.png)
Alexander
Kozlov
December 20, 2022
Q2'22: Technology update – low precision and model optimization
Authors
Alexander Kozlov, Alexander Suslov, Pablo Munoz, Vui Seng Chua, Nikolay Lyalyushkin, Yury Gorbachev, Nilesh Jain
Summary
This quarter we observed an increased interest in pruning methods for Transformer-based architectures (BERT, etc.). The main reason for that, as we see it, is a huge success of this architecture in many domains such as NLP, Computer Vision, Speech and Audio processing. NAS methods continue beating handcrafted models on various tasks and benchmarks. As usual, DL model optimization is still a huge area with lots of people involved both from academia and industry.
Papers with notable results
Quantization
- Differentiable Model Compression via Pseudo Quantization Noise by Facebook AI Research (https://arxiv.org/pdf/2104.09987v1.pdf).In this paper, authors propose a DIFFQ method that uses a pseudo quantization noise to approximate quantization at train time, as a differentiable alternative to STE, both with respect to the unquantized weights and number of bits used. With a single penalty level λ, DIFFQ optimizes the number of bits per weight or group of weights to achieve a given trade-off between model size and accuracy. The method outperforms a regular QAT method at a low-bit quantization on different tasks.
- Do All MobileNets Quantize Poorly? Gaining Insights into the Effect of Quantization on Depthwise Separable Convolutional Networks Through the Eyes of Multi-scale Distributional Dynamics by Waterloo Artificial Intelligence Institute (https://arxiv.org/pdf/2104.11849v1.pdf).Authors investigate the impact of quantization on the weight and activation distributional dynamics as information propagates from layer to layer, as well as overall changes in distributional dynamics at the network level. This fine-grained analysis revealed significant dynamic range fluctuations and a “distributional mismatch” between channel wise and layer wise distributions in depth-wise CNNs such as MobileNet that lead to increasing quantized degradation and distributional shift during information propagation. Furthermore, analysis of the activation quantization errors shows that there is greater quantization error accumulation in depth-wise CNNs compared to regular CNNs.
- TENT: Efficient Quantization of Neural Networks on the tiny Edge with Tapered Fixed Point by Neuromorphic AI Lab, University of Texas (https://arxiv.org/pdf/2104.02233v1.pdf).An interesting read for those who are not aware of taper and posit numerical formats. Authors propose a tapered fixed-point quantization algorithm that adapts the numerical format to best represent the layer wise dynamic range and distribution of parameters within a Tiny ML model. They do not provide extensive results but show a superior performance vs. Vanilla fixed-point quantization.
- n-hot: Efficient Bit-Level Sparsity for Powers-of-Two Neural Network Quantization by Sony (https://arxiv.org/pdf/2103.11704v1.pdf).One more method for power-of-two quantization as an alternative to APoT method which also allows reducing the model size. The method uses bit-level sparsity and introduces subtraction of PoT terms. It also applies two-stage long fine-tuning during quantization. This helps to achieve superior results vs. vanilla PoT and APoT methods.
- Network Quantization with Element-wise Gradient Scaling by Yonsei University (https://arxiv.org/pdf/2104.00903v1.pdf).This paper proposes an element-wise gradient scaling (EWGS), a simple alternative to the STE, training a quantized network better than the STE in terms of stability and accuracy. Given a gradient of the discretizer output, EWGS adaptively scales up or down each gradient element, and uses the scaled gradient as the one for the discretizer input to train quantized networks via backpropagation. The method achieves very promising results on CIFAR and ImageNet dataset in low-bit quantization setup (1-2 bits).
- Q-ASR: Integer-only Zero-shot Quantization for Efficient Speech Recognition by Berkeley (https://arxiv.org/pdf/2103.16827v1.pdf).The paper about data-free quantization of the automatic speech recognition models. As usual, the authors use statistics from BatchNorm layers and backpropagation to construct a synthetic dataset. They achieve good results for QuartzNet and JasperDR model that contains BatchNorm.
- Neuro evolution-Enhanced Multi-Objective Optimization for Mixed-Precision Quantization by Intel Labs (https://arxiv.org/pdf/2106.07611v1.pdf).In this paper, authors present a framework for automated mixed-precision quantization that optimizes multiple objectives. The framework relies on Neuro evolution-Enhanced Multi-Objective Optimization (NEMO) to find Pareto optimal mixed-precision configurations for memory and bit-operations objectives. Authors also apply some tricks on top of NEMO to improve the goodness of the Pareto frontier. The method shows state-of-the-art results on several ImageNet models.
- Post-Training Sparsity-Aware Quantization by Israel Institute of Technology(https://arxiv.org/pdf/2105.11010v1.pdf).In this paper, authors propose a complicated quantization scheme that can be done post-training and leverages multiple assumptions, like bit-sparsity of weights and activations, bell-shaped distribution, many zeros in activations. Essentially, the proposed scheme picks the most significant n bits from the 8-bit value representation, while skipping leading zero-value bits. Authors also make projections on the area that requires to implement inference of such quantized models, namely for sysytolic-based architectures and Tensor Cores. They claim SOTA results, for example, for ResNet-50 on ImageNet: -0.18% relative degradation in accuracy, 2× speedup over conventional SA, and an additional 22% SA area overhead. Code is available at https://github.com/gilshm/sparq.
- On the Distribution, Sparsity, and Inference-time Quantization of Attention Values in Transformers by Stony Brook University (https://arxiv.org/pdf/2106.01335v1.pdf).A study about quantization of Transformer-based models (BERT-like). Authors focus on reducing number of bits required to represent information of attentions masks in Self-Attention block. They claim that in many cases it is possible to prune and quantize the mask (to lower bits using non-uniform quantization). The code for the analysis and data are available at https://github.com/StonyBrookNLP/spiqa.
Sparsity
- Accelerated Sparse Neural Training: A Provable and Efficient Method to Find N:M Transposable Masks by Habana and Labs (https://arxiv.org/pdf/2102.08124.pdf). The paper proposed a method to accelerate training using N:M weight sparsity with transposable-fine-grained sparsity mask where the same mask can be used for both forward and backward passes. This mask ensures that both the weight matrix and its transpose follow the same sparsity pattern; thus the matrix multiplication required for passing the error backward can also be accelerated. Experiments show 2x speed-up with no accuracy degradation over vision and language models.
- Post-training deep neural network pruning via layer-wise calibration by Intel (https://arxiv.org/abs/2104.15023v1). The paper introduces a method for accurate unstructured model pruning in the post-training scenario. The method is based on a layer-wise tuning (knowledge distillation) approach when the knowledge from the original model is distilled to the optimizing counterpart in a layer-wise fashion. Authors also propose a way of data-free accurate pruning. The method is available here.
- Carrying out CNN Channel Pruning in a White Box by Tencent and China universities (https://arxiv.org/pdf/2104.11883v1.pdf). The paper proposes a method to model the contribution of each channel to differentiating categories. The authors developed a class-wise mask for each channel, implemented in a dynamic training manner w.r.t. the input image’s category. On the basis of the learned class-wise mask, they perform a global voting mechanism to remove channels with less category discrimination. The method shows comparable results vs. other Filter Pruning criterions but it performance is worse than RL or evolutionary-based method, e.g. LeGR.
- Rethinking Network Pruning— under the Pre-train and Fine-tune Paradigm by Moffett AI (https://arxiv.org/pdf/2104.08682v1.pdf).The paper proposes a method for sparse pruning Transformer-based models. The method exploits the magnitude-based criterium to prune unimportant weights and uses knowledge distillation supervision from the original fine-tuned model. The knowledge distillation is based on MSE loss and connects multiple layers from the original model with the same layers in the pruning counterpart. The method shows good results on the tasks from GLUE benchmark: 95% of weights are pruned while preserving accuracy on most of the tasks.
- MLPruning: A Multilevel Structured Pruning Framework for Transformer-based Models by Berkeley University (https://arxiv.org/pdf/2105.14636v1.pdf). A method to optimize Transformer-based architectures (BERT) that consists of three different levels of structured pruning: 1) Head pruning for multi-head attention; 2) Row pruning for general fully-connected layers; and 3) block-wise sparsity pruning for all weight matrices. To benefit from block sparsity, authors use block-sparse MatMul kernel from Triton SW. They achieve good results on QQP/MNLI/SQuAD, with up to ~3.69xspeedup. Code is available here.
Filter Pruning
- EZCrop: Energy-Zoned Channels for Robust Output Pruning by University of Hong Kong (https://arxiv.org/pdf/2105.03679v2.pdf).The paper introduces a method to interpret channel importance metric in the spatial domain as an energy perspective in the frequency domain. It proposes a computationally efficient FFT-based metric for channel importance. The method slightly outperforms the accuracy of some recent state-of-the-art methods but more computationally efficient at the same time.
- Visual Transformer Pruning by Huawei (https://arxiv.org/pdf/2104.08500v2.pdf).The paper provides a method that identifies the impacts of channels in each layer and then executes pruning accordingly. By encouraging channel-wise sparsity in the Transformer, important channels automatically emerge. A great number of channels with small coefficients can be discarded to achieve a high pruning ratio without significantly compromising accuracy. Authors show that it is possible to prune ~40% of ViT-B/16 model while staying at ~1% of accuracy degradation on ImageNet.
- Convolutional Neural Network Pruning with Structural Redundancy Reduction by The University of Tennessee and 2Sun Yat-sen University (https://arxiv.org/pdf/2104.03438v1.pdf).The paper provides a theoretical analysis of network pruning with statistical modeling from a perspective of redundancy reduction. It also proposes a layer-adaptive channel pruning approach based on structural redundancy reduction which builds a graph for each convolutional layer of a CNN to measure the redundancy existed in each layer (a non-usual approach). The method could prune 55.1% of ResNet-50 FLOPS while staying at ~1% of accuracy drop on ImageNet.
- Model Pruning Based on Quantified Similarity of Feature Maps by University of Science and Technology Beijing (https://arxiv.org/pdf/2105.06052v1.pdf).The paper proposes a new complex criterion to prune filters from any type of convolutional operation. It uses Structural Similarity or Peak Signal to Noise Ratio to find the score of the filters. Despite the fact the paper provides results only on CIFAR dataset, the paper still interesting because it allows pruning filters without fine-tuning while preserving the accuracy. It means that this method can be potentially applied in the post-training scenario to highly redundant models.
- Greedy Layer Pruning: Decreasing Inference Time of Transformer Models by DeepOpinion(https://arxiv.org/pdf/2105.14839v1.pdf).In this paper, authors propose a method to layer pruning (GLP) is introduced to(1) outperform current state of-the-art for layer-wise pruning of Transformer-based architectures without knowledge distillation with long fine-tuning. They focus more on providing an optimization algorithm that requires a modest budget from the resource and price perspective. The method achieves good results on GLUE benchmark and requires only $300 for all 9 tasks.
- Width transfer: on the(in)variance of width optimization by Facebook(https://arxiv.org/pdf/2104.13255.pdf).This work reduces computational overhead in width optimization algorithms(MorphNet, AutoSlim, and DMCP), which in contrast to pruning, improves accuracy by reorganizing width of layers without changing FLOPS. The algorithm uniformly shrinks model's channels and depth, optimizes width on a part of a dataset with smaller images, then the optimized projected network is extrapolated to match original FLOPS and dimensions. Authors can achieve up to 320x overhead reduction without compromising the top-1. Major cons: still the additional cost of width optimization is comparable with initial training time.
Neural Architecture Search
- How Powerful are Performance Predictors in Neural Architecture Search? by Abacus.AI, Bosch and universities(https://arxiv.org/pdf/2104.01177.pdf).The first large-scale study of performance predictors by analyzing 31techniques ranging from learning curve extrapolation, to weight-sharing, supervised learning, “zero-cost” proxies. The code is available at https://github.com/automl/naslib.
- Dynamic-OFA: Runtime DNN Architecture Switching for Performance Scaling on Heterogeneous Embedded Platforms by University of Southampton (https://arxiv.org/pdf/2105.03596v2.pdf). Dynamic-OFA, extends OFA to quickly switch architecture in runtime. Sub-network architectures are sampled from OFA for both CPU and GPU at the offline stage. These architectures have different performance (e.g. latency, accuracy) and are stored in a look-up table to build a dynamic version of OFA without any additional training required. Then, at runtime, Dynamic-OFA selects and switches to optimal sub-network architectures to fit time-varying available hardware resources The approach is up to 3.5x (CPU), 2.4x (GPU) faster for similar ImageNetTop-1 accuracy, or 3.8% (CPU), 5.1% (GPU) higher accuracy at similar latency.
- RHNAS: Realizable Hardware and Neural Architecture Search by Intel Labs (https://arxiv.org/pdf/2106.09180v1.pdf). The paper introduces a NN-HW co-design method that integrates RL-based hardware optimizers with differentiable NAS. It overcomes the challenges associated with sparse validity- a failure point for existing differentiable co-design works. The authors also benchmark RL-based hardware optimizer and use Bayesian hyperparameter optimization to identify the best hyper-parameters for a fair study of a range of standard RL algorithms. The method discovers realizable NN-HW designs with 1.84×lower latency and 1.86× lower energy delay product (EDP) on ImageNet over the default hardware accelerator design.
- NAS-BERT: Task-Agnostic and Adaptive-Size BERT Compression with Neural Architecture Search by MSRA and China universities (https://arxiv.org/pdf/2105.14444v1.pdf). In this paper, authors apply NAS on the pre-training task to search for efficient lightweight NLP models, which can deliver adaptive model sizes given different requirements of memory or latency and apply for different down stream tasks. They also apply block-wise search, progressive shrinking and performance approximation to reduce the search cost and improve the search accuracy. The proposed method demonstrates comparable results on GLUE and SQuAD benchmarks.
- FNAS: Uncertainty-Aware Fast Neural Architecture Search by SenseTime (https://arxiv.org/pdf/2105.11694v3.pdf).This paper proposes FNAS method that consists of three main modules: uncertainty-aware critic, architecture knowledge pool, and architecture experience buffer, to speed up RL-based neural architecture search by ∼10×.Authors show that knowledge of neural architecture search processes can be transferred, which is utilized to improve sample efficiency of reinforcement learning agent process and training efficiency of each sampled architecture. Method shows comparable results on several CV tasks.
- Generative Adversarial Neural Architecture Search by Huawei (https://arxiv.org/pdf/2105.09356v2.pdf).Quite unusual approach to NAS based on the idea of generative adversarial training. The method iteratively fits a generator to previously discovered to architectures, thus increasingly focusing on important parts of a large search space. Authors propose an adversarial learning approach, where the generator is trained by reinforcement learning based on rewards provided by a discriminator, thus being able to explore the search space without evaluating a large number of architectures. This method can be used to improve already optimized baselines found by other NAS methods, including EfficientNet and ProxylessNAS.
- LightTrack: Finding Lightweight Neural Networks for Object Tracking via One-Shot Architecture Search by MSRA and China universities (https://arxiv.org/pdf/2104.14545v1.pdf).In this paper, authors propose a method uses neural architecture search (NAS)to design more lightweight and efficient object tracker. It can find trackers that achieve superior performance compared to handcrafted SOTA trackers while using much fewer model Flops and parameters. For example, on Snapdragon 845Adreno GPU, LightTrack runs 12× faster than Ocean, while using 13×fewer parameters and 38× fewer Flops. Code is available here.
Other Methods
- A Full-stack Accelerator Search Technique for Vision Applications by Google Brain (https://arxiv.org/pdf/2105.12842.pdf).This paper proposes a hardware accelerator search framework (FAST) that defines a broad optimization environment covering key design decisions within the hardware-software stack, including hardware data path, software scheduling, and compiler passes such as operation fusion and tensor padding. The method shows promising results on improving Perf/TDP metric when optimizing several CV workloads.
Deep Learning Software
- MLPerf Inference v1.0 has been released: https://mlcommons.org/en/news/mlperf-inference-v10/.
- Nvidia included OpenVINO in the Triton Inference Server as the CPU inference SW. See the MLPerf Inferece v1.0 in the blogpost.
- HAGO by OctoML, Amazon and Washington University (https://arxiv.org/pdf/2103.14949v1.pdf)- automated post-training quantization framework. It is built on top of TVM and provides a set of general quantization graph transformations based on a user-defined hardware specification (similar to OpenVINO POT) and implements a search mechanism to find the optimal quantization strategy.
- Archai by Microsoft (https://github.com/microsoft/archai) is a platform for Neural Network Search (NAS)that allows you to generate efficient deep networks for your applications.
Deep Learning Hardware
- Visual Search Engine by Moffett AI (https://moffett.ai/visualsearch/)-sparse processing on Xilinx FPGA
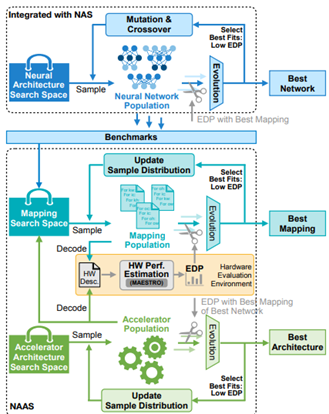
- NAAS: Neural Accelerator Architecture Search by MIT (Han Lab) (https://arxiv.org/pdf/2105.13258v1.pdf).The paper proposes a NAAS method that holistically searches the neural network architecture, accelerator architecture and compiler mapping in one optimization loop. NAAS composes highly matched architectures together with efficient mapping. As a data-driven approach, NAAS rivals the human design Eyeriss by 4.4×EDP reduction with 2.7% accuracy improvement on ImageNet under the same computation resource, and offers 1.4× to 3.5× EDP reduction than only sizing the architectural hyper-parameters.