
.png)
Alexander Nesterov, Dmitry
Gorokhov
OpenVINO toolkit for ARM platforms overview
OpenVINO, an advanced framework for neural network inference, has expanded its capabilities to include support for ARM architecture. Leveraging the streamlined and lightweight design of ARM processors, OpenVINO boosts its efficiency in AI tasks, which in turn widens application possibilities. To ensure a flawless experience within the OpenVINO ecosystem, the toolkit's CPU plugin has been refined for ARM architecture, focusing on improved performance and memory optimization, particularly for AI workloads running on ARM processors.
This article describes the ARM component within the CPU plugin, outlines the initiatives to back the development effort, and explains how it relates to the concept of OpenVINO toolkit. This article serves as an introduction and the first in a series of articles on ARM architecture support in OpenVINO.
ARM integrations in OpenVINO toolkit
Introduction to the ARM Integration within the OpenVINO CPU Plugin
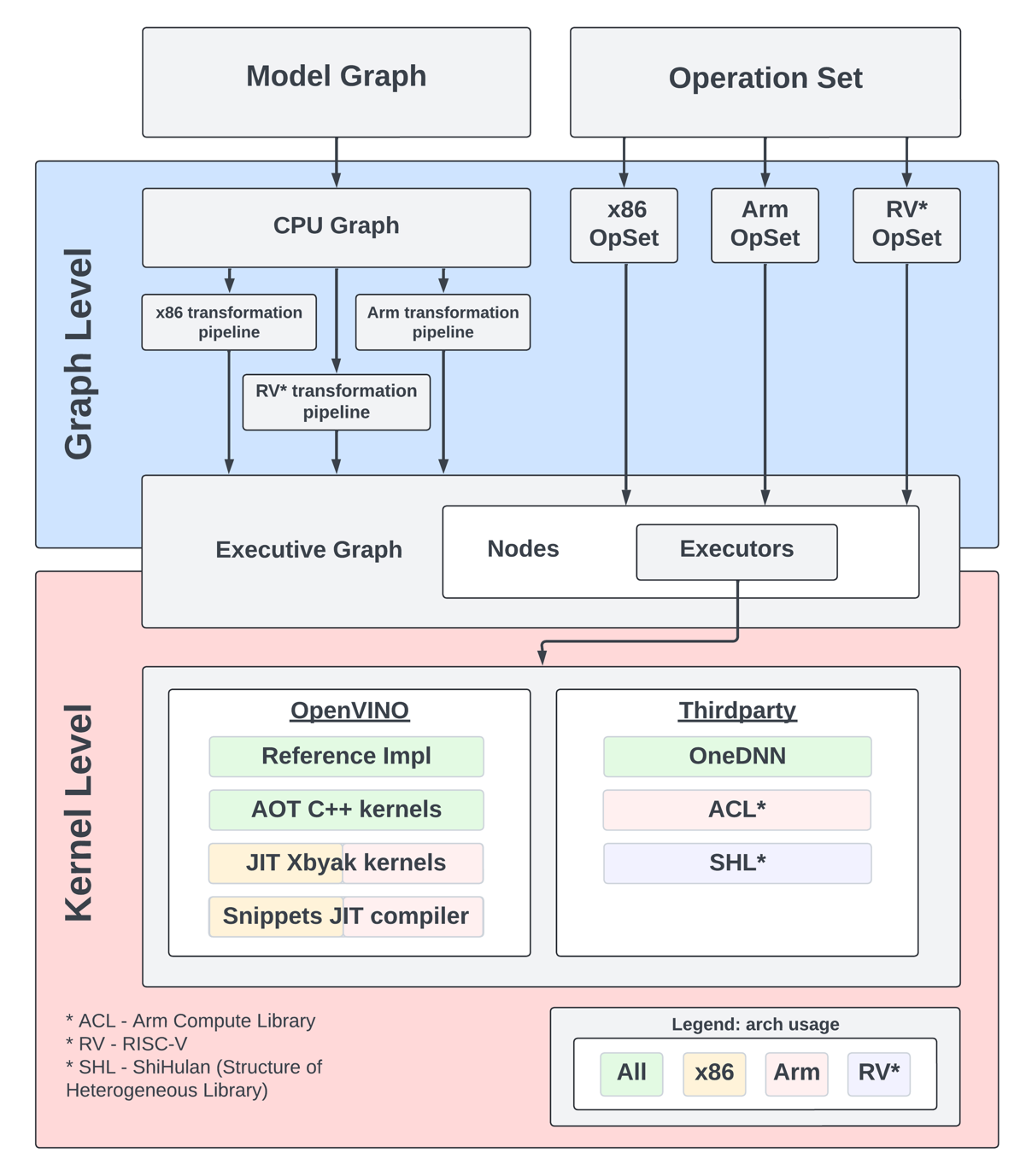
The OpenVINO CPU plugin was selected as the base for ARM architecture because of operational and architectural similarities between ARM and x86 platforms.
The OpenVINO CPU plugin architecture is divided into two main parts: the graph level and the execution kernel level, as shown in Diagram 1. The graph level involves optimizing the base graph of the AI model and converting it into an internal representation, using information about the processor architecture, computation specifics, algorithm characteristics, and more. The kernel level contains a set of computational kernels packaged into executors for various platforms. This set of computational kernels is divided into two main groups: kernels implemented directly within OpenVINO, and kernels utilized from third-party libraries. These groups help to select the optimal solutions for all supported architectures.
It is important to highlight that OpenVINO includes a special optimization layer called graph transformations. The main goal of this layer is to optimize the computation of the model graph on the processor, as well as to determine the order of processing and execution of graph nodes (or to eliminate some nodes from computations). Additionally, this layer has two significant aspects. The wide set of general transformations helps the plugin adjust to new architectures and keeps the computation graph well-suited for each specific type, like x86 or ARM. Balancing between general and specific optimizations, this approach is a crucial part of processing the model graph before execution by the kernels.
Generic Approaches for Device-Specific Optimizations in the CPU Plugin:
The CPU plugin incorporates three primary approaches to enable efficient, device-specific optimizations. These approaches are fully adopted for ARM architecture:
- Compiler Approach (Snippets)
- Integration ofOpenVINO Graph Compiler(known as Snippets)
The CPU plugin integrates Snippets to optimize performance by identifying and reusing common patterns within the execution graph. This approach enhances computational efficiency and ensures adaptability across different tasks.
- Integration ofOpenVINO Graph Compiler(known as Snippets)
- OpenVINO internal kernels (JIT + AOT):
- JIT (Xbyak): The CPU plugin employs JIT-compiled kernels using Xbyak to dynamically generate optimized code at runtime.
- AOT (Optimal Reference Implementation): Precompiled kernels developed within the OpenVINO framework provide efficient, reusable solutions for computational tasks.
- Third-Party Libraries
The CPU plugin leverages third-party libraries to access pre-optimized kernels for ARM:- Direct Use ofARM Compute Library(ACL) Kernels:
By directly using kernels from the ARM Compute Library (ACL), the plugin exploits the library’s inherent advantages for ARM-based computations. - Accessing ACL Kernels viaOneDNN:
The plugin accesses and optimizes ACL kernels through OneDNN, ensuring comprehensive coverage of ACL’s capabilities. - Accessing Other ARM-Optimized Kernels via OneDNN:
Beyond ACL, the plugin supports additional ARM-optimized kernels available through OneDNN, enabling broader model compatibility.
- Direct Use ofARM Compute Library(ACL) Kernels:
It is also important to address the topic of parallelism. In the context of OpenVINO, there are two levels of parallelism: graph-level parallelism and kernel-level parallelism. This approach enables optimal distribution of the processor load and maximizes the use of computational resources. Due to its complexity, a custom interface for parallelism is necessary, which incorporates particular libraries and standards for parallel computing. For ARM architecture support in OpenVINO, the current parallelism approach employs the OpenMP standard or the OneTBB library. OpenVINO uses OneTBB as the default threading backend, offering scalability and efficient task scheduling for high-performance applications. For users who prefer OpenMP, OpenVINO can be recompiled from source to enable OpenMP support. This flexibility allows developers to tailor threading options to specific project needs.For users who prefer OpenMP, OpenVINO can be recompiled from source to enable OpenMP support. This flexibility allows developers to tailor threading options to specific project needs.
Additionally, it is useful to briefly explain the role of external third-party libraries in OpenVINO.
To gain a deeper understanding of the context, we will discuss key libraries such as ARM Compute Library and OneDNN. These libraries are crucial for enhancing performance and reducing memory consumption in the OpenVINO CPU plugin for ARM architecture.
Arm Compute Library
The Arm Compute Library is an open-source collection of software optimized for Cortex-A CPUs, Neoverse systems, and Mali GPUs. It offers superior performance compared to other open-source alternatives and rapidly integrates new Arm technologies like SVE2. Key features include over 100 machine learning functions for CPU and GPU, support for multiple convolution algorithms (GEMM, Winograd, FFT, Direct), and various data types (FP32, FP16, int8, uint8, BFloat16). The library provides micro-architecture optimizations for key ML primitives, highly configurable build options for lightweight binaries, and advanced techniques such as Kernel Fusion, Fast math, and texture utilization. Additionally, it supports device and workload-specific tuning with OpenCL tuner and GEMM-optimized heuristics.
OneDNN Library
Intel® oneAPI Deep Neural Network Library (oneDNN) provides highly optimized implementations for deep learning operations across CPUs, GPUs, and other hardware. Its unified API improves performance for frameworks such as OpenVINO, Intel AI Tools, PyTorch*, and TensorFlow*, streamlining development and deployment processes by eliminating the need for target-specific code.
This library is fundamental to OpenVINO as it is crucial for optimizing neural network inference on Intel processors. It has drawn interest for supporting various computational architectures, made possible by the developer community and the accessibility of its source code. For instance, the ARM Compute Library is used for ARM architectures, along with JIT kernels integrated by Fujitsu. This variety enables achieving optimal performance on ARM architectures.
OpenVINO Distribution
The OpenVINO™ Runtime distribution for ARM devices provides various easy installation options. You can install OpenVINO via an archive file, use Python's PyPI, Conda Forge, Homebrew for macOS, Microsoft's vcpkg package manager, or Conan Package Manager. Detailed instructions are provided for each method to help you through the setup.
OpenVINO Notebooks
OpenVINO notebooks provide tutorials and step-by-step guides for various deep learning tasks. They cover a range of topics from setup process to model optimization and deployment. The notebooks are useful for learners at all levels, providing clear explanations and examples to help you learn OpenVINO.
The demos below demonstrate several notebooks running locally on Apple Mac M1 Pro Laptop and Apple Mac M2 Studio with OpenVINO™ 2025.0 release.
The Phi-3 Vision model is used for multimodal tasks, combining text and image processing. It can generate image descriptions, answer questions based on visual content, extract and analyze text from images, classify objects and scenes, and assist in content moderation.
https://drive.google.com/file/d/1-deK-heXq9B-iu4kAIO3ty8mDxLE3cnx/view?usp=sharing
Stable Diffusion 3 is a next-gen diffusion model using MMDiT, offering superior image quality, typography, and prompt adherence with improved efficiency.
https://drive.google.com/file/d/1HDB_d8sTkvqAstoq39QzufCF3rvYYjjJ/view?usp=sharing
Yolo-v11 object detection example
YOLOv11 is a fast and efficient real-time object detection model with improved accuracy and optimized architecture. It supports tasks like detection, segmentation, and classification while being adaptable to various platforms.
https://drive.google.com/file/d/1ISlBEAQWpyiEvFo6aRDBlQcfnf0l-V3R/view?usp=sharing
Collaborating with the Open-source Community
Good First Issue tasks
Developers eager to help improve OpenVINO can start by tackling "good first issue" tickets for ARM devices, which are a helpful way to enhance OpenVINO's performance on ARM architectures.
Contributing to the development of the OpenVINO plugin for ARM devices involves optimizing performance, aligning with ARM's features, and tackling platform-specific challenges. The open-source community is actively working on the plugin, taking on advanced tasks like implementation of highly optimized JIT kernels.
Google Summer of Code
Last year, our team joined the Google Summer of Code with a project aimed at boosting the performance of Generative AI (GenAI) on ARM devices using the OpenVINO toolkit.
The project focused on decreasing latency, accelerating model compilation, and reducing memory consumption. It entailed creating a benchmarking system and using advanced optimization methods for ARM architectures in the OpenVINO ecosystem. This work was important for OpenVINO's growth as an open-source framework.
Conclusion
In summary, using the OpenVINO CPU plugin on ARM devices can significantly improve computational efficiency and accelerate inference tasks. Its optimization techniques and compatibility with ARM architectures help developers make the most of ARM-based platforms for diverse AI applications. As ARM devices become more common in different industries, OpenVINO toolkit stands out as a powerful way to get fast AI results with lower latency and power consumption. Additionally, the teamwork between Intel and the ARM community is driving new developments in AI deployment for desktops and servers.