
.png)
Su
Yang
Optimize the Post-processing of GPT2 with PPP Custom Operation
Here we provide a C++ demo about GPT2. Optimize the post-processing through the custom node of the OpenVINO PPP API, that is, insert some custom operations like TopK. Thereby reducing the latency of the pipeline.
GPT2 introduction
We use the GPT-2 model, which is a part of the Generative Pre-trained Transformer (GPT)family. GPT-2 is pre-trained on a large corpus of English text using unsupervised training. The model is available from HuggingFace. GPT-2 displays a broad set of capabilities, including the ability to generate conditional synthetic text samples of unprecedented quality, where we can prime the model with an input and have it generate a lengthy continuation.
The following image illustrates complete demo pipeline used for this scenario:
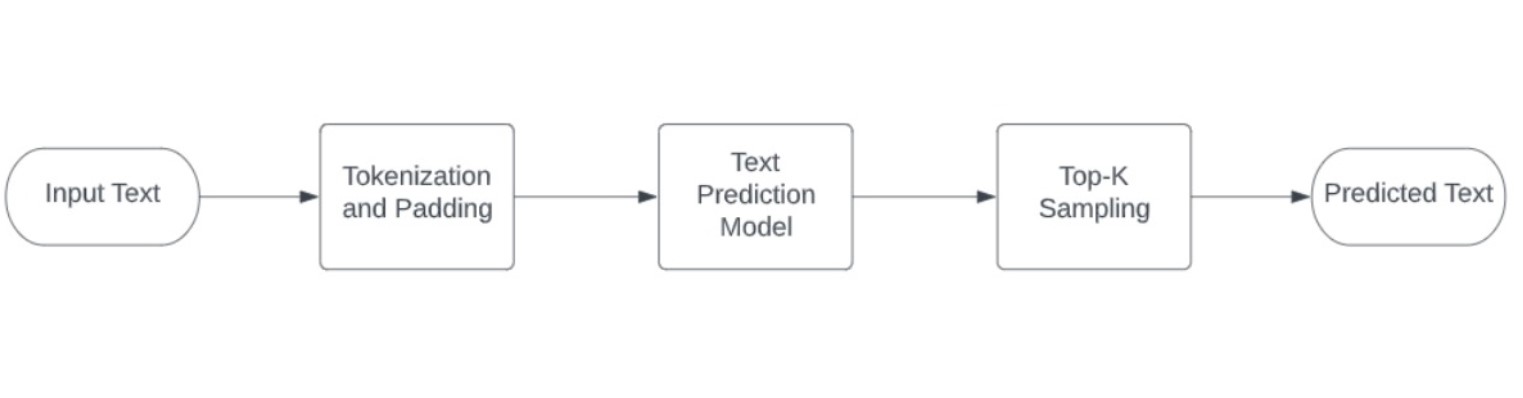
The OpenVINO notebook provide the Python implementation.
To deploy the model, we provide a C++ implementation with the post-processing optimization.
C++implementation
GPT2 Tokenizer:
The C++ implementation of the GPT2 tokenizer is from the repo gpt2-cpp.
OpenVINO Model:
The ONNX model is downloaded during the build process from the ONNX Model Zoo repo.
- Download ONNX model with Git LFS
- Use the python script to export the ONNX Model with ORT 1.10.
- The model is 634 MB large, so it may take a while to download it.
- Use python openvino-dev to convert ONNX model to OpenVINO IR model via "mo -m gpt2-lm-head-10.onnx -o IR_FP32"
OpenVINO PPP Custom Operation:
Post-processing steps can be added to model outputs. As for pre-processing, these steps will be also integrated into a graph and executed on a selected device. Compared to pre-processing, there are not as many operations needed for the post-processing stage.
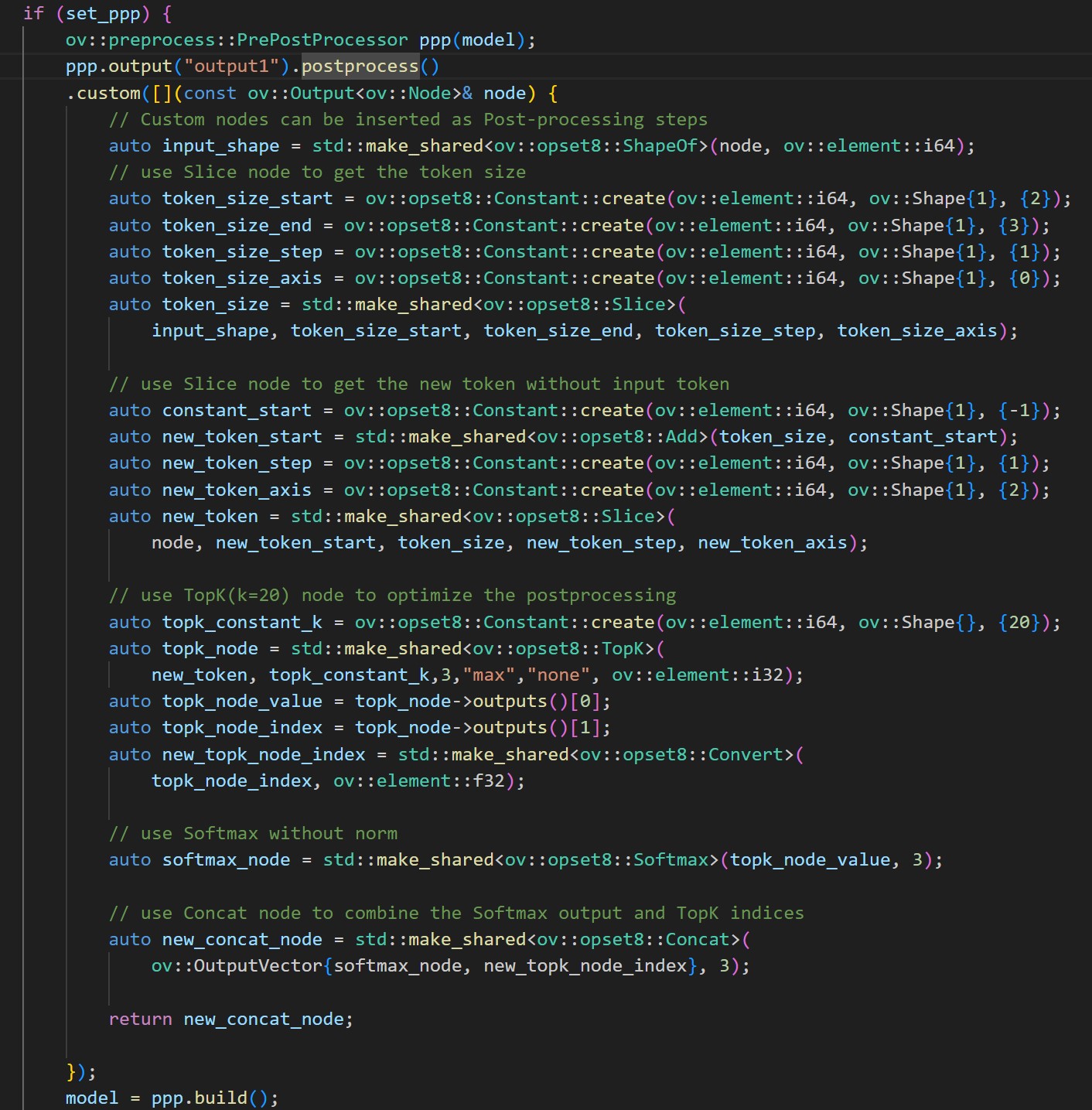
Here we use the customize operations:
1. use Slice node to get the token size
2. use Slice node to get the new token tensor without input token
3. use TopK(k=20) node to get the values and indices
4. use Softmax for TopK values
5. use Concat node to combine the Softmax output and TopK indices
The following image shows the details:
Notice:
- The Topk sampling of GPT-2 still needs a C++ post-process with probabilities distribution. It is difficult to implement this part with OpenVINO Operation of RandomUniform. .
- The PPP custom operation is verified on CPU.
Installation
Download the source code from the repo.
Prepare the OpenVINO env and modify the cmake file.
Download and convert the ONNX model.
Usage:
Run with PPP:
Run without PPP:
The optimization of PPP post-processing significantly improves the performance, which reduces the time of Intel CPU TGL by about 40% (the time of model inference plus post-processing).
The accuracy of GPT-2 C++ inference is intuitively like Python demo.