
dGPU

Dynamic quantization support from GPU with XMX
Scope of this document
This article explains the behavior of dynamic quantization on GPUs with XMX, such as Lunar Lake, Arrow lake and discrete GPU family(Alchemist, Battlemage).
It does not cover CPUs or GPUs without XMX(such as Meteor Lake). While the dynamic quantization is supported on these platforms as well, the behavior may differ slightly.
What is dynamic quantization?
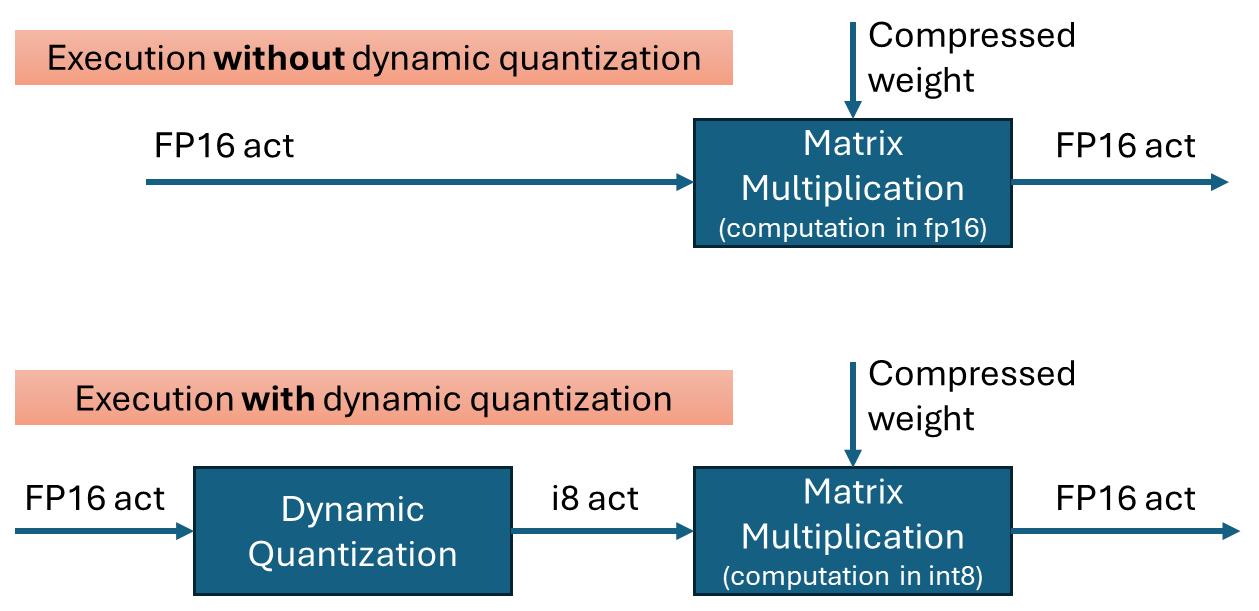
Dynamic quantization is a technique to improve the performance of transformer networks by quantizing the inputs to matrix multiplications. It is effective when weights are already quantized into int4 or int8. By performing the multiplication in int8 instead of fp16, computations can be executed faster with minimal loss in accuracy.
To perform quantization, the data is grouped, and the minimum and maximum values within each group are used to calculate the scale(and zero-point) for quantization. In OpenVINO’s dynamic quantization, this grouping occurs along the embedding axis (i.e., the innermost axis). The group size is configurable, as it impacts both performance and accuracy.
Default behavior on GPU with XMX for OpenVINO 2025.2
In the OpenVINO 2025.2 release, dynamic quantization is enabled by default for GPUs with XMX support. When a model contains a suitable matrix multiplication layer, OpenVINO automatically inserts a dynamic quantization layer before the MatMul operation. No additional configuration is required to activate dynamic quantization.
By default, dynamic quantization is applied per-token, meaning a unique scale value is generated for each token. This per-token granularity is chosen to maximize performance benefits.
However, dynamic quantization is applied conditionally based on input characteristics. Specifically, it is not applied when the token length is short—64 tokens or fewer.(That is, the row size of the matrix multiplication)
For example:
-If you run a large language model (LLM) with a short input prompt (≤ 64 tokens), dynamic quantization is disabled.
-If the prompt exceeds 64 tokens, dynamic quantization is enabled and may improve performance.
Note: Even in the long-input case, the second token is currently not dynamically quantized because row-size in matrix multiplication is small with KV cache.
Performance and Accuracy Impact
The impact of dynamic quantization on performance and accuracy can vary depending on the target model.
Performance
In general, dynamic quantization is expected to improve the performance of transformer models, including large language models (LLMs) with long input sequences—often by several tens of percent. However, the actual gain depends on several factors:
-Low MatMul Contribution: If the MatMul operation constitutes only a small portion of the model's total execution time, the performance benefit will be limited. For instance, in very long-context inputs, scaled-dot-product-attention may dominate the runtime, reducing the relative impact of MatMul optimization.
-Short Token Lengths: Performance gains diminish with shorter token lengths. While dynamic quantization improves compute efficiency, shorter inputs tend to be dominated by weight I/O overhead rather than compute cost.
Accuracy
Accuracy was evaluated using an internal test set and found to be within acceptable limits. However, depending on the model and workload, users may observe noticeable accuracy degradation.
If accuracy is a concern, you may:
-Disable dynamic quantization, or
-Use a smaller group size (e.g., 256), which can improve accuracy at some cost to performance.
How to Verify If dynamic quantization is Enabled on GPU with XMX
Since dynamic quantization occurs automatically under the hood, you may want to verify whether it is active. There are two main methods to check:
-Execution graph (exec-graph): The transformed graph generated by OpenVINO will include an additional "dynamic_quantize" layer if dynamic quantization is applied. You can inspect this by dumping the execution graph using the benchmark_app tool, assuming your model can be run with it. Please see the documentation for details: https://docs.openvino.ai/nightly/get-started/learn-openvino/openvino-samples/benchmark-tool.html
-Opencl-intercept-layer: You can view the list of executed kernels using the opencl-intercept-layer. Both call logging and device performance timing modes will show the "dynamic_quantize" kernel if it is executed. https://github.com/intel/opencl-intercept-layer
GraphTransformation with Dynamic Quantization
When dynamic quantization is enabled (i.e., dynamic_quantization_group_size != 0), a dynamic_quantize node is inserted before the target matrix multiplication nodes. (See the diagram above) Since the input length for LLMs is only known at inference time, the execution path is determined dynamically. If the input length is short (≤ 64 tokens), the dynamic_quantize node is skipped. For longer inputs, the node is executed to apply quantization.
If dynamic quantization is disabled (dynamic_quantization_group_size == 0), the dynamic_quantize node is not added to the graph at all.
Related properties
-dynamic_quantization_group_size: Sets the group size for dynamic quantization. In OpenVINO 2025.2, for GPUs with XMX, the default value is UINT64_MAX, which corresponds to per-token quantization.
For instructions on setting this property, please refer to: https://docs.openvino.ai/2025/openvino-workflow-generative/inference-with-optimum-intel.html#enabling-openvino-runtime-optimization
-OV_GPU_ASYM_DYNAMIC_QUANTIZATION: Enables asymmetric dynamic quantization. This means that in addition to the scale, a zero-point value is also computed during quantization. This setting is configured via an environment variable.
-OV_GPU_DYNAMIC_QUANTIZATION_THRESHOLD: Defines the minimum token length (or row size of the matrix) required to apply dynamic quantization. If the input token length is less than or equal to this value, dynamic quantization is not applied.
The default value is 64.
This setting can also be configured via an environment variable.
OpenVINO is powered by OneDNN for the best performance on discrete GPU
OpenVINO and OneDNN
OpenVINO™ is a framework designed to accelerate deep-learning models from DL frameworks like Tensorflow or Pytorch. By using OpenVINO, developers can directly deploy inference application without reconstructing the model by low-level API. It consists of various components, and for running inference on a GPU, a key component is the highly optimized deep-learning kernels, such as convolution, pooling, or matrix multiplication.
On the other hand, Intel® oneAPI Deep Neural Network Library (oneDNN), is a library that provides basic deep-learning building blocks, mainly kernels. It differs from OpenVINO in a way that OneDNN provides APIs for running deep-learning nodes like convolution, but not for running deep-learning models such as Resnet-50.
OpenVINO utilizes OneDNN GPU kernels for discrete GPUs, in addition to its own GPU kernels. It is to accelerate compute-intensive workloads to an extreme level on discrete GPUs. While OpenVINO already includes highly-optimized and mature deep-learning kernels for integrated GPUs, discrete GPUs include a new hardware block called a systolic array, which accelerates compute-intensive kernels. OneDNN provides these kernels with systolic array usage.
If you want to learn more about the systolic array and the advancements in discrete GPUs, please refer to this article.
How does OneDNN accelerates DL workloads for OpenVINO?
When you load deep-learning models in OpenVINO, they go through multiple stages called graph compilation. The purpose of graph compilation is to create the "execution plan" for the model on the target hardware.
During graph compilation, OpenVINO GPU plugin checks the target hardware to determine whether it has a systolic array or not. If the hardware has a systolic array(which means you have a discrete GPU like Arc, Flex, or GPU Max series), OpenVINO compiles the model so that compute-intensive layers are processed using OneDNN kernels.
OpenVINO kernels and OneDNN kernels use a single OpenCL context and shared buffers, eliminating the overhead of buffer-copying. For example, OneDNN layer computes a layers and fills a buffer, which then may be read by OpenVINO kernels because both kernels run in a single OpenCL context.
You may wonder why only some of the layers are processed by OneDNN while others are still processed by OpenVINO kernels. This is due to the variety of required kernels. OneDNN includes only certain key kernels for deep learning while OpenVINO contains many kernels to cover a wide range of models.
OneDNN is statically linked to OpenVINO GPU Plugin, which is why you cannot find the OneDNN library from released OpenVINO binary. The dynamic library of OpenVINO GPU Plugin includes OneDNN.
The GPU plugin and the CPU plugin have separate versions of OneDNN. To reduce the compiled binary size, the OpenVINO GPU plugin contains only the GPU kernels of OneDNN, and the OpenVINO CPU plugin contains only the CPU kernels of OneDNN.
Hands-on Tips and FAQs
What should an application developer do to take advantage of OneDNN?
If the hardware supports a systolic array and the model has layers that can be accelerated by OneDNN, it will be accelerated automatically without any action required from application developers.
How can I determine whether OneDNN kernels are being used or not?
You can check the OneDNN verbose log or the executed kernel names.
Set `ONEDNN_VERBOSE=1` to see the OneDNN verbose log. Then you will see a bunch of OneDNN kernel execution log, which means that OneDNN kernels are properly executed. Each execution of OneDNN kernel will print a line. If all kernels are executed without OneDNN, you will not see any of such log line.
Alternatively, you can check the kernel names from performance counter option from benchmark_app. (--pc)
OneDNN layers include colon in the `execType` field as shown below. In this case, convolutions are handled by OneDNN jit:ir kernels. MaxPool is also handled by OneDNN kernel that is implemented with OpenCL.(and in this case, the systolic array is not used)
Can we run networks without Onednn on discrete GPU?
It is not supported out-of-box and it is not recommended to do so because systolic array will not be used and the performance will be very different.
If you want to try without OneDNN still, you can follow this documentation and use `OV_GPU_DisableOnednn`.
How to know whether my GPU will be accelerated with OneDNN(or it has systolic array or not)?
You can use hello_query_device from OpenVINO sample app to check whether it has `GPU_HW_MATMUL` in `OPTIMIZATION_CAPABILITIES`.
How to check the version of OneDNN?
You can set `ONEDNN_VERBOSE=1` to check see the verbose log. Below, you can see that OneDNN version is v3.1 as an example. (OnnDNN 3.1 was used for OpenVINO 23.0 release)
Please note that it is shown only when OneDNN is actually used in the target hardware. If the model is not accelerated through OneDNN, OneDNN version will not be shown.
Is it possible to try different OneDNN version?
As it is statically linked, you cannot try different OneDNN version from single OpenVINO version. It is also not recommended to build OpenVINO with different OneDNN version than it is originally built because we do not guarantee that it works properly.
How to profile OneDNN execution time?
Profiling is also integrated to OpenVINO. So you can use profiling feature of OpenVINO, such as --pc and --pcsort option from benchmark_app. However, it includes some additional overhead for OneDNN and it may report higher execution time than actual time especially for small layers. More reliable method is to use DevicePerformanceTiming with opencl-intercept-layers.
How to Install Intel GPU Drivers on Windows and Ubuntu
Introduction
OpenVINO is an open-source toolkit for optimization and deployment of AI inference. OpenVINO results in more efficient inference of deep learning models at the edge or in data centers. OpenVINO compiles models to run on many different devices, meaning you will have the flexibility to write code once and deploy your model across CPUs, GPUs, VPUs and other accelerators.
The new family of Intel discrete GPUs are not just for gaming, they can also run AI at the edge or on servers. Use this guide to install drivers and setup your system before using OpenVINO for GPU-based inference.
OpenVINO and GPU Compatibility
To get the best possible performance, it’s important to properly set up and install the current GPU drivers on your system. Below, I provide some recommendations for installing drivers on Windows and Ubuntu. This article was tested on Intel® Arc™ graphics and Intel® Data Center GPU Flex Series on systems with Ubuntu 22.04 LTS and Windows 11. To use the OpenVINO™ GPU plugin and offload inference to Intel® GPU, the Intel® Graphics Driver must be properly configured on your system.
Recommended Configuration for Ubuntu 22.04 LTS
The driver for Ubuntu 22.04 works out of the box with Kernel 5.15.0-57. However, if you upgraded/downgraded your kernel or upgraded from Ubuntu 20.04 LTS to 22.04, I suggest updating the kernel version to linux-image-5.19.0-43-generic.
After updating the kernel, check for the latest driver release. I updated my Ubuntu machine to version 23.13.26032.30, which was the latest version at the time of publishing this article, however OpenVINO could be run on discrete GPU with older or newer driver versions.
NOTE: If you upgraded Ubuntu 20.04 to 22.04, please verify your kernel version `uname –r` before updating the driver.
Recommended Configuration for Windows 11
Many driver versions are available for Windows. To run AI workloads, I suggest using the latest beta driver.
Getting Help
Even if you are using the latest available driver, you should always check if your AI models are running properly and generating the expected results. If you discover a bug for a particular model or failure to run a specific model, please file an issue on GitHub. Before reporting an issue, please check whether using the latest Beta version of the driver and latest version of OpenVINO solves the issue.
NOTE: Always refer to the official GPU driver documentation when setting up your system. This blog provides additional recommendations for the best results when using OpenVINO but it is not a replacement for documentation.
Conclusion
Checking the system requirements in Ubuntu 22.04 LTS and Windows 11 resolves some issues running Generative AI models like Stable Diffusion with OpenVINO on discrete GPUs. These updates prevent crashes and compilation errors or poor performance with Stable Diffusion. I suggest testing your AI models with the new driver installation, as it will likely improve the performance of your application. Try out this Stable Diffusion notebook for testing purposes.
Resources
https://github.com/intel/compute-runtime/
https://www.intel.com/content/www/us/en/products/docs/discrete-gpus/arc/software/drivers.html
https://www.intel.com/content/www/us/en/download/729157/intel-arc-iris-xe-graphics-beta-windows.html
https://docs.openvino.ai/2023.0/openvino_docs_OV_UG_supported_plugins_GPU.html
https://github.com/openvinotoolkit/openvino_notebooks/tree/main/notebooks/108-gpu-device
Techniques for faster AI inference throughput with OpenVINO on Intel GPUs
Authors: Mingyu Kim, Vladimir Paramuzov, Nico Galoppo
Intel’s newest GPUs, such as Intel® Data Center GPU Flex Series, and Intel® Arc™ GPU, introduce a range of new hardware features that benefit AI workloads. Starting with the 2022.3 release, OpenVINO™ can take advantage of two newly introduced hardware features: XMX (Xe Matrix Extension) and parallel stream execution. This article explains what those features are and how you can check whether they are enabled in your environment. We also show how to benefit from them with OpenVINO, and the performance impact of doing so.
What is XMX (Xe Matrix Extension)?
XMX is a hardware acceleration for matrix multiplication on the newest Intel™ GPUs. Given the same number of Xe Cores, XMX technology provides 4-8x more multiplication capacity at the same precision [1]. OpenVINO, powered by OneDNN, can take advantage of XMX hardware by accelerating int8 and fp16 inference. It brings performance gains in compute-intensive deep learning primitives such as convolution and matrix multiplication.
Under the hood, XMX is a well-known hardware architecture called a systolic array. Systolic arrays increase computational capacity without increasing memory (or register) access. The magic happens by pipelining multiple computations with a single data access, as opposed to the traditional fetch-compute-store pipeline. It is implemented by connecting multiple computation nodes in series. Data is fed into the front, goes through several steps of multiplication-add, and finally is stored back to memory.
How to check whether you have XMX?
You can check whether your GPU hardware (and software stack) supports XMX with OpenVINO™’s hello_query_device sample. When you run the sample application, it lists all detected inference devices along with its properties. You can check for XMX support by looking at the OPTIMIZATION_CAPABILITIES property and checking for the GPU_HW_MATMUL value.
In the listing below you can see that our system has two GPU devices for inference, and only GPU.1 has XMX support.
As mentioned, XMX provides a way to get significantly more compute capacity on a GPU. The next feature doesn’t provide more capacity, but it allows ways to use that capacity more efficiently.
What is parallel execution of multiple streams?
Another improvement of Intel®’s discrete GPUs is to process multiple compute streams in parallel. Certain deep learning inference workloads are too small to fill all hardware compute resources of a given GPU. In such a case it is beneficial to run multiple compute streams (or inference requests) in parallel, such that the GPU hardware has more work to process at any given point in time. With parallel execution of multiple streams, Intel GPUs can increase hardware efficiency.
How to check for parallel execution support?
As of the OpenVINO 2022.3 release, there is only an indirect way to query how many streams your GPU can process in parallel. In the next release it will be possible to query the range of streams using the ov::range_for_streams property query and the hello_query_device_sample. Meanwhile, one can use the benchmark_app to report the default number of streams (NUM_STREAMS). If the GPU does not support parallel stream execution, NUM_STREAMS will be 2. If the GPU does support it, NUM_STREAMS will be larger than 2. The benchmark_app log below shows that GPU.1 supports 4-stream parallel execution.
However, it depends on application usage
Parallel stream execution can bring significant performance benefit, but only when used appropriately by the application. It will bring good performance gain if the application can run multiple independent inference requests in parallel, whether from single process or multiple processes. On the other hand, if there is no opportunity for parallel execution of multiple inference requests, then there is no gain to be had from multi-stream hardware execution.
Demonstration of performance tuning through benchmark_app
DISCLAIMER: The performance may vary depending on the system and usage.
OpenVINO benchmark_app is a very handy tool to analyze performance in various conditions. Here we’ll show the performance trend for an Intel® discrete GPU with XMX and four parallel hardware execution streams.
The performance was measured on a pre-production version of the Intel® Arc™ A770 Limited Edition GPU with 16 GiB of memory. The host system is a 12th Gen Intel(R) Core(TM) i9-12900K with 64GiB of RAM (4 DDR4-2667 modules) running Ubuntu OS 20.04.5 LTS with Linux kernel 5.15.47.
Performance comparison with high-level performance hints
Even though all supported devices in OpenVINO™ offer low-level performance settings, utilizing them is not recommended outside of very few cases. The preferred way to configure performance in OpenVINO Runtime is using performance hints. This is a future-proof solution fully compatible with the automatic device selection inference mode and designed with portability in mind.
OpenVINO benchmark_app exposes the high-level performance hints with the performance hint option for easy configuration of best latency and throughput. In short, latency mode picks the optimal configuration for low latency with the cost of low throughput, and throughput mode picks the optimal configuration for high throughput with the cost of high latency.
The table below shows throughput for various combinations of execution configuration for resnet-50.
Throughput mode is achieving much higher FPS compared to latency mode because inference happens with higher batch size and parallel stream execution. You can also see that, in throughput mode, the throughput with fp16 is 5.4x higher than with fp32 due to the use of XMX.
In the experiments below we manually explore different configurations of the performance parameters for demonstration purposes; It is generally not recommended to tune manually. Once the optimal parameters are known, they can be applied in production.
Performance gain from XMX
Performance gain from XMX can be observed by comparing int8/fp16 against fp32 performance because OpenVINO does not provide an option to turn XMX off. Since fp32 computations are not executed by the XMX hardware pipe, but rather by the less efficient fetch-compute-store pipe, you can see that the performance gap between fp32 and fp16 is much larger than the expected factor of two.
We choose a batch size of 64 to demonstrate the best case performance gain. When the batch size is small, the performance difference is not always as prominent since the workload could become too small for the GPU.
As you can see from the execution log, fp16 runs ~5.49x faster than fp32. Int8 throughput is ~2.07x higher than fp16. The difference between fp16 and fp32 is due to fp16 acceleration from XMX while fp32 is not using XMX. The performance gain of int8 over fp16 is 2.07x because both are accelerated with XMX.
Performance gain from parallel stream execution
You can see from the log below that performance goes up as we have more streams up to 4. It is because the GPU can handle 4 streams in parallel.
Note that if the inference workload is large enough, more streams might not bring much or any performance gain. For example, when increasing the batch size, throughput may saturate earlier than at 4 streams.
How to take advantage the improvements in your application
For XMX, all you need to do is run your int8 or fp16 model with the OpenVINO™ Runtime version 2022.3 or above. If the model is fp32(single precision), it will not be accelerated by XMX. To quantize a model and create an OpenVINO int8 IR, please refer to Quantizing Models Post-training. To create an OpenVINO fp16 IR from a fp32 floating-point model, please refer to Compressing a Model to FP16 page.
For parallel stream execution, you can set throughput hint as described in Optimizing for Throughput. It will automatically set the number of parallel streams with best number.
Conclusion
In this article, we introduced two key features of Intel®’s discrete GPUs: XMX and parallel stream execution. Most int8/fp16 deep learning networks can benefit from the XMX engine with no additional configuration. When properly configured by the application, parallel stream execution can bring significant performance gains too!
[1] In the Xe-HPG architecture, the XMX delivers 256 INT8 ops per clock (DPAS), while the (non-systolic) Xe Core vector engine delivers 64 INT8 ops per clock – a 4x throughput increase [reference]. In the Xe-HPC architecture, the XMX systolic array depth has been increased to 8 and delivers 4096 FP16 ops per clock, while the (non-systolic) Xe Core vector engine delivers 512 FP16 ops per clock – a 8x throughput increase [reference].
Notices & Disclaimers
Performance varies by use, configuration and other factors. Learn more at www.Intel.com/PerformanceIndex.
Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See backup for configuration details. No product or component can be absolutely secure.
See backup for configuration details. For more complete information about performance and benchmark results, visit www.intel.com/benchmarks
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
Remote Tensor API Sample
This AI pipeline implements zero-copy between SYCL and OpenVINO through the Remote Tensor API of the GPU Plugin.
- Introduction
The development of SYCL simplifies the use of OpenCL, which can fully exploit the computing power of GPU in the pipeline. Meanwhile, SYCL has more flexibility to do customized pre- and post-processing of OpenVINO. To further optimize the pipeline, developers can use GPU Plugin to avoid the memory copy overhead between SYCL and OpenVINO. The GPU plugin provides the ov::RemoteContext and ov::RemoteTensor interfaces for video memory sharing and interoperability with existing native APIs, such as OpenCL, Microsoft DirectX, or VAAPI. For details, please refer to the online documentation of OpenVINO.
Based on the pseudocode of the online documentation, here we provide a simple pipeline sample with Remote Tensor API. Because in the rapid iteration of oneAPI, sometimes customers need quick verification so that this sample can be used for testing. OneAPI also provides a real-world, end-to-end example, which optimizes PointPillars for lidar object detection.
- Components
SYCL preprocessing is based on the Sepia Filter sample, which demonstrates how to convert a color image to a Sepia tone image, a monochromatic image with a distinctive Brown Gray color. The sample program works by offloading the compute-intensive conversion of each pixel to Sepia tone using SYCL*-compliant code for CPU and GPU.
OpenVINO inferencing is based on the OpenVINO classification sample, the input from SYCL filtered image in the device will be sent into OpenVINO as a remote tensor without a memory copy.
Remote Tensor API: Create RemoteContext from SYCL pre-processing’s native handle. After model compiling, do memory sharing between the application and GPU plugin with from cl::Buffer to remote tensor.
- Build Sample on Linux
Download the source code from the link. Prepare the model and images.
To run the sample, you need to specify a model and image:
Use pre-trained models from the Open Model Zoo. The models can be downloaded using the Model Downloader. Use images from the media files collection.
Run on Intel NUC Core 11 iGPU with OpenVINO 2022.2 and oneAPI 2022.3.
./intel64/hello_nv12_input_classification_oneAPI../model/FP32/alexnet.xml ../image/dog512.bmp GPU 2
Sample Output:
Warning: With the updating of OpenVINO and oneAPI, different versions may cause problems with the tools in the common directory or the new SYCL header name. Please use the same version or debug following the corresponding release instructions.
Intel® DL Streamer Optimize Media-AI pipeline on Intel® Data Center Flex dGPU by Docker
Authors Kunda Xu, Wenyi Zou
Introduction
In this blog is about How to use DL-streamer to build a complete Media-AI pipeline (Including: Video Access, Media Decode, AI Inference, Media Encode and Result Export). And the pipeline will be accelerated by OpenVINO™ and optimize to run on Flex dGPU(Intel® Data Center Flex dGPU)
Requirement
- DL-streamer
Intel® Deep Learning Streamer (Intel® DL Streamer)Pipeline Framework is an easy way to construct media analytics pipelines using Intel® Distribution of OpenVINO™ Toolkit. It leverages the open source media framework GStreamer to provide optimized media operations and Deep Learning Inference Engine from OpenVINO™ Toolkit to provide optimized inference.
- OpenVINO
OpenVINO™ is an open-source toolkit for optimizing and deploying AI inference which can boost deep learning performance in computer vision, automatic speech recognition, natural language processing and other common task.
- Docker (Optional)
Docker is an open-source platform that enables developers to build, deploy, run, update, and manage containers—standardized, executable components that combine application source code with the operating system (OS) libraries and dependencies required to run that code in any environment.
Install DL-Streamer and OpenVINO™ via Docker
Images for Intel® Data Center GPU Flex Series
Images 2023.0.0-ubuntu22-gpu682* are intended for Intel® Data Center GPU Flex Series and include
3. Drivers for Intel® Data Center GPU Flex Series, drivers version 682.14
Two images are listed below, images -devel additionally contain samples and development files
Runtime image that includes GStreamer* Pipeline Framework elements, elements built with Intel® oneAPI DPC++/C++ Compiler
Developer image that builds on runtime image containing samples, development files and a model downloader, built with Intel® oneAPI DPC++/C++ Compiler
Taking “dlstreamer:2023.0.0-ubuntu22-gpu682-dpcpp” docker images as a sample to show how to pull the docker image from docker hub.
DL-Streamer Media-AI pipeline quick start example
Make sure the pre-requirement had already installed, there is a very basic introduction to using object detection models(yolov5) to build a DL-streamer pipeline.
Step 1.Download video and yolov5s model file
Download video
Download yolov5s-416_INT8 model from pipeline-zoo-models
Step 2.Enter Docker and copy the files into docker container
Create and enter the docker container
Open another terminal for file copy into container ,copy video and model into docker container
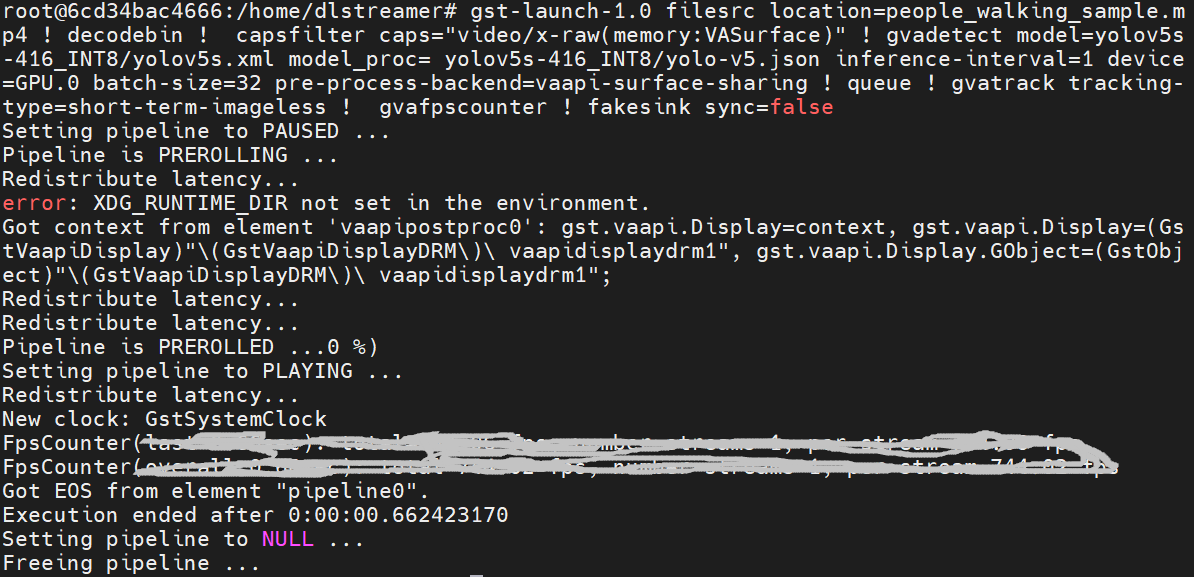
Step 3. Run an object detection Media-AI pipeline
By the following script, we can run pipeline the Media-AI objection detection on the Flex dGPU in the docker container.
If want to encode the detection result and save as video file, can use the follow script
The encoded video file will save in the container and can be copied out in new terminal.
PS. Instruction about DL-streamer CLI parameter
decodebin: Auto-magically constructs a decoding pipeline using available decoders and demuxers via auto-plugging.
vaapipostproc: Consists in various post processing algorithms to be applied to VA surfaces. For e.g. scaling, deinterlacing (bob, motion-adaptive, motion-compensated), noise reduction or sharpening.
gvadetect: Performs object detection on a full-frame or region of interest (ROI) using object detection models such as YOLO v3-v5, MobileNet-SSD, Faster-RCNN etc. Outputs the ROI for detected objects.
gvatrack: Performs object tracking using zero-term, zero-term-imageless, or short-term-imageless tracking algorithms. Zero-term tracking assigns unique object IDs and requires object detection to run on every frame. Short-term tracking allows to track objects between frames, there by reducing the need to run object detection on each frame. Imageless tracking forms object associations based on the movement and shape of objects, and it does not use image data.
gvafpscounter: Measures frames per second across multiple streams in a single process.
Tuning Tips
Users can refer the different platform using case which were supported by OpenVINO™ and the device profiling API to realize performance tuning of your inference program between CPU, iGPU, dGPU. It will also be helpful to developer finding out the place where has the potential space of performance improvement.