
Ecosystem

OpenVINO.GenAI Delivers C API for Seamless Language Interop with Practical Examples in .NET
Authors: Tong Qiu, Xiake Sun
Starting with OpenVINO.GenAI 2025.1, the C API has been introduced, primarily to enhance interoperability with other programming languages, enabling developers to more effectively utilize OpenVINO-based generative AI across diverse coding environments.
Compared to C++, C's ABI is more stable, often serving as an interface layer or bridge language for cross-language interoperability and integration. This allows developers to leverage the performance benefits of C++ in the backend while using other high-level languages for easier implementation and integration.
As a milestone, we have currently delivered only the LLMPipeline and its associated C API interface. If you have other requirements or encounter any issues during usage, please submit an issue to OpenVINO.GenAI
Currently, we have implemented a Go application Ollama using the C API (Please refer to https://blog.openvino.ai/blog-posts/ollama-integrated-with-openvino-accelerating-deepseek-inference), which includes more comprehensive features such as performance benchmarking for developers reference.
Now, let's dive into the design logic of the C API, using a .NET C# example as a case study, based on the Windows platform with .NET 8.0.
Live Demo
Before we dive into the details, let's take a look at the final C# version of the ChatSample, which supports multi-turn conversations. Below is a live demo
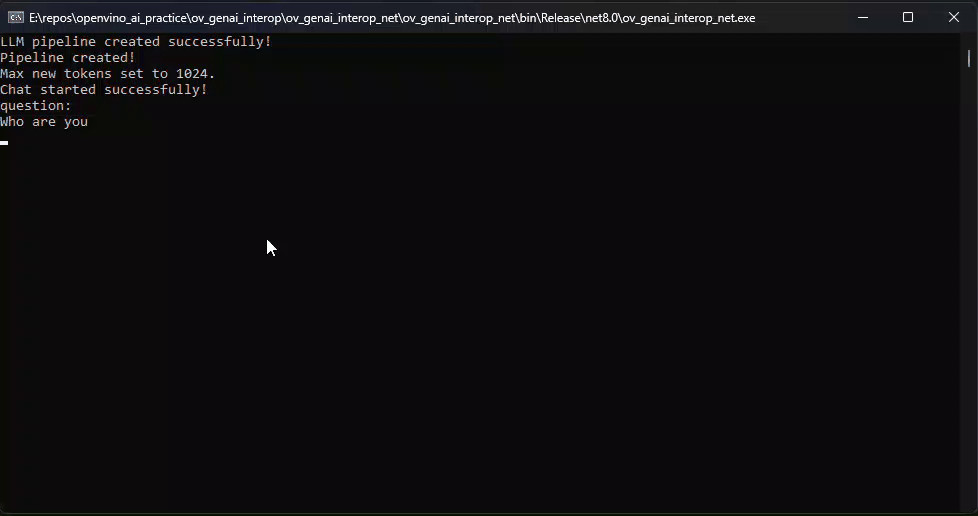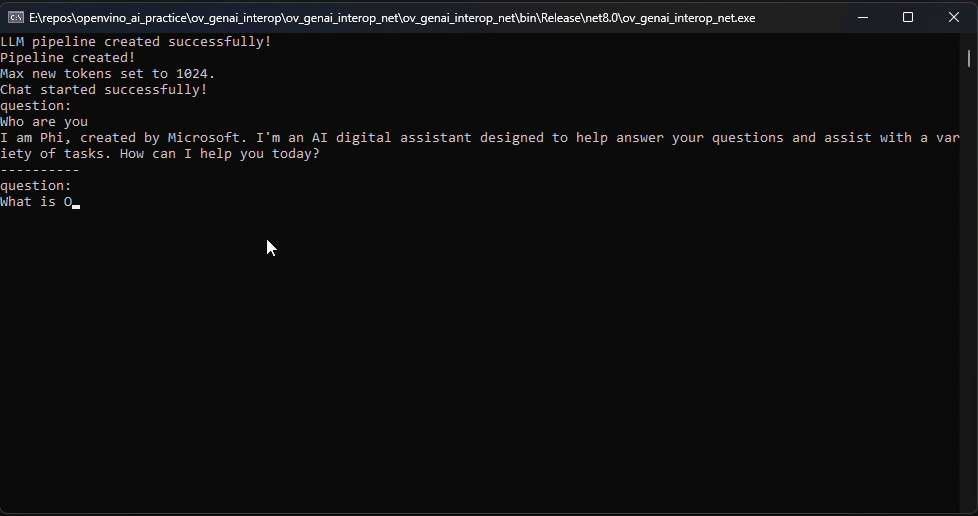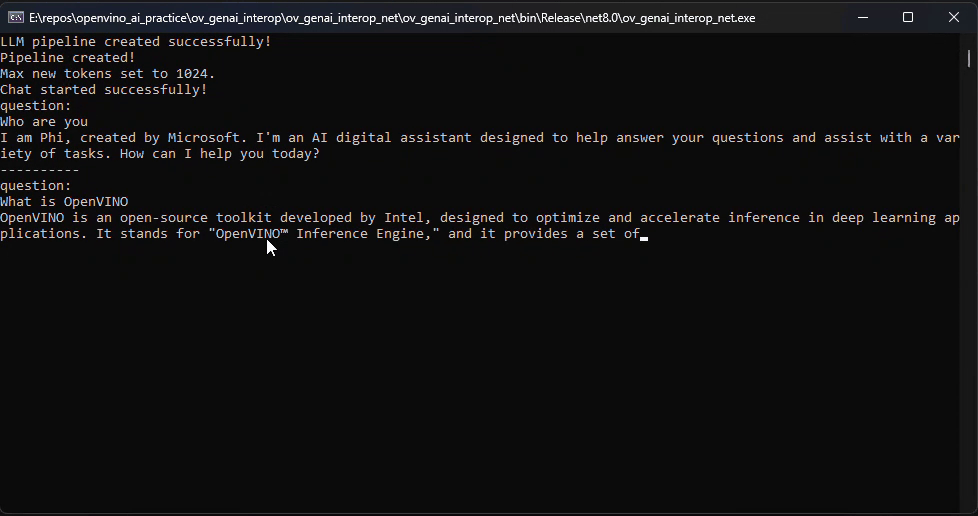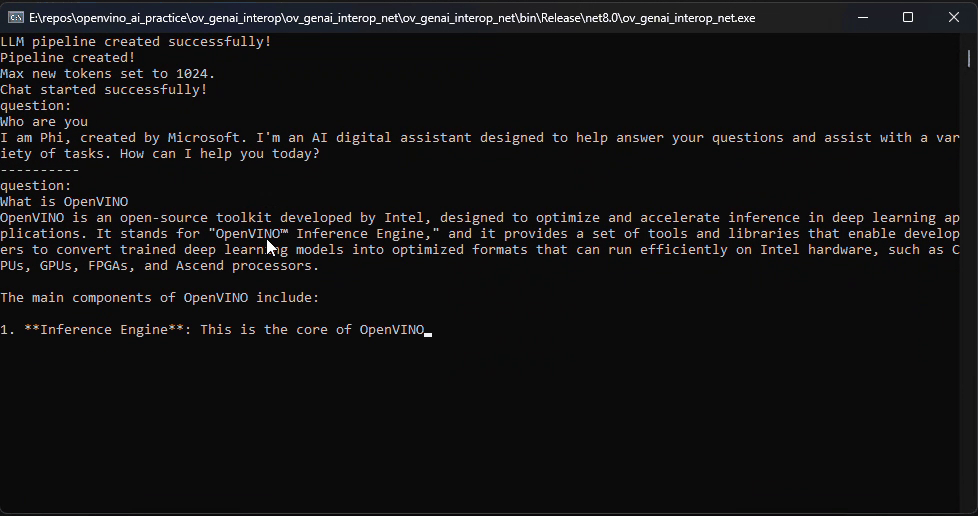
How to Build a Chat Sample by C#
P/Invoke: Wrapping Unmanaged Code in .NET
First, the official GenAI C API can be found in this folder https://github.com/openvinotoolkit/openvino.genai/tree/master/src/c/include/openvino/genai/c . We also provide several pure C samples https://github.com/openvinotoolkit/openvino.genai/tree/master/samples/c/text_generation . Now, we will build our own C# Chat Sample based on the chat_sample_c. This sample can facilitate multi-turn conversations with the LLM.
C# can access structures, functions and callbacks in the unmanaged library openvino_genai_c.dll through P/Invoke. This example demonstrates how to invoke unmanaged functions from managed code.
public static class NativeMethods
{
DllImport("openvino_genai_c.dll", CallingConvention = CallingConvention.Cdecl)]
public static extern ov_status_e ov_genai_llm_pipeline_create(
[MarshalAs(UnmanagedType.LPStr)] string models_path,
[MarshalAs(UnmanagedType.LPStr)] string device,
out IntPtr pipe);
[DllImport("openvino_genai_c.dll", CallingConvention = CallingConvention.Cdecl)]
public static extern void ov_genai_llm_pipeline_free(IntPtr pipeline);
//Other methods
The dynamic library openvino_genai_c.dll is imported, which relies on openvino_genai.dll. CallingConvention = CallingConvention.Cdecl here corresponds to the default calling convention _cdecl in C, which defines the argument-passing order, stack-maintenance responsibility, and name-decoration convention. For more details, refer to Argument Passing and Naming Conventions.
Additionally, the return value ov_status_e reuses an enum type from openvino_c.dll to indicate the execution status of the function. We need to implement a corresponding enum type in C#, such as
public enum ov_status_e
{
OK = 0,
GENERAL_ERROR = -1,
NOT_IMPLEMENTED = -2,
//...
}
Next, we will implement our C# LLMPipeline, which inherits the IDisposable interface. This means that its instances require cleanup after use to release the unmanaged resources they occupy. In practice, object allocation and deallocation for native pointers are handled through the C interface provided by OpenVINO.GenAI. The OpenVINO.GenAI library takes full responsibility for memory management, which ensures memory safety and eliminates the risk of manual memory errors.
public class LlmPipeline : IDisposable
{
private IntPtr _nativePtr;
public LlmPipeline(string modelPath, string device)
{
var status = NativeMethods.ov_genai_llm_pipeline_create(modelPath, device, out _nativePtr);
if (_nativePtr == IntPtr.Zero || status != ov_status_e.OK)
{
Console.WriteLine($"Error: {status} when creating LLM pipeline.");
throw new Exception("Failed to create LLM pipeline.");
}
Console.WriteLine("LLM pipeline created successfully!");
}
public void Dispose()
{
if (_nativePtr != IntPtr.Zero)
{
NativeMethods.ov_genai_llm_pipeline_free(_nativePtr);
_nativePtr = IntPtr.Zero;
}
GC.SuppressFinalize(this);
}
// Other Methods
}
Callback Implementation
Next, let's implement the most complex method of the LLMPipeline, the GenerateStream method. This method encapsulates the LLM inference process. Let's take a look at the original C code. The result can be retrieved either via ov_genai_decoded_results or streamer_callback. ov_genai_decoded_results provides the inference result all at once, while streamer_callback allows for streaming inference results. ov_genai_decoded_results or streamer_callback must be non-NULL; neither can be NULL at the same time. For more information please refer to the comments https://github.com/openvinotoolkit/openvino.genai/blob/master/src/c/include/openvino/genai/c/llm_pipeline.h
// code snippets from //https://github.com/openvinotoolkit/openvino.genai/blob/master/src/c/include/openvino/genai/c/llm_// pipeline.h
typedef enum {
OV_GENAI_STREAMMING_STATUS_RUNNING = 0, // Continue to run inference
OV_GENAI_STREAMMING_STATUS_STOP =
1, // Stop generation, keep history as is, KV cache includes last request and generated tokens
OV_GENAI_STREAMMING_STATUS_CANCEL = 2 // Stop generate, drop last prompt and all generated tokens from history, KV
// cache includes history but last step
} ov_genai_streamming_status_e;
// ...
typedef struct {
ov_genai_streamming_status_e(
OPENVINO_C_API_CALLBACK* callback_func)(const char* str, void* args); //!< Pointer to the callback function
void* args; //!< Pointer to the arguments passed to the callback function
} streamer_callback;
// ...
OPENVINO_GENAI_C_EXPORTS ov_status_e ov_genai_llm_pipeline_generate(ov_genai_llm_pipeline* pipe,
const char* inputs,
const ov_genai_generation_config* config,
const streamer_callback* streamer,
ov_genai_decoded_results** results);
The streamer_callback structure includes not only the callback function itself, but also an additional void* args for enhanced flexibility. This design allows developers to pass custom context or state information to the callback.
For example, in C++ it's common to pass a this pointer through args, enabling the callback function to access class members or methods when invoked.
// args is a this pointer
void callback_func(const char* str, void* args) {
MyClass* self = static_cast<MyClass*>(args);
self->DoSomething();
}
This C# code defines a class StreamerCallback that helps connect a C callback function with a C# method. It wraps a C function pointer MyCallbackDelegate and a void* args into a struct.
- ToNativePTR method constructs the streamer_callback structure, allocates a block of memory, and copies the structure's data into it, allowing it to be passed to a native C function.
- GCHandle is used to safely pin the C# object so that it can be passed as a native pointer to unmanaged C code.
- CallbackWrapper method is the actual function that C code will call.
[UnmanagedFunctionPointer(CallingConvention.Cdecl)]
public delegate ov_genai_streamming_status_e MyCallbackDelegate(IntPtr str, IntPtr args);
[StructLayout(LayoutKind.Sequential)]
public struct streamer_callback
{
public MyCallbackDelegate callback_func;
public IntPtr args;
}
public class StreamerCallback : IDisposable
{
public Action<string> OnStream;
public MyCallbackDelegate Delegate;
private GCHandle _selfHandle;
public StreamerCallback(Action<string> onStream)
{
OnStream = onStream;
Delegate = new MyCallbackDelegate(CallbackWrapper);
_selfHandle = GCHandle.Alloc(this);
}
public IntPtr ToNativePtr()
{
var native = new streamer_callback
{
callback_func = Delegate,
args = GCHandle.ToIntPtr(_selfHandle)
};
IntPtr ptr = Marshal.AllocHGlobal(Marshal.SizeOf<streamer_callback>());
Marshal.StructureToPtr(native, ptr, false);
return ptr;
}
public void Dispose()
{
if (_selfHandle.IsAllocated)
_selfHandle.Free();
}
private ov_genai_streamming_status_e CallbackWrapper(IntPtr str, IntPtr args)
{
string content = Marshal.PtrToStringAnsi(str) ?? string.Empty;
if (args != IntPtr.Zero)
{
var handle = GCHandle.FromIntPtr(args);
if (handle.Target is StreamerCallback self)
{
self.OnStream?.Invoke(content);
}
}
return ov_genai_streamming_status_e.OV_GENAI_STREAMMING_STATUS_RUNNING;
}
}
Then We implemented the GenerateStream method in class LLMPipeline.
public void GenerateStream(string input, GenerationConfig config, StreamerCallback? callback = null)
{
IntPtr configPtr = config.GetNativePointer();
IntPtr decodedPtr;// placeholder
IntPtr streamerPtr = IntPtr.Zero;
if (callback != null)
{
streamerPtr = callback.ToNativePtr();
}
var status = NativeMethods.ov_genai_llm_pipeline_generate(
_nativePtr,
input,
configPtr,
streamerPtr,
out decodedPtr
);
if (streamerPtr != IntPtr.Zero)
Marshal.FreeHGlobal(streamerPtr);
callback?.Dispose();
if (status != ov_status_e.OK)
{
Console.WriteLine($"Error: {status} during generation.");
throw new Exception("Failed to generate results.");
}
return;
}
We use the following code to invoke our callback and GenerateStream.
pipeline.StartChat(); // Start chat with keeping history in kv cache.
Console.WriteLine("question:");
while (true)
{
string? input = Console.ReadLine();
if (string.IsNullOrWhiteSpace(input)) break;
using var streamerCallback = new StreamerCallback((string chunk) =>
{
Console.Write(chunk);
});
pipeline.GenerateStream(input, generationConfig, streamerCallback);
input = null;
Console.WriteLine("\n----------\nquestion:");
}
pipeline.FinishChat(); // Finish chat and clear history in kv cache.
About Deployment
We can directly download the OpenVINO official release of the LLM's IR from Hugging Face using this link.
git clone https://huggingface.co/OpenVINO/Phi-3.5-mini-instruct-int8-ov
The OpenVINO.GenAI 2025.1 package can be downloaded via this link.
The C# project directly depends on openvino_genai_c.dll, which in turn has transitive dependencies on other toolkit-related DLLs, including Intel TBB libraries.
To ensure proper runtime behavior, all the DLLs delivered with OpenVINO.GenAI — including openvino_genai_c.dll and its dependencies — are bundled and treated as part of the C# project’s runtime dependencies.
We use the following cmd commands to download the genai package and copy all the required dependent DLLs to the directory containing the *.csproj file.
curl -O https://storage.openvinotoolkit.org/repositories/openvino_genai/packages/2025.1/windows/openvino_genai_windows_2025.1.0.0_x86_64.zip
tar -xzvf openvino_genai_windows_2025.1.0.0_x86_64.zip
xcopy /y openvino_genai_windows_2025.1.0.0_x86_64\runtime\bin\intel64\Release\*.dll "C:\path\to\ChatSample\"
xcopy /y openvino_genai_windows_2025.1.0.0_x86_64\runtime\3rdparty\tbb\bin\*.dll "C:\path\to\ChatSample\"
Full Implementation
Please refer to https://github.com/apinge/openvino_ai_practice/tree/main/ov_genai_interop/ov_genai_interop_net, to access the full implementation.
Ollama Integrated with OpenVINO, Accelerating DeepSeek Inference
Authors: Hongbo Zhao, Fiona Zhao, Tong Qiu
Why Choose the Ollama + OpenVINO Combination?
Dual-Engine Driven Technical Advantages
The integration of Ollama and OpenVINO delivers a powerful dual-engine solution for the management and inference of large language models (LLMs). Ollama offers a streamlined model management toolchain, while OpenVINO provides efficient acceleration capabilities for model inference across Intel hardware (CPU/GPU/NPU). This combination not only simplifies the deployment and invocation of models but also significantly enhances inference performance, making it particularly suitable for scenarios demanding high performance and ease of use.
You can find more information on github repository:
https://github.com/openvinotoolkit/openvino_contrib/tree/master/modules/ollama_openvino
Core Value of Ollama
1. Streamlined LLM Management Toolchain: Ollama provides a user-friendly command-line interface, enabling users to effortlessly download, manage, and run various LLM models.
2. One-Click Model Deployment: With simple commands, users can quickly deploy and invoke models without complex configurations.
3. Unified API Interface: Ollama offers a unified API interface, making it easy for developersto integrate into various applications.
4. Active Open-Source Community: Ollama boasts a vibrant open-source community, providing users with abundant resources and support.
Limitations of Ollama
Currently, Ollama only supports llama.cpp as itsbackend, which presents some inconveniences:
1. Limited Hardware Compatibility: llama.cpp is primarily optimized for CPUs and NVIDIA GPUs, and cannot fully leverage the acceleration capabilities of Intel GPUs or NPUs, resulting in suboptimal performance in high-performance computing scenarios.
2. Performance Bottlenecks: For large-scale models or high-concurrency scenarios, the performance of llama.cpp may fall short, especially when handling complex tasks, leading to slower inference speeds.
Breakthrough Capabilities of OpenVINO
1. Deep Optimization for Intel Hardware (CPU/iGPU/Arc dGPU/NPU): OpenVINO is deeply optimized for Intel hardware, fully leveraging the performance potential of CPUs, iGPUs, dGPUs, and NPUs.
2. Cross-Platform Heterogeneous Computing Support: OpenVINO supports cross-platform heterogeneous computing, enabling efficient model inference across different hardware platforms.
3. Model Quantization and Compression Toolchain: OpenVINO provides a comprehensive toolchain for model quantization and compression, significantly reducing model size and improving inference speed.
4. Significant Inference Performance Improvement: Through OpenVINO's optimizations, model inference performance can be significantly enhanced, especially for large-scale models and high-concurrency scenarios.
5. Extensibility and Flexibility Support: OpenVINO GenAI offers robust extensibility and flexibility for Ollama-OV, supporting pipeline optimization techniques such as speculative decoding, prompt-lookup decoding, pipeline parallelization, and continuous batching, laying a solid foundation for future pipeline serving optimizations.
Developer Benefits of Integration
1. Simplified Development Experience: Retains Ollama's CLI interaction features, allowing developers to continue using familiar command-line tools for model management and invocation.
2. Performance Leap: Achieves hardware-level acceleration through OpenVINO, significantly boosting model inference performance, especially for large-scale models and high-concurrency scenarios.
3. Multi-Hardware Adaptation and Ecosystem Expansion: OpenVINO's support enables Ollama to adapt to multiple hardware platforms, expanding its application ecosystem and providing developers with more choices and flexibility.
Three Steps to Enable Acceleration
1. Download Precompiled Executables
please refer to : https://github.com/zhaohb/ollama_ov/tree/main?tab=readme-ov-file#google-driver
2.Configure OpenVINO GenAI Environment
For Windows systems, first extract the downloaded OpenVINO GenAI package to the directory openvino_genai_windows_2025.2.0.0.dev20250320_x86_64, then execute the following commands:
cd openvino_genai_windows_2025.2.0.0.dev20250320_x86_64
setupvars.bat
3. Set Up cgocheck
Windows:
set GODEBUG=cgocheck=0
Linux:
export GODEBUG=cgocheck=0
At this point, the executable files have been downloaded, and the OpenVINO GenAI, OpenVINO, and CGO environments have been successfully configured.
Custom Model Deployment Guide
Since the Ollama Model Library does not support uploading non-GGUF format IR models, we will create an OCI image locally using OpenVINO IR that is compatible with Ollama. Here, we use the DeepSeek-R1-Distill-Qwen-7B model as an example:
1. Download the OpenVINO IR Model
Download the model from ModelScope:
pip install modelscope
modelscope download --model zhaohb/DeepSeek-R1-Distill-Qwen-7B-int4-ov --local_dir ./DeepSeek-R1-Distill-Qwen-7B-int4-ov2. Package the Downloaded OpenVINO IR Directory
Compress the directory into a *.tar.gz file:
tar -zcvf DeepSeek-R1-Distill-Qwen-7B-int4-ov.tar.gz DeepSeek-R1-Distill-Qwen-7B-int4-ov3. Create a Modelfile
Define the model configuration in a Modelfile:
FROM DeepSeek-R1-Distill-Qwen-7B-int4-ov.tar.gz
ModelType "OpenVINO"
InferDevice "GPU"
PARAMETER stop ""
PARAMETER stop "```"
PARAMETER stop "</User|>"
PARAMETER stop "<|end_of_sentence|>"
PARAMETER stop "</|"
PARAMETER max_new_token 4096
PARAMETER stop_id 151643
PARAMETER stop_id 151647
PARAMETER repeat_penalty 1.5
PARAMETER top_p 0.95
PARAMETER top_k 50
PARAMETER temperature 0.84. Create an Ollama-Compatible Model
Use the Modelfile to create a model supported by Ollama:
ollama create DeepSeek-R1-Distill-Qwen-7B-int4-ov:v1 -f Modelfile
With these steps, we have successfully created the DeepSeek-R1-Distill-Qwen-7B-int4-ov:v1 model, which is now ready for use with the Ollama OpenVINO backend.
InternVL2-4B model enabling with OpenVINO
Authors: Hongbo Zhao, Fiona Zhao
Introduction
InternVL2.0 is a series of multimodal large language models available in various sizes. The InternVL2-4B model comprises InternViT-300M-448px, an MLP projector, and Phi-3-mini-128k-instruct. It delivers competitive performance comparable to proprietary commercial models across a range of capabilities, including document and chart comprehension, infographics question answering, scene text understanding and OCR tasks, scientific and mathematical problem solving, as well as cultural understanding and integrated multimodal functionalities.
You can find more information on github repository: https://github.com/zhaohb/InternVL2-4B-OV
OpenVINOTM backend on InternVL2-4B
Step 1: Install system dependency and setup environment
Create and enable python virtual environment
conda create -n ov_py310 python=3.10 -y
conda activate ov_py310Clone the InternVL2-4B-OV repository from github
git clonehttps://github.com/zhaohb/InternVL2-4B-OV
cd InternVL2-4B-OVInstall python dependency
pip install -r requirement.txt
pip install --pre -U openvino openvino-tokenizers --extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightlyStep2: Get HuggingFace model
huggingface-cli download --resume-download OpenGVLab/InternVL2-4B --local-dir InternVL2-4B--local-dir-use-symlinks False
cp modeling_phi3.py InternVL2-4B/modeling_phi3.py
cp modeling_intern_vit.py InternVL2-4B/modeling_intern_vit.pyStep 3: Export to OpenVINO™ model
python test_ov_internvl2.py -m ./InternVL2-4B -ov ./internvl2_ov_model -llm_int4_com -vision_int8 -llm_int8_quan -convert_model_only
Step4: Simple inference test with OpenVINO™
python test_ov_internvl2.py -m ./InternVL2-4B -ov ./internvl2_ov_model -llm_int4_com -vision_int8-llm_int8_quanQuestion: Please describe the image shortly.

Answer:
The image features a close-up view of a red panda resting on a wooden platform. The panda is characterized by its distinctive red fur, white face, and ears. The background shows a natural setting with green foliage and a wooden structure.
Here are the parameters with descriptions:
python test_ov_internvl2.py --help
usage: Export InternVL2 Model to IR [-h] [-m MODEL_ID] -ov OV_IR_DIR [-d DEVICE] [-pic PICTURE] [-p PROMPT] [-max MAX_NEW_TOKENS] [-llm_int4_com] [-vision_int8] [-llm_int8_quant] [-convert_model_only]
options:
-h, --help show this help message and exit
-m MODEL_ID, --model_id MODEL_ID model_id or directory for loading
-ov OV_IR_DIR, --ov_ir_dir OV_IR_DIR output directory for saving model
-d DEVICE, --device DEVICE inference device
-pic PICTURE, --picture PICTURE picture file
-p PROMPT, --prompt PROMPT prompt
-max MAX_NEW_TOKENS, --max_new_tokens MAX_NEW_TOKENS max_new_tokens
-llm_int4_com, --llm_int4_compress llm int4 weight scompress
-vision_int8, --vision_int8_quant vision int8 weights quantize
-llm_int8_quant, --llm_int8_quant llm int8 weights dynamic quantize
-convert_model_only, --convert_model_only convert model to ov only, do not do inference testSupported optimizations
1. Vision model INT8 quantization and SDPA optimization enabled
2. LLM model INT4 compression
3. LLM model INT8 dynamic quantization
4. LLM model with SDPA optimization enabled
Summary
This blog introduces how to use the OpenVINO™ python API to run the pipeline of the Internvl2-4B model, and uses a variety of acceleration methods to improve the inference speed.
moondream2 model enabling with OpenVINO
Introduction
moondream2 is a small vision language model designed to run efficiently on edge devices. Although the model has a small number of parameters, it provides high-performance visual processing capabilities. It can quickly understand and process input images and respond to user queries. The model was developed by VikhyatK and is released under the permissive Apache 2.0 license, allowing for commercial use.
You can find more information on github repository: https://github.com/zhaohb/moondream2-ov
OpenVINOTM backend on moondream2
Step 1: Install system dependency and setup environment
Create and enable python virtual environment
conda create -n ov_py310 python=3.10 -y
conda activate ov_py310
Clone themoondream2-ov repository from gitHub
git clone https://github.com/zhaohb/moondream2-ov
cd moondream2-ov
Install python dependency
pip install -r requirement.txt
pip install --pre -U openvino openvino-tokenizers --extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightly
Step 2: Get HuggingFace model
git lfs install
git clone https://hf-mirror.com/vikhyatk/moondream2
git checkout 48be9138e0faaec8802519b1b828350e33525d46
Step 3: Export OpenVINO™ models and simple inference test with OpenVINO™
python3 test_ov_moondream2.py -m /path/to/moondream2 -o /path/to/moondream2_ov
Question: Describe this image.

Answer:
The image shows a modern white desk with a laptop, a lamp, and a notebook on it, set against a gray wall and a wooden floor.
Accelerate Inference of Hugging Face Transformer Models with Optimum Intel and OpenVINO™
Authors: Xiake Sun, Kunda Xu
1. Introduction

Hugging Face is a large open-source community that quickly became an enticing hub for pre-trained deep learning models across Natural Language Processing (NLP), Automatic Speech Recognition(ASR), and Computer Vision (CV) domains.
Optimum Intel provides a simple interface to optimize Transformer models and convert them to OpenVINO™ Intermediate Representation (IR) format to accelerate end-to-end pipelines on Intel® architectures using OpenVINO™ runtime.
Sentimental classification, as one of the popular NLP tasks, is the automated process of identifying opinions in the text and labeling them as positive or negative. In this blog, we use DistilBERT for the sentimental classification task as an example to show how Optimum Intel helps to optimize the model with Neural Network Compression Framework (NNCF) and accelerate inference with OpenVINO™ runtime.
2. Setup Environment
Install optimum-intel and its dependency in a new python virtual environment as follow:
3. Model Inference with OpenVINO™ Runtime
The Optimum inference models are API compatible with Hugging Face Transformers models; which means you could simply replace Hugging Face Transformer “AutoModelXXX” class with the “OVModelXXX” class to switch model inference with OpenVINO™ runtime. You could set “from_transformers=True” when loading the model with the from_pretrained() method, the loaded model will be automatically converted to an OpenVINO™ IR for inference with OpenVINO™ runtime.
Here is an example of how to perform inference with OpenVINO™ runtime for a sentimental classification task, the output of the pipeline consists of classification label (positive/negative) and corresponding confidence.
4. Model Quantization with NNCF framework
Most deep learning models are built using 32 bits floating-point precision (FP32). Quantization is the process to represent the model using less memory with minimal accuracy loss. To further optimize model performance on Intel® architecture via Intel® Deep Learning Boost, model quantization as 8 bits integer precision (INT8) is required.
Optimum Intel enables you to apply quantization on Hugging Face Transformer Models using the NNCF. NNCF provides two mainstream quantization methods - Post-Training Quantization (PTQ) and Quantization-Aware Training (QAT).
- Post-Training Quantization (PTQ) refers to quantizing a model with a representative calibration dataset without fine-tuning.
- Quantization-Aware Training (QAT) is applied to simulate the effects of quantization during training to mitigate its effect on the model’s accuracy
4.1. Model Quantization with NNCF PTQ
NNCF Post-training static quantization introduces an additional calibration step where data is fed through the network to compute the activations quantization parameters. Here is how to apply static quantization on a pre-trained DistilBERT using General Language Understanding Evaluation (GLUE) dataset as the calibration dataset:
The quantize() method applies post-training static quantization and export the resulting quantized model to the OpenVINO™ Intermediate Representation (IR), which can be deployed on any target Intel® architecture.
4.2. Model Quantization with NNCF QAT
Quantization-Aware Training (QAT) aims to mitigate model accuracy issue by simulating the effects of quantization during training. If post-training quantization results in accuracy degradation, QAT can be used instead.
NNCF provides an “OVTrainer” class to replace Hugging Face Transformer’s “Trainer” class to enable quantization during training with additional quantization configuration. Here is an example on how to fine-tune a DistilBERT with Stanford Sentiment Treebank (SST) dataset while applying quantization aware training (QAT):
4.3. Comparison of FP32 and INT8 model outputs
“OVModelForXXX” class provided the same API to load FP32 and quantized INT8 OpenVINO™ models by setting “from_transformers=False”. Here is an example of how to load quantized INT8 models optimized by NNCF and inference with OpenVINO™ runtime.
Here is an example for sentimental classification output of FP32 and INT8 models:

5. Mitigation of accuracy issue cause by saturation
8-bit instructions of old CPU generations (based on SSE,AVX-2, AVX-512 instruction sets) are prone to so-called saturation(overflow) of the intermediate buffer when calculating the dot product, which is an essential part of Convolutional or MatMul operations. This saturation can lead to a drop in accuracy when running inference of 8-bit quantized models on the mentioned architectures. The problem does not occur on GPUs or CPUs with Intel® Deep Learning Boost (VNNI) technology and further generations.
In the case a significant difference in accuracy (>1%) occurs after quantization with NNCF default quantization configuration, here is an example code to check if deployed platform supports Intel® Deep Learning Boost (VNNI) and further generations:
While quantizing activations use the full range of 8-bit data types, there is a workaround using only 7 bits to represent weights (of Convolutional or Fully-Connected layers) to mitigate saturation issue for many models on old CPU platform.
NNCF provides three options to deal with the saturation issue. The options can be enabled in the NNCF quantization configuration using the “overflow_fix” parameter:
- "disable": (default) option do not apply saturation fix at all
- "enable": option to apply for all layers in the model
- "first_layer_only": option to fix saturation issue for the first layer
Here is an example to enable overflow fix in quantization configuration to mitigate accuracy issue on old CPU platform:
After model quantization with updated quantization configuration with NNCF PTQ/NNCF, you can repeat step 4.3 to verify if quantized INT8 model inference results are consistent with FP32 model outputs.
Additional Resources
Provide Feedback & Report Issues
Notices & Disclaimers
Intel technologies may require enabled hardware, software, or service activation.
No product or component can be absolutely secure.
Your costs and results may vary.
Intel does not control or audit third-party data. You should consult other sources to evaluate accuracy.
Intel disclaims all express and implied warranties, including without limitation, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement, as well as any warranty arising from course of performance, course of dealing, or usage in trade.
No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document.
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.