
Recommendation

Accelerate DIEN for Click-Through-Rate Prediction with OpenVINO™
Author: Xiake Sun, Cecilia Peng
Introduction
A click-through rate (CTR) prediction model is designed to estimate how likely a user will click on an advertisement or item. Deployment of a CTR model is considered one of the core tasks in e-commerce, as its performance not only affects platform revenue but also influences customers’ online shopping experience.
Deep Interest Evolution Network (DIEN) developed by Alibaba Group aims to better predict customer’s CTR to improve the effectiveness of advertisement display. DIEN proposes the following two modules:
- Temporally captures and extracts latent interests based on customer history behaviors.
- Models an evolving process of user interests using GRU with an attentional update gate (AUGRU)
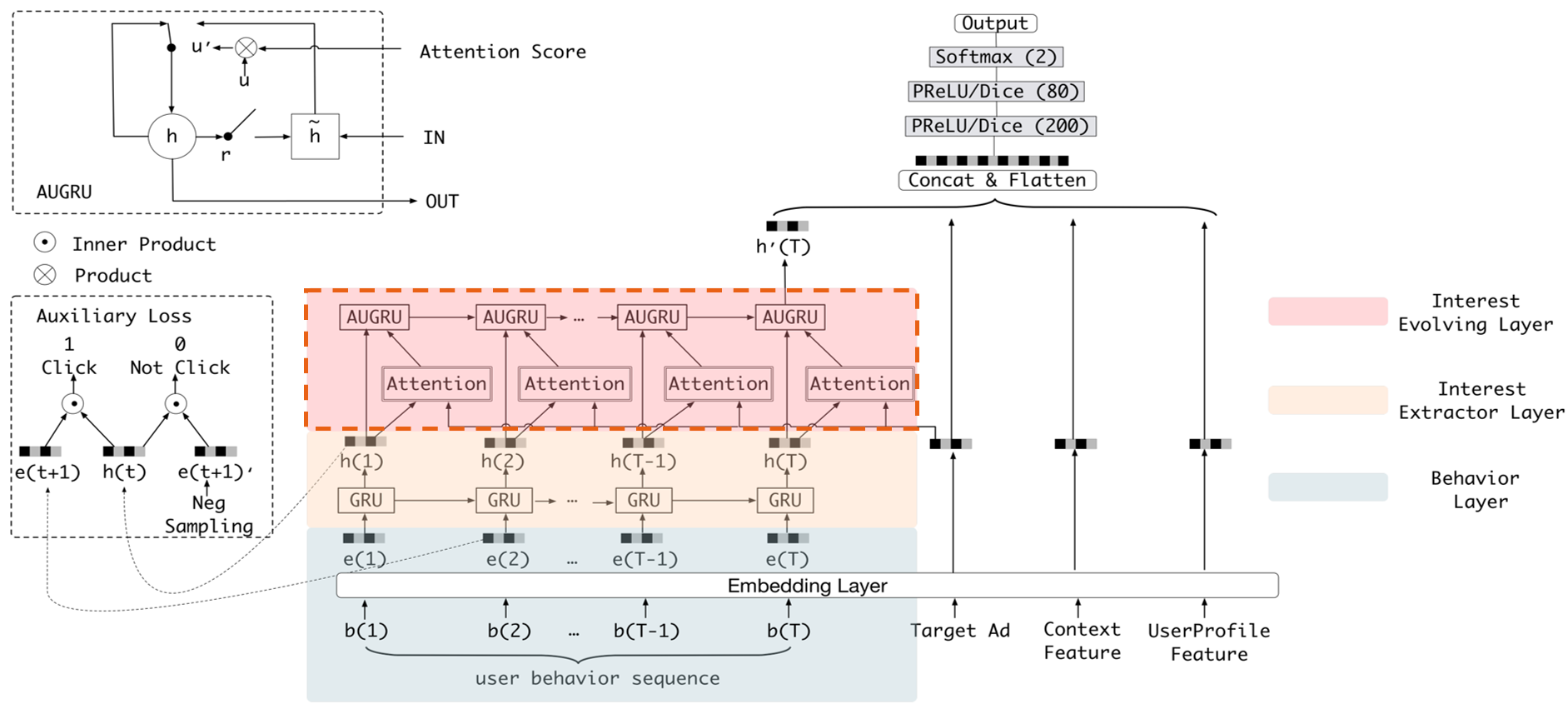
Figure 1 shows the structure of DIEN, with the help of AUGRU, DIEN can overcome the disturbance from interest drifting, which improves the performance of CTR prediction largely in online advertising system.
DIEN Optimization with OpenVINOTM
Here we introduce DIEN optimization with OpenVINOTM in two aspects: graph level and dynamism runtime optimization.
Graph Level Optimization
Figure 2 shows the AUGRU subgraph of DIEN visualized in Netron.
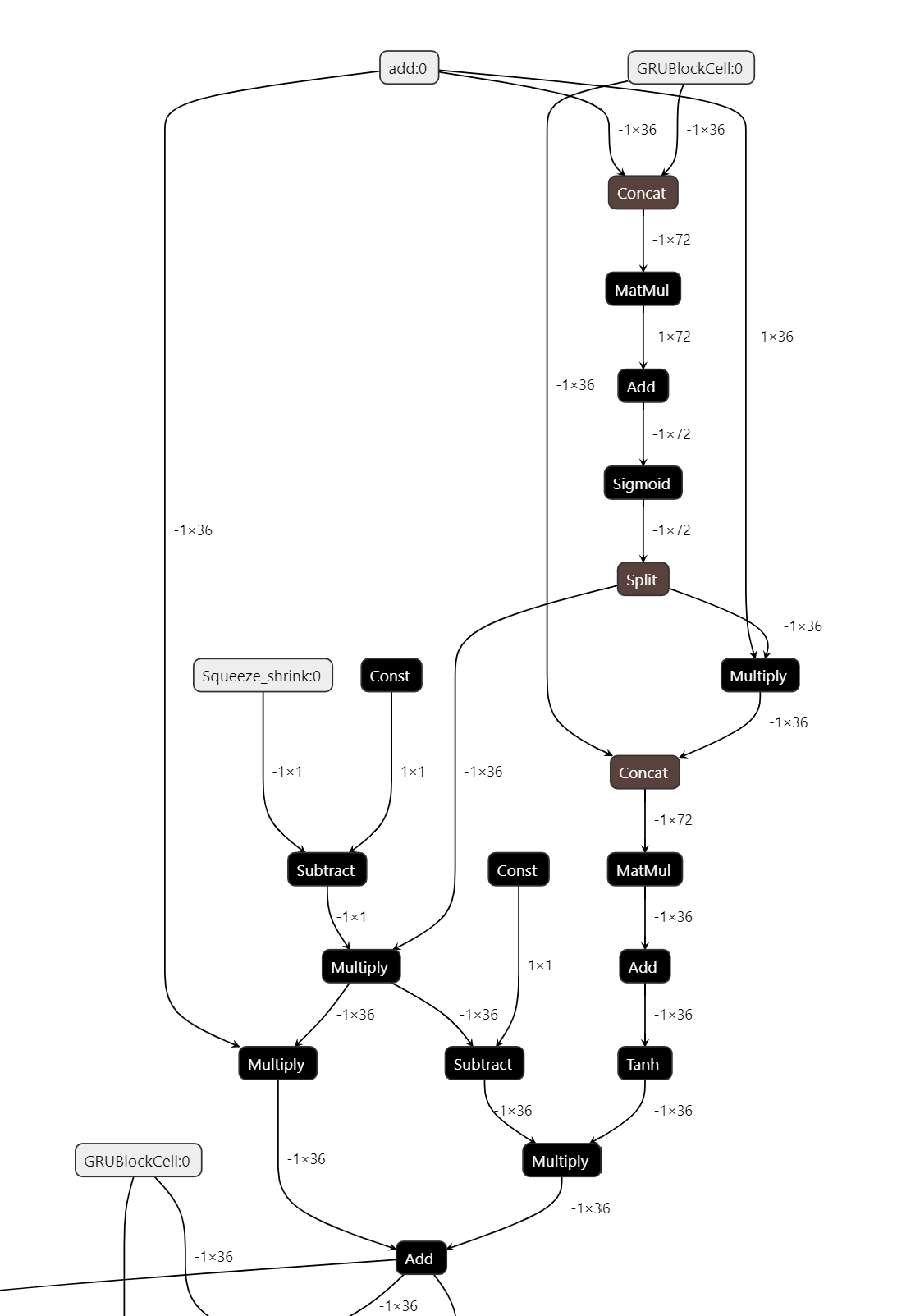
OpenVINOTM implements internal operations AUGRUCell and AUGRUSequence for better graph-level optimization. Each decomposed subgraph of GRU and AUGRU is fused into a corresponding cell operator respectively. What's more, in case of static sequence length, the group of consecutive cells are further fused into a sequence operator. In case of dynamic sequence length, however, the sequence is processed with a loop of cells due to the limitation of oneDNN RNN primitive. This loop of cells is TensorIterator and (AU)GRUCell. We will introduce the optimizations of TensorIterator in next session.
TensorIterator Runtime Optimization with Dynamic Shape
Before we dive into optimization details, let’s first checkout how OpenVINOTM TensorIterator operation works.
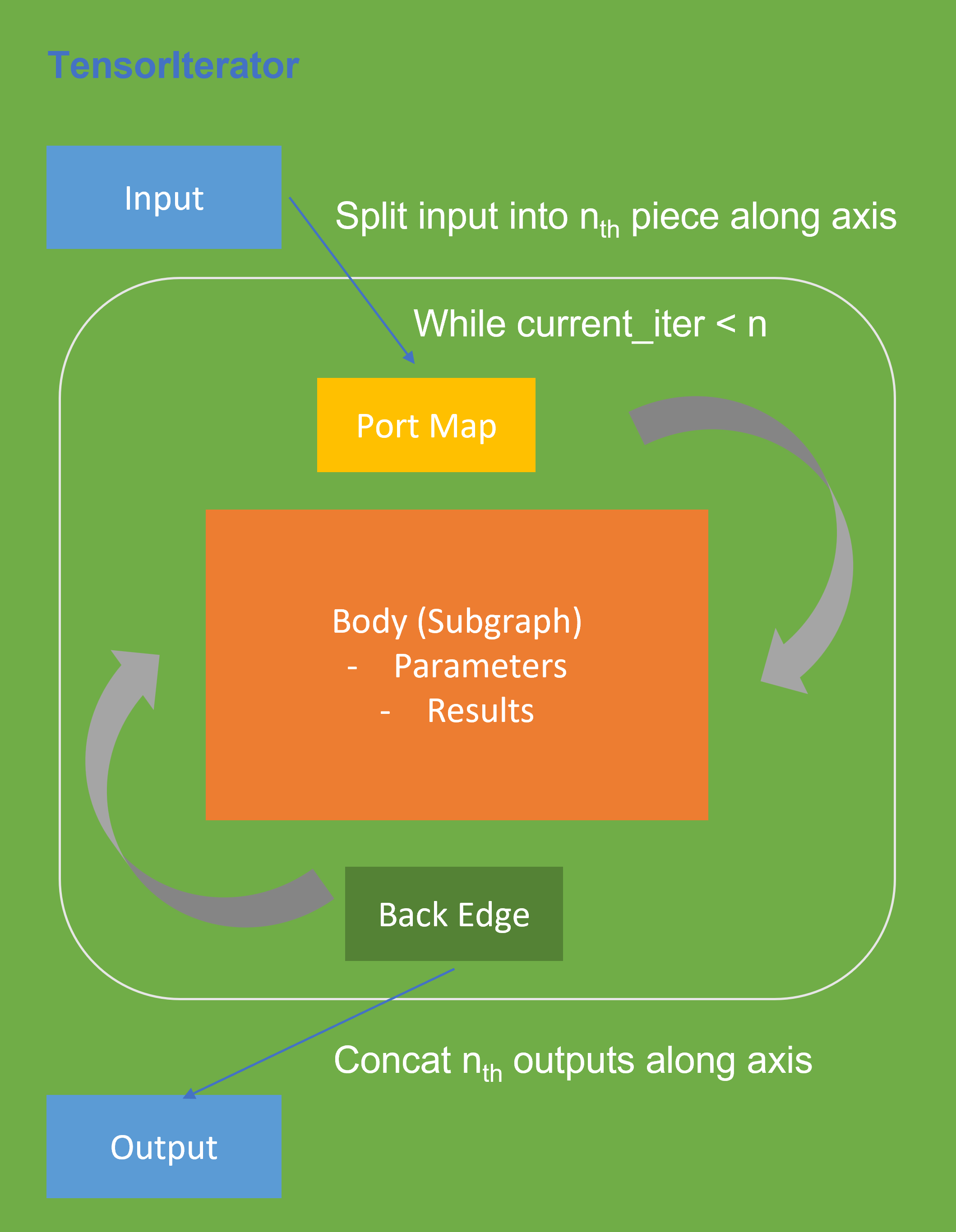
The TensorIterator layer performs recurrent execution of thenetwork, which is described in the body, iterating through the data. Figure 3 shows the workflow of OpenVINOTM Operation TensorIterator in a simplified view. For details, please refer to the specification.
Similar to other layers, TensorIterator has regular sections: input and output. It allows connecting TensorIterator to the rest of the IR. TensorIterator also has several special sections: body, port_map, back_edges. The principles of their work are described below.
- body is a network that will be recurrently executed. The network is described layer by layer as a typical IR network.
- port_map is a set of rules to map input or output data tensors of TensorIterator layer onto body data tensors. The port_map entries can be input and output. Each entry describes a corresponding mapping rule.
- back_edges is a set of rules to transfer tensor values from body outputs at one iteration to body parameters at the next iteration. Back edge connects some Result layers in body to Parameter layer in the same body.
If output entry in the Port map doesn’t have partitioning (axis, begin, end, strides) attributes, then the final value of output of TensorIterator is the value of Result node from the last iteration. Otherwise, the final value of output of TensorIterator is a concatenation of tensors in the Result node for all body iterations.
We use Intel® VTune™ Profiler to run benchmark_app with DIEN FP32 IR model on Intel® Xeon® Gold 6252N Processor for performance profiling.
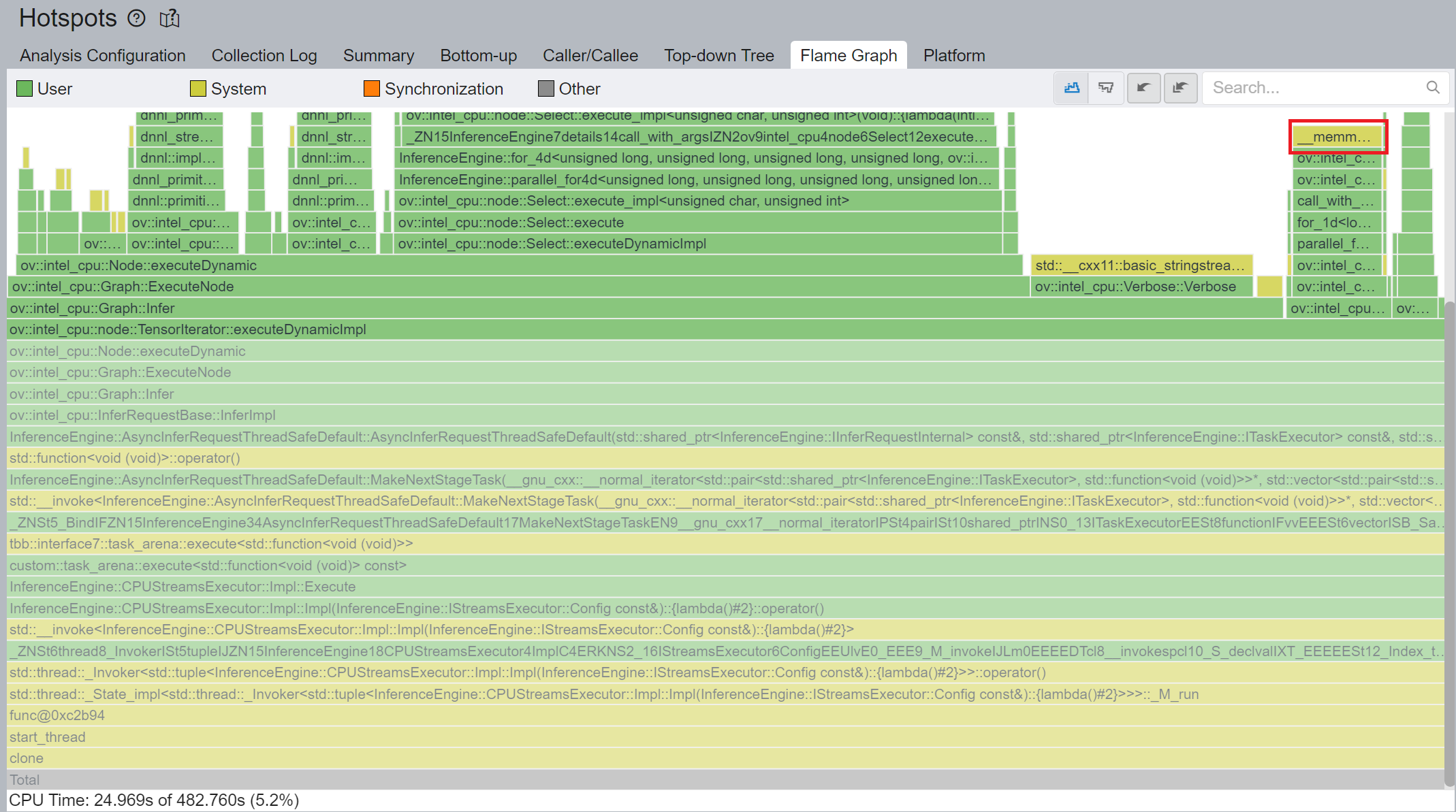
Cache internal reorder primitives in TensorIterator
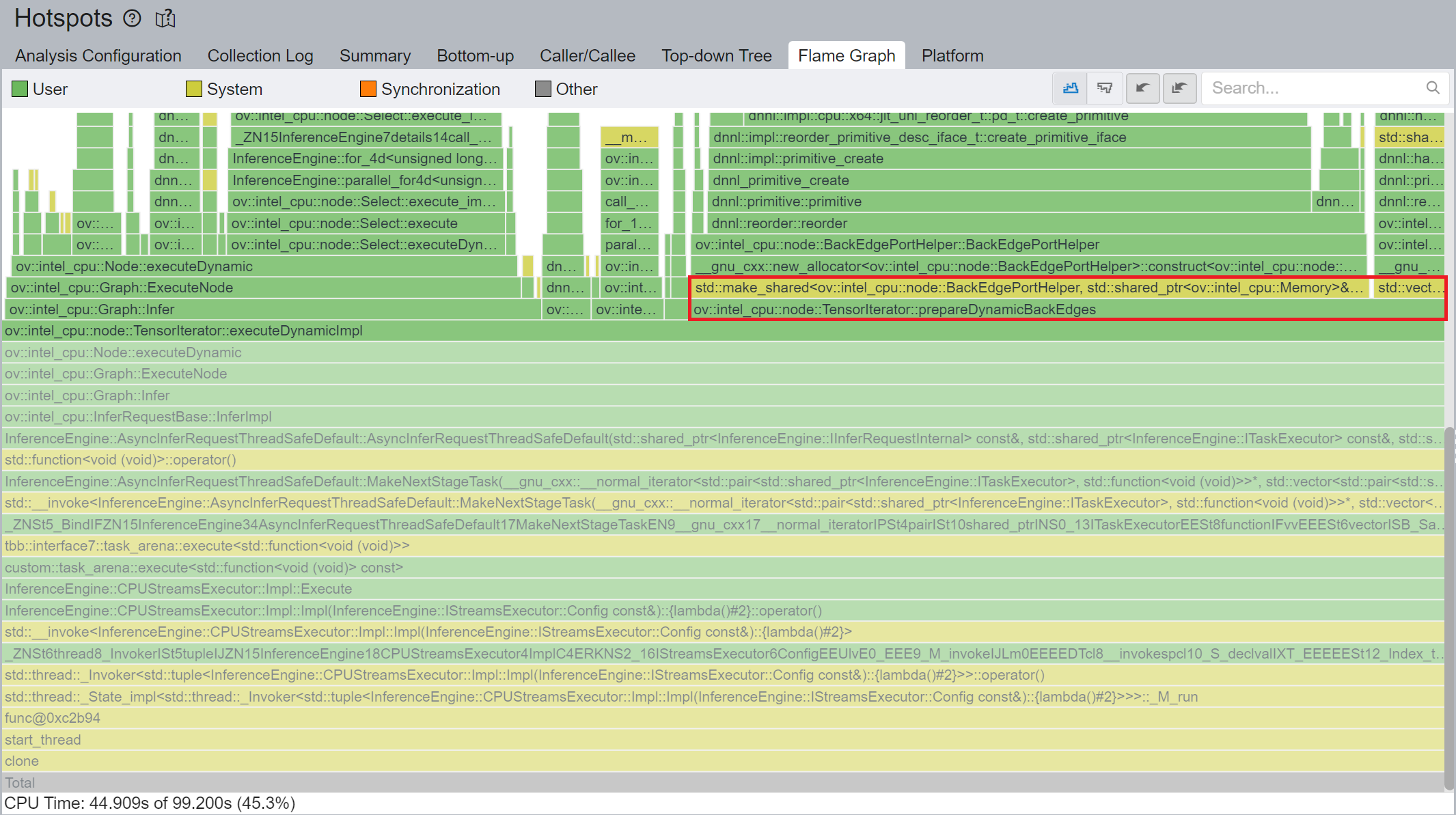
Figure 4 shows that TensorIterator::prepareDynamicBackEdges() spends nearly 45% CPU time to create the reorder primitives. DIEN FP32 model has 2 TensorIterator, eachTensorIterator runs 100 iterations in body with the same input/output shape regarding the current batch. Besides, each TensorIterator has 7 back edges, which means the reorder primitive are frequently created.
So, we propose to cache internal reorder primitive in TensorIterator to optimize back edge memory copy logic. With this optimization, the performance with dynamic shape can be improved by 8x times.
Memory allocation and reuse optimization in TensorIterator
As Figure 3 shows, if we have split input as nth piece to loop in body, at the end, the outputs of TensorIterator will be a concatenation of tensors in the Result node for all body iterations, which can lead to performance overhead. Based on previous optimization we re-run performance profiling using benchmark_app with DIEN FP32 IR model on Intel® Xeon® Gold 6252N Processor as showed in Figure 5.
CPU plugin TensorIterator supports both two operators - TensorIterator and Loop. The outputs of each iteration could be concatenated and return to users. Since the output size is not always known before the execution, the legacy implementation is to dynamically allocate the concatenated output buffer.
We propose two points from the memory allocation standpoint:
- In the case of TensorIterator number of iterations is determined by the size of the axis we are slicing. So, if TensorIterator body one ach iteration will produce the same shape on output we can easily preallocate enough memory before the TI computation, The same for Loop with trip count input - we can just read the value from this input, make shape inference for the body and this determines the required amount of memory.
- More complicated story is when we don't know exact number of iterations before Loop inference (e.g., number of iterations is determined by ExecutionCondition input). In that case do the following: let’s have an output buffer where we put the Loop output. Once the buffer doesn't have enough space, we reallocate it on new size based on a simple and effective dynamic array algorithm.
OpenVINOTM implemented memory allocation and reuse optimization in TensorIterator to significantly reduce the number of reallocations and not to allocate to much memory at the same time. Experiments show that performance can be further improved by more than 20%.
DIEN OpenVINOTM Demo
Clone demo repository:
Prepare Amazon dataset:
Setup Python Environment:
Convert original TensorFlow model to OpenVINOTM FP32 IR:
Run the Benchmark with TensorFlow backend:
Run the Benchmark with OpenVINOTM backend using FP32 inference precision:
Run the Benchmark with OpenVINOTM backend using BF16 inference precision:
Please note, Xeon native supports BF16 infer precision since 4th Generation Intel® Xeon® Scalable Processors. Running BF16 on a legacy Xeon platform may lead to performance degradation.
Conclusion
In this blog, we introduce inference optimization of DIEN recommendation model with OpenVINOTM runtime as follows:
- For static input sequence length, AUGRU subgraph will be decomposed and fused as AUGRU and AUGRUSequence OpenVINOTM internal operation.
- For dynamic input sequence length, we propose cache internal reorder primitives and memory allocation and re-use optimization in TensorIterator.
- Provide a demo for model enabling and efficient inference of DIEN with OpenVINOTM runtime.
Reference
Deep Interest Evolution Network (DIEN)