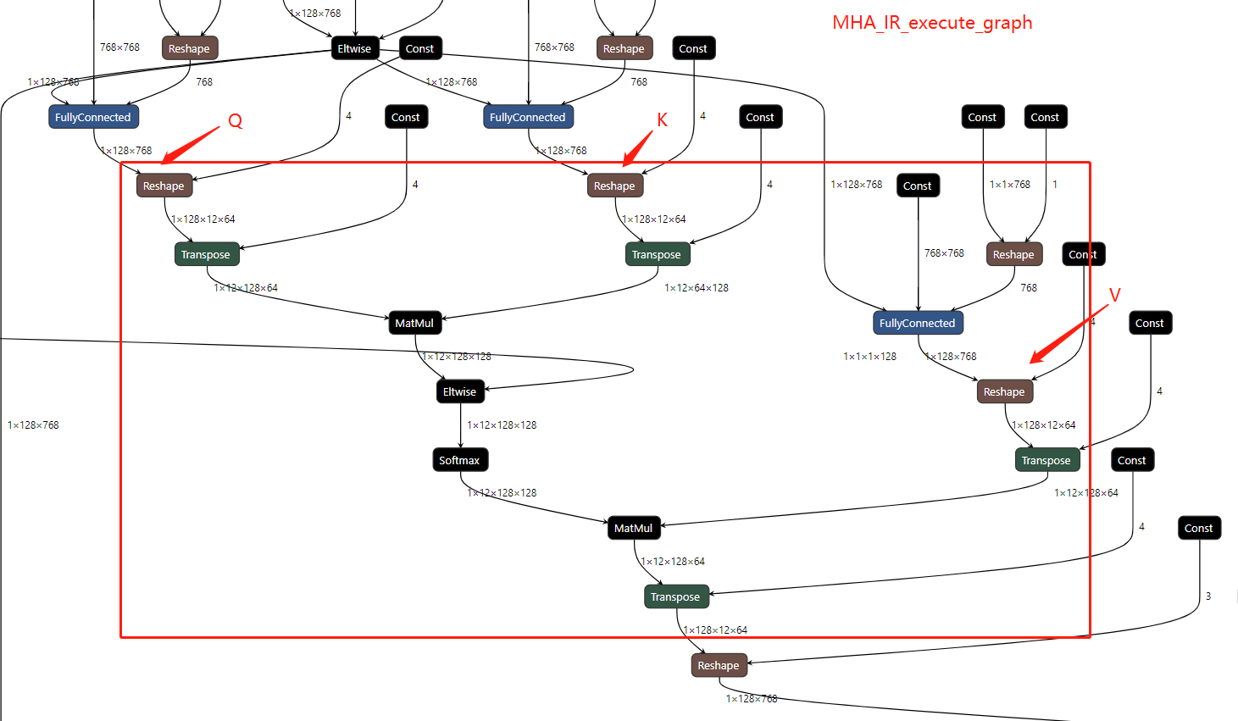
Conclusion
In this blog, we show MHA subgraph fusion optimization by OpenVINO™ , highlight to newfeature Snippets in transformations and introduce the MHA fusion node optimization ideas in terms of CPU memory-bounded.
Please note, this optimization idea can be used on likely transformer structure models by OpenVINO™. But whether the above MHA fusion node will be used it need to analysis case-by-case.
We will continue to optimize performance along with upgrading OpenVINO™ for model scaling such as Bert-base , GPT and any others LLM to get latest efficient support with OpenVINO™ backend.
Reference
OpenVINO™ MHA fusion node
OpenVINO™ Snippets Design Guide
[Paper] FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
[Paper] AttentionIs All You Need