
.png)
Mingyu
Kim
Dynamic quantization support from GPU with XMX
Scope of this document
This article explains the behavior of dynamic quantization on GPUs with XMX, such as Lunar Lake, Arrow lake and discrete GPU family(Alchemist, Battlemage).
It does not cover CPUs or GPUs without XMX(such as Meteor Lake). While the dynamic quantization is supported on these platforms as well, the behavior may differ slightly.
What is dynamic quantization?
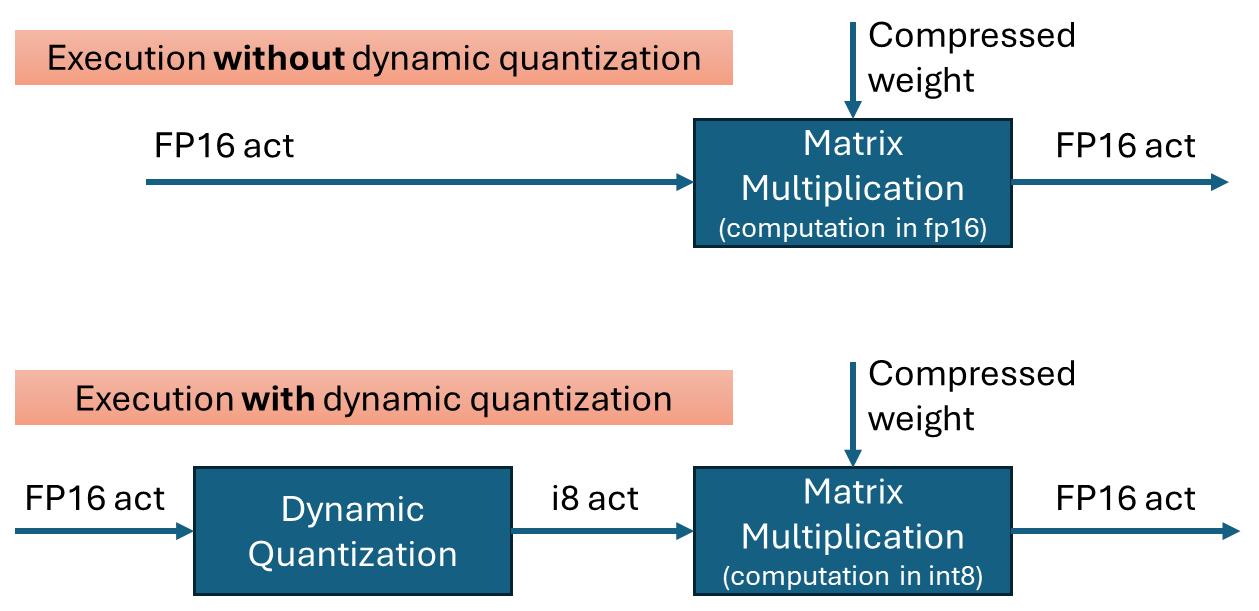
Dynamic quantization is a technique to improve the performance of transformer networks by quantizing the inputs to matrix multiplications. It is effective when weights are already quantized into int4 or int8. By performing the multiplication in int8 instead of fp16, computations can be executed faster with minimal loss in accuracy.
To perform quantization, the data is grouped, and the minimum and maximum values within each group are used to calculate the scale(and zero-point) for quantization. In OpenVINO’s dynamic quantization, this grouping occurs along the embedding axis (i.e., the innermost axis). The group size is configurable, as it impacts both performance and accuracy.
Default behavior on GPU with XMX for OpenVINO 2025.2
In the OpenVINO 2025.2 release, dynamic quantization is enabled by default for GPUs with XMX support. When a model contains a suitable matrix multiplication layer, OpenVINO automatically inserts a dynamic quantization layer before the MatMul operation. No additional configuration is required to activate dynamic quantization.
By default, dynamic quantization is applied per-token, meaning a unique scale value is generated for each token. This per-token granularity is chosen to maximize performance benefits.
However, dynamic quantization is applied conditionally based on input characteristics. Specifically, it is not applied when the token length is short—64 tokens or fewer.(That is, the row size of the matrix multiplication)
For example:
-If you run a large language model (LLM) with a short input prompt (≤ 64 tokens), dynamic quantization is disabled.
-If the prompt exceeds 64 tokens, dynamic quantization is enabled and may improve performance.
Note: Even in the long-input case, the second token is currently not dynamically quantized because row-size in matrix multiplication is small with KV cache.
Performance and Accuracy Impact
The impact of dynamic quantization on performance and accuracy can vary depending on the target model.
Performance
In general, dynamic quantization is expected to improve the performance of transformer models, including large language models (LLMs) with long input sequences—often by several tens of percent. However, the actual gain depends on several factors:
-Low MatMul Contribution: If the MatMul operation constitutes only a small portion of the model's total execution time, the performance benefit will be limited. For instance, in very long-context inputs, scaled-dot-product-attention may dominate the runtime, reducing the relative impact of MatMul optimization.
-Short Token Lengths: Performance gains diminish with shorter token lengths. While dynamic quantization improves compute efficiency, shorter inputs tend to be dominated by weight I/O overhead rather than compute cost.
Accuracy
Accuracy was evaluated using an internal test set and found to be within acceptable limits. However, depending on the model and workload, users may observe noticeable accuracy degradation.
If accuracy is a concern, you may:
-Disable dynamic quantization, or
-Use a smaller group size (e.g., 256), which can improve accuracy at some cost to performance.
How to Verify If dynamic quantization is Enabled on GPU with XMX
Since dynamic quantization occurs automatically under the hood, you may want to verify whether it is active. There are two main methods to check:
-Execution graph (exec-graph): The transformed graph generated by OpenVINO will include an additional "dynamic_quantize" layer if dynamic quantization is applied. You can inspect this by dumping the execution graph using the benchmark_app tool, assuming your model can be run with it. Please see the documentation for details: https://docs.openvino.ai/nightly/get-started/learn-openvino/openvino-samples/benchmark-tool.html
-Opencl-intercept-layer: You can view the list of executed kernels using the opencl-intercept-layer. Both call logging and device performance timing modes will show the "dynamic_quantize" kernel if it is executed. https://github.com/intel/opencl-intercept-layer
GraphTransformation with Dynamic Quantization
When dynamic quantization is enabled (i.e., dynamic_quantization_group_size != 0), a dynamic_quantize node is inserted before the target matrix multiplication nodes. (See the diagram above) Since the input length for LLMs is only known at inference time, the execution path is determined dynamically. If the input length is short (≤ 64 tokens), the dynamic_quantize node is skipped. For longer inputs, the node is executed to apply quantization.
If dynamic quantization is disabled (dynamic_quantization_group_size == 0), the dynamic_quantize node is not added to the graph at all.
Related properties
-dynamic_quantization_group_size: Sets the group size for dynamic quantization. In OpenVINO 2025.2, for GPUs with XMX, the default value is UINT64_MAX, which corresponds to per-token quantization.
For instructions on setting this property, please refer to: https://docs.openvino.ai/2025/openvino-workflow-generative/inference-with-optimum-intel.html#enabling-openvino-runtime-optimization
-OV_GPU_ASYM_DYNAMIC_QUANTIZATION: Enables asymmetric dynamic quantization. This means that in addition to the scale, a zero-point value is also computed during quantization. This setting is configured via an environment variable.
-OV_GPU_DYNAMIC_QUANTIZATION_THRESHOLD: Defines the minimum token length (or row size of the matrix) required to apply dynamic quantization. If the input token length is less than or equal to this value, dynamic quantization is not applied.
The default value is 64.
This setting can also be configured via an environment variable.































