
.png)
Aleksandr
Kozlov
Q1'25: Technology Update – Low Precision and Model Optimization
Authors
Alexander Kozlov, Nikolay Lyalyushkin, Nikita Savelyev, Souvikk Kundu, Andrey Anufriev, Pablo Munoz, Alexander Suslov, Liubov Talamanova, Daniil Lyakhov, Yury Gorbachev, Nilesh Jain, Maxim Proshin, Evangelos Georganas
Summary
This quarter we noticed a significant effort and progress on optimizing LLMs for long-context tasks. The current trend is that each and every LLM is published with the extended (usually interpolated) context which is usually 128K and above. The idea is to naturally process large amount of data within the model instead of preprocess it the way RAG systems do it. It inevitably increases computational complexity specifically of ScaledDotProductAttention operation which gets dominant on long contexts. Thus, many works devoted to the optimization of rather prefill with special computation patterns (A-shape, Tri-shape, XAttention) or using Sparse Attention at the decoding stage.
Highlights
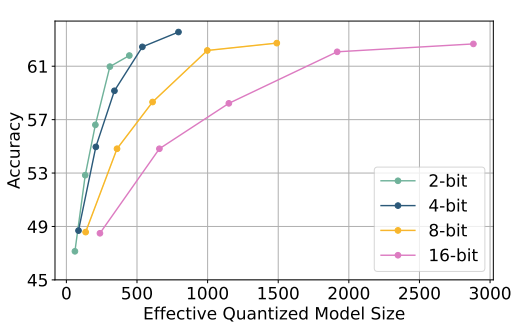
- ParetoQ: Scaling Laws in Extremely Low-bit LLM Quantization by Meta (https://arxiv.org/pdf/2502.02631). The paper presents a unified framework that facilitates comparisons across 1-bit, 1.58-bit, 2-bit, 3-bit, and 4-bit quantization settings. The findings reveal a notable learning transition between 2 and 3 bits: For 3-bits and above, the fine-tuned models stay close to their original pre-trained distributions, whereas for learning 2-bit networks or below, the representations change drastically. By optimizing training schemes and refining quantization functions, the ternary 600M-parameter model even outperforms the previous SoTA ternary 3B-parameter model in accuracy, using only one-fifth of the parameters.
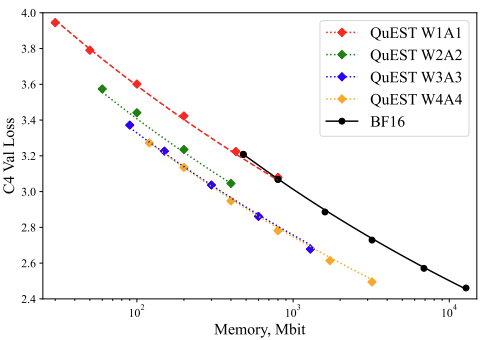
- QuEST: Stable Training of LLMs with 1-Bit Weights and Activations by ISTA and Red Hat AI (https://arxiv.org/pdf/2502.05003). The paper introduces quantization method that allows stable training with 1-bit weights and activations. It achieves this by improving two key aspects of QAT methods: (1) accurate and fast quantization of the (continuous) distributions of weights and activations via Hadamard normalization and MSE-optimal fitting; (2) a new trust gradient estimator based on the idea of explicitly minimizing the error between the noisy gradient computed over quantized states and the “true” (but unknown) full-precision gradient. Experiments on Llama-type architectures show that the method induces stable scaling laws across the entire range of hardware-supported precisions, and can be extended to sparse representations. The code is available at https://github.com/IST-DASLab/QuEST.
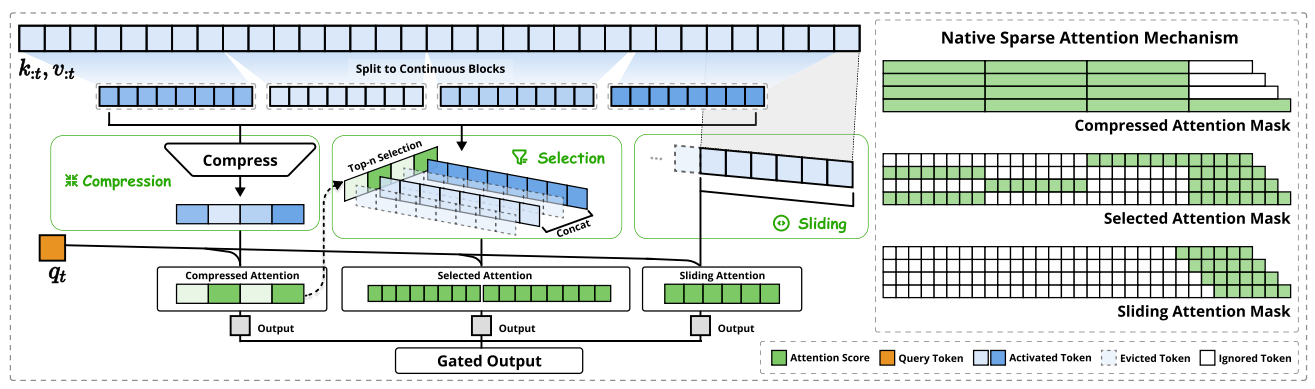
- Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention by Deepseek-AI, Peking University, University of Washington (https://arxiv.org/pdf/2502.11089). The paper presents a method with hardware-aligned optimizations to achieve efficient long-context modeling. It employs a dynamic hierarchical sparse strategy, combining coarse-grained token compression with fine-grained token selection to preserve both global context awareness and local precision. The approach advances sparse attention design with two key features: (1) Authors achieve substantial speedups through arithmetic intensity-balanced algorithm design, with implementation optimizations for modern hardware. (2) They enable end-to-end training, reducing pretraining computation without sacrificing model performance. Experiments show the model pretrained with the proposed method maintains or exceeds Full Attention models across general benchmarks, long-context tasks, and instruction-based reasoning. It achieves substantial speedups over Full Attention on 64k-length sequences across decoding, forward propagation, and backward propagation. Non-official implementations are available on GitHub.
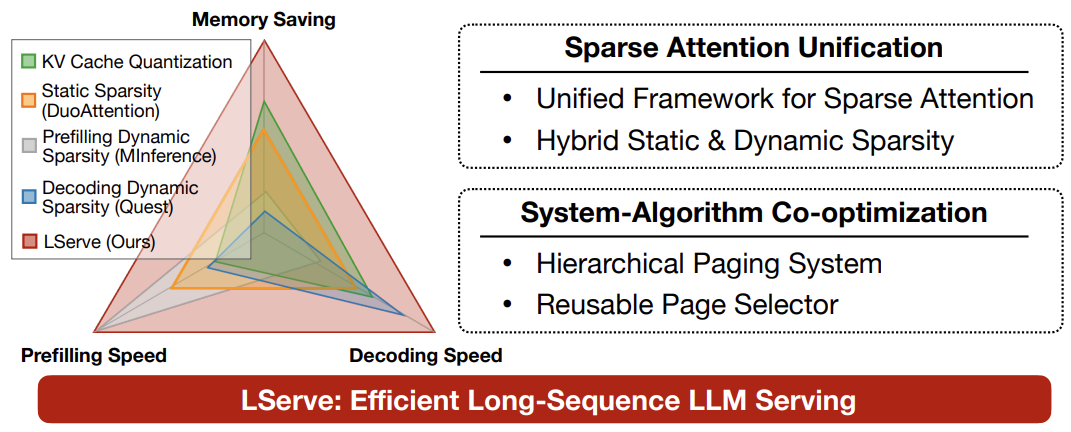
- LSERVE: EFFICIENT LONG-SEQUENCE LLM SERVING WITH UNIFIED SPARSE ATTENTION by MIT, SJTU, Nvidia (https://arxiv.org/pdf/2502.14866). The paper introduces a system that accelerates long-sequence LLM serving via hybrid sparse attention. This method unifies different hardware-friendly, structured sparsity patterns for both prefilling and decoding attention into a single framework, where computations on less important tokens are skipped block-wise. It demonstrates the compatibility of static and dynamic sparsity in long-context LLM attention. Authors convert half of the attention heads to nearly free streaming heads in both the prefilling and decoding stages. Additionally, we they that only a constant number of KV pages is required to preserve long-context capabilities, irrespective of context length. They then design a hierarchical KV page selection policy that dynamically prunes KV pages based on query-centric similarity. The method accelerates LLM prefilling by up to 2.9x and decoding by 1.3-2.1x over vLLM, maintaining long-context accuracy. Code is released at https://github.com/mit-han-lab/omniserve.
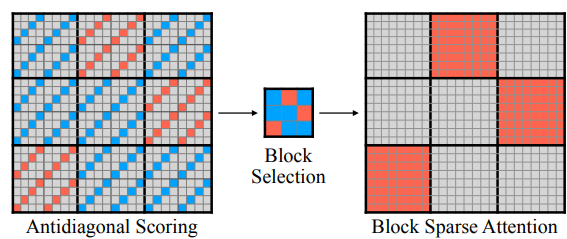
- XAttention: Block Sparse Attention with Antidiagonal Scoring by Tsinghua University, MIT, SJTU, and NVIDIA (https://arxiv.org/pdf/2503.16428). The paper introduces XAttention method that significantly accelerates long-context inference in Transformers models using sparse attention. XAttention’s key innovation is the insight that the sum of antidiagonal values (i.e., from the lower-left to upper-right) in the attention matrix provides a powerful proxy for block importance. This allows for precise identification and pruning of non-essential blocks, resulting in high sparsity and dramatically accelerated inference. On RULER and LongBench for language, VideoMME for video understanding, and VBench for video generation—XAttention achieves accuracy comparable to full attention while delivering substantial computational gains. It shows up to 13.5x acceleration in attention computation. The code is available at https://github.com/mit-han-lab/x-attention.
Papers with notable results
Quantization
- Optimizing Large Language Model Training Using FP4 Quantization by Microsoft and University of Science and Technology of China (https://arxiv.org/pdf/2501.17116). The work introduces the FP4 training framework for LLMs, addressing quantization challenges with two key ideas: a differentiable quantization estimator for precise weight updates and an outlier clamping and compensation strategy to prevent activation collapse. To ensure stability, the framework integrates a mixed-precision training scheme and vector-wise quantization. Experimental results demonstrate that our FP4 framework achieves accuracy comparable to BF16 and FP8, with minimal degradation, scaling effectively to 13B-parameter LLMs trained on up to 100B.
- MQuant: Unleashing the Inference Potential of Multimodal Large Language Models via Full Static Quantization by Houmo AI, Southeast University, and Xi’an Jiaotong University (https://arxiv.org/pdf/2502.00425). The work focuses on the problems of VLM quantization with a coarse scale granularity. It proposes several techniques to tackle the quantization problems, namely: Modality-Specific Static Quantization (MSQ), assigning distinct static scales for visual vs. textual tokens; Attention-Invariant Flexible Switching (AIFS), reordering tokens to preserve casual attention while eliminating expensive token-wise scale computations; Rotation Magnitude Suppression (RMS), mitigating weight outliers arising from online Hadamard rotations. On five mainstream VLMs (including Qwen-VL, MiniCPM-V, CogVLM2), the method achieves near-floating-point accuracy under W4A8 setting. The code is planned to be published.
- An Empirical Study of LLaMA3 Quantization: From LLMs to MLLMs by The University of Hong Kong, Beihang University, and ETH Zurich (https://arxiv.org/pdf/2404.14047). Authors assessed the performance of the LLaMA3-based LLaVA-Next-8B model under 2-4 ultra-low bits with post-training quantization methods. Experimental results indicate that LLaMA3 still suffers from non-negligible degradation in linguistic and visual contexts, particularly under ultra-low bit widths. This highlights the significant performance gap at low bit-width that needs to be addressed in future developments. The code is available at: https://github.com/Macaronlin/LLaMA3-Quantization.
- Nanoscaling Floating-Point (NxFP): NanoMantissa, Adaptive Microexponents, and Code Recycling for Direct-Cast Compression of Large Language Models by Harvard University (https://arxiv.org/pdf/2412.19821). This paper profiles modern LLMs and identifies three main challenges of low-bit Microscaling format, i.e., inaccurate tracking of outliers, vacant quantization levels, nd wasted binary code. In response, Nanoscaling (NxFP) proposes three techniques, i.e., NanoMantissa, Adaptive Microexponent, and Code Recycling to enable better accuracy and smaller memory footprint than state-of-the-art MxFP. Experimental results on direct-cast inference across various modern LLMs demonstrate that the proposed methods outperform MxFP by up to 0.64 in perplexity and by up to 30% in accuracy on MMLU benchmarks.
- RoSTE: An Efficient Quantization-Aware Supervised Fine-Tuning Approach for Large Language Models by University of Minnesota and The Chinese University of Hong Kong (https://arxiv.org/pdf/2502.09003). The paper introduces a fine-tuning based method that directly optimizes quantized weights and rotation matrices within a single model architecture. It proposes a bilevel optimization formulation, where upper level subproblem optimizes weight matrices, while lower level subproblem employs a surrogate loss to guide the selection of rotation matrix. Authors designed an algorithm which alternates between (i) a QAT subroutine incorporating a rotation-enabled straightthrough-estimator (STE) update, and (ii) a low complexity heuristic for selecting rotation matrices based on the random Walsh-Hadamard matrix. They provide a theoretical analysis of the benefits of rotation-enabled quantization in QA-SFT by examining the prediction error resulted from the QAT stage of RoSTE. This analysis directly motivates the use of quantization error based surrogate loss and justifies the adoption.
- NESTQUANT: NESTED LATTICE QUANTIZATION FOR MATRIX PRODUCTS AND LLMS by MIT and Hebrew University of Jerusalem (https://arxiv.org/pdf/2502.09720). The paper proposes a PTQ scheme for weights and activations that is based on self-similar nested lattices. Recent work has mathematically shown such quantizers to be information-theoretically optimal for low-precision matrix multiplication. We implement a practical low-complexity version based on Gosset lattice, making it a drop-in quantizer for any matrix multiplication step (e.g., in self-attention, MLP etc). For example, the method quantizes weights, KV-cache, and activations of Llama-3-8B to 4 bits, achieving perplexity of 6.6 on wikitext2.
- ViM-VQ: Efficient Post-Training Vector Quantization for Visual Mamba by Zhejiang University and vivo Mobile (https://arxiv.org/pdf/2503.09509). A practical study of vector quantization method for Visual Mamba networks (ViMs). Authors identify several key challenges: 1) The weights of Mamba-based blocks in ViMs contain numerous outliers, significantly amplifying quantization errors. 2) When applied to ViMs, the latest VQ methods suffer from excessive memory consumption, lengthy calibration procedures, and suboptimal performance in the search for optimal codewords. They propose a post-training vector quantization method tailored for ViMs. It consists of two components: 1) a fast convex combination optimization algorithm that updates both the convex combinations and the convex hulls to search for optimal codewords, and 2) an incremental vector quantization strategy that incrementally confirms optimal codewords to mitigate truncation errors. The results demonstrate that the method achieves stateof-the-art performance in low-bit quantization across various visual tasks.
- SSVQ: Unleashing the Potential of Vector Quantization with Sign-Splitting by Zhejiang University and vivo Mobile (https://arxiv.org/pdf/2503.08668). The paper proposes the vector quantization approach which decouples the sign bit of weights from the codebook. It involves extracting the sign bits of uncompressed weights and performing clustering and compression on all-positive weights. Authors also introduce latent variables for the sign bit and jointly optimize both the signs and the codebook. Additionally, they implement a progressive freezing strategy for the learnable sign to ensure training stability. Experiments on modern models and tasks demonstrate that the method achieves a good compression-accuracy trade-off compared to conventional VQ. Authors also validate the algorithm on a hardware accelerator, showing that SSVQ achieves a 3× speedup over the 8-bit compressed model by reducing memory access.
- MergeQuant: Accurate 4-bit Static Quantization of Large Language Models by Channel-wise Calibration (https://arxiv.org/pdf/2503.07654). The paper introduces per-channel static quantization method. It integrates the per-channel quantization steps with the corresponding scalings and linear mappings through a Quantization Step Migration method, eliminating the quantization overheads before and after matrix multiplication. Authors also propose dimensional reconstruction and adaptive clipping to address the nonuniformity of quantization scale factors and redistribute the channel variations to the subsequent modules to balance the parameter distribution under QSM. They evaluate method on Llama 2 and Llama 3 models in W4A4 setting.
- QuantCache: Adaptive Importance-Guided Quantization with Hierarchical Latent and Layer Caching for Video Generation by Shanghai Jiao Tong University, MGTV, Shanhai Academy (https://arxiv.org/pdf/2503.06545). Authors propose a training-free inference acceleration framework that jointly optimizes hierarchical latent caching, adaptive importance-guided quantization, and structural redundancy-aware pruning. It achieves an end-to-end latency speedup of 6.72x on OpenSora with minimal loss in generation quality. experiments across multiple video generation benchmarks demonstrate the effectiveness of our method for DiT inference. The code and models will be available at https://github.com/JunyiWuCode/QuantCache.
- Matryoshka Quantization by Google DeepMind (https://arxiv.org/pdf/2502.06786). Practitioners are often forced to maintain multiple models with different quantization levels or serve a single model that best satisfies the quality-latency trade-off. On the other hand, integer data types, such as int8, inherently possess a nested (Matryoshka) structure where smaller bit-width integers, like int4 or int2, are nested within the most significant bits. In this paper, the authors propose Matryoshka Quantization (MatQuant), a multi-scale quantization technique that alleviates the aforementioned challenge. It allows us to train and maintain a single quantized model but serve it with the precision demanded by the deployment. Furthermore, leveraging MatQuant’s co-training and co-distillation regularization, int2 precision models extracted by MatQuant outperform standard int2 quantization by up to to 4% and 7% with OmniQuant and QAT as base algorithms respectively. Finally, authors demonstrate that by using an extra bit to represent outliers, a model with an effective precision of 2.05-bit gives an additional 6% improvement with OmniQuant as the base algorithm.
Pruning/Sparsity
- Mamba-Shedder: Post-Transformer Compression for Efficient Selective Structured State Space Models by Intel Labs (https://arxiv.org/pdf/2501.17088v1). This paper explores the compression of SSM-based models, particularly Mamba and its hybrids. The authors discuss the sensitivity of these models to the removal of selected components at different granularities to reduce the model size and computational overhead, thus improving their efficiency while maintaining accuracy. The proposed solutions, collectively referred to as Mamba-Shedder, achieve a speedup of up to 1.4x during inference, demonstrating that model efficiency can be improved by eliminating several redundancies with minimal impact on the overall model performance. The code is available at https://github.com/IntelLabs/Hardware-Aware-Automated-Machine-Learning.
- DeepSeekAI, The Sparsity Revolution That Shook the AI Market: https://www.linkedin.com/pulse/deepseek-ai-sparsity-revolution-shook-market-jabar-riaz-hwvbf. The blogpost discusses two types of sparsity to train efficient and competitive LLM models, namely data sparsity and model sparsity.
Other
- TPU Scaling Book from Google - a series of blog posts on how to optimize LLMs for Google TPUv5: https://jax-ml.github.io/scaling-book/applied-inference.
- The Ultra-Scale Playbook: Training LLMs on GPU Clusters https://huggingface.co/spaces/nanotron/ultrascale-playbook. A tutorial from HuggingFace on the basics of multi-GPU training and how to scale it.
- Qwen2.5-1M Technical Report by Alibaba (https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-1M/Qwen2_5_1M_Technical_Report.pdf). Authors introduce Qwen2.5-1M, a series of models that extend the context length to 1 million tokens. Compared to the previous 128K version, the Qwen2.5-1M series has significantly enhanced long-context capabilities through long-context pretraining and post-training. To reduce inference costs, authors implement a sparse attention method along with chunked prefill optimization for deployment scenarios and a sparsity refinement method to improve precision. Additionally, they detail optimizations in the inference engine, including kernel optimization, pipeline parallelism, and scheduling optimization, which significantly enhance overall inference performance. Qwen2.5-1M models achieve a remarkable 3x to 7x prefill speedup in scenarios with 1 million tokens of context.
- WaferLLM: A Wafer-Scale LLM Inference System by University of Edinburgh and Microsoft (https://arxiv.org/pdf/2502.04563). The paper introduces LLM inference system that is guided by a device model that captures the unique hardware characteristics of wafer-scale architectures. It proposes MeshGEMM and MeshGEMV, the GEMM and GEMV implementations designed to scale effectively on wafer-scale accelerator. Authors focus on four principles when designing the implementation: Massive Parallel cores, Highly non-uniform memory access Latency, Constrained local Memory, and Limited hardware-assisted Routing. Evaluations show that the method achieves 200× better wafer-scale accelerator utilization than state-of-the-art systems. On a commodity wafer-scale accelerator, it delivers 606× faster and 22× more energy-efficient GEMV compared to an advanced GPU. One of the limitations of the method is a limited model size due to a need to replicate memory over the computational units to increase the latency.
- EmbBERT-Q: Breaking Memory Barriers in Embedded NLP by Politecnico di Milano (https://arxiv.org/pdf/2502.10001). The paper proposes a new LM model specifically designed for tiny devices, combining efficiency and effectiveness. Authors analytically evaluate the memory usage and computational complexity of the model and its components, providing a tool to evaluate the weights and activations of memory trade-offs required to operate within tiny device constraints. They also release all code, scripts, and model checkpoints at https://github.com/RiccardoBravin/tiny-LLM.
- M2R2: MIXTURE OF MULTI-RATE RESIDUALS FOR EFFICIENT TRANSFORMER INFERENCE by Apple (https://arxiv.org/pdf/2502.02040). The paper introduce Mixture of Multi-rate Residuals, a framework that dynamically modulates the velocity of residual transformations to optimize early residual alignment. This modification improves inference efficiency by better aligning intermediate representations at earlier stages. Authors show the efficacy of the technique in diverse optimization setups such as dynamic computing, speculative decoding, and MoE Ahead-of-Time. In self-speculative decoding setups, M2R2 achieves up to 2.8X speedups on MT-Bench under lossless conditions. In Mixture-of-Experts architectures, they enhance decoding speed by coupling early residual alignment with ahead-of-time expert loading into high-bandwidth memory. This enables concurrent memory access and computation, reducing the latency bottlenecks inherent in expert switching during decoding. Empirical results show that the method delivers a speedup of 2.9X in MoE architectures.
- Extending Language Model Context Up to 3 Million Tokens on a Single GPU by KAIST and DeepAuto.ai (https://arxiv.org/pdf/2502.08910). To enable efficient and practical long-context utilization, authors introduce an LLM inference framework that accelerates processing by dynamically eliminating irrelevant context tokens through a modular hierarchical token pruning algorithm. The method also allows generalization to longer sequences by selectively applying various RoPE adjustment methods according to the internal attention patterns within LLMs. They also offload the key-value cache to host memory during inference, significantly reducing GPU memory pressure. As a result, the method enables the processing of up to 3 million tokens on a single L40s 48GB GPU without any permanent loss of context information. The framework achieves an 18.95x.
- KernelBench: Can LLMs Write Efficient GPU Kernels? by Stanford University and Princeton University (https://arxiv.org/pdf/2502.10517). The paper introduces KernelBench, an open-source framework for evaluating LMs’ ability to write fast and correct kernels on a suite of 250 carefully selected PyTorch ML workloads. KernelBench represents a real-world engineering environment and making progress on the introduced benchmark directly translates to faster practical kernels. Auhors introduce a new evaluation metric fastp, which measures the percentage of generated kernels that are functionally correct and offer a speedup greater than an adjustable threshold p over baseline. Experiments across various models and test-time methods show that frontier reasoning models perform the best out of the box but still fall short overall, matching the PyTorch baseline in less than 20% of the cases.
- Investigating the Impact of Quantization Methods on the Safety and Reliability of Large Language Models by Skolkovo Institute, Artificial Intelligence Research Institute, HSE University (https://arxiv.org/pdf/2502.15799). Authors introduce OpenSafetyMini, a openended safety dataset designed to better distinguish between models. They evaluate 4 state-ofthe-art quantization techniques across LLaMA and Mistral models using 4 benchmarks, including human evaluations. Findings reveal that the optimal quantization method varies for 4-bit precision, while vector quantization techniques deliver the best safety and trustworthiness performance at 2-bit precision, providing foundation for future research. The dataset and reproduces available at: https://github.com/On-Point-RND/OpenSafetyMini-Investigating-the-Impact-of-Quantization-Methods-on-the-Safety-and-Reliability-of-LLM.
- MOBA: MIXTURE OF BLOCK ATTENTION FOR LONG-CONTEXT LLMS by Moonshot AI, Tsinghua University, and Zhejiang University (https://arxiv.org/pdf/2502.13189v1). In this work, authors propose a solution that adheres to the “less structure” principle, allowing the model to determine where to attend autonomously, rather than introducing predefined biases. They introduce Mixture of Block Attention (MoBA), an approach that applies the principles of Mixture of Experts (MoE) to the attention mechanism. It is based on block partitioning and routing strategy within Multi-Head Self-Attention. The code is available at https://github.com/MoonshotAI/MoBA.
- JUDGE DECODING: FASTER SPECULATIVE SAMPLING REQUIRES GOING BEYOND MODEL ALIGNMENT by Meta GenAI and ETH Zurich (https://openreview.net/pdf?id=mtSSFiqW6y). The paper demonstrates through a series of experiments how the decision mechanism in speculative decoding rejects many high-quality tokens, identifying a key limitation of the technique. Authors adapt verification using ideas from LLM-as-a-judge, eliciting the same versatile rating capability in the target by adding a simple linear layer that can be trained in under 1.5 hours. Using a Llama 8B/70B-Judge, the proposed approach obtains speedups of 9x over standard decoding, achieving an unprecedented 129 tokens/s, while maintaining the quality of Llama-405B on a range of benchmarks.
Software
- FlashMLA by Deepseek: https://github.com/deepseek-ai/FlashMLA. FlashMLA is an efficient MLA decoding kernel for Hopper GPUs, optimized for variable-length sequences serving.
- DeepSeek releases DeepGEMM is a library designed for clean and efficient FP8 General Matrix Multiplications (GEMMs) with fine-grained scaling: https://github.com/deepseek-ai/DeepGEMM.
- SVDQuant Meets NVFP4: 4× Smaller and 3× Faster FLUX with 16-bit Quality on NVIDIA Blackwell GPUs: https://hanlab.mit.edu/blog/svdquant-nvfp4.
- M3 Ultra Runs DeepSeek R1 With 671 Billion Parameters Using 448GB Of Unified Memory, Delivering High Bandwidth Performance At Under 200W Power Consumption, With No Need For A Multi-GPU Setup: https://wccftech.com/m3-ultra-chip-handles-deepseek-r1-model-with-671-billion-parameters/.
- NVIDIA TensorRT Model Optimizer: https://github.com/NVIDIA/TensorRT-Model-Optimizer. A Library to Quantize and Compress Deep Learning Models for Optimized Inference on GPUs.































