
Natural Language Processing

Deploy Language Models with OpenVINO™ Model Server
Authors: Dariusz Trawinski, Damian Kalinowski
Overview
If you are writing an AI application that handles text in Natural Language Processing (NLP) models, you will be pleased to hear that OpenVINO Model Server now supports sending and receiving text in string format.
Now you can combine optimized inference execution with a simple method for sending text data to the model server and reading text responses.
Introduction
Deep Learning models do not deal with text content directly. Instead, they require a numerical representation of text to process it.

The conversion from human readable text to a machine-readable format is done via a process of tokenization and encoding. Without going into the specifics of tokenization and encoding, these operations are not trivial. Many algorithms exist for these tasks and most often the operation is run by dedicated software libraries.
Generally, during the inference operation, a client application must reproduce the same method for text tokenization and encoding, similar to what is used during the model training phase.
For reference, below are two examples showing how this can be implemented on the application side as pre- and post-processing steps:
In TensorFlow it’s also possible to embed the tokenization operation inside the model by adding a dedicated neuron model layer SentencePieceTokenizer.
Tokenization and Encoding with OpenVINO Model Server
Starting with the 2023.0 release, OpenVINO Model Server can greatly simplify writing applications that leverage LLM and NLP models. We addressed both using models that require tokens and models with an embedded tokenization layer. Both use cases are demonstrated below with a simple client application that sends and receives text in a string format. The complexity of text conversion is fully delegated to the remote serving endpoint.
GPT-J Pipeline
In this demo we deploy the tokenizer as a custom node in OpenVINO Model Server. As a result, we get a pipeline with seed strings as input and generated texts as the output.
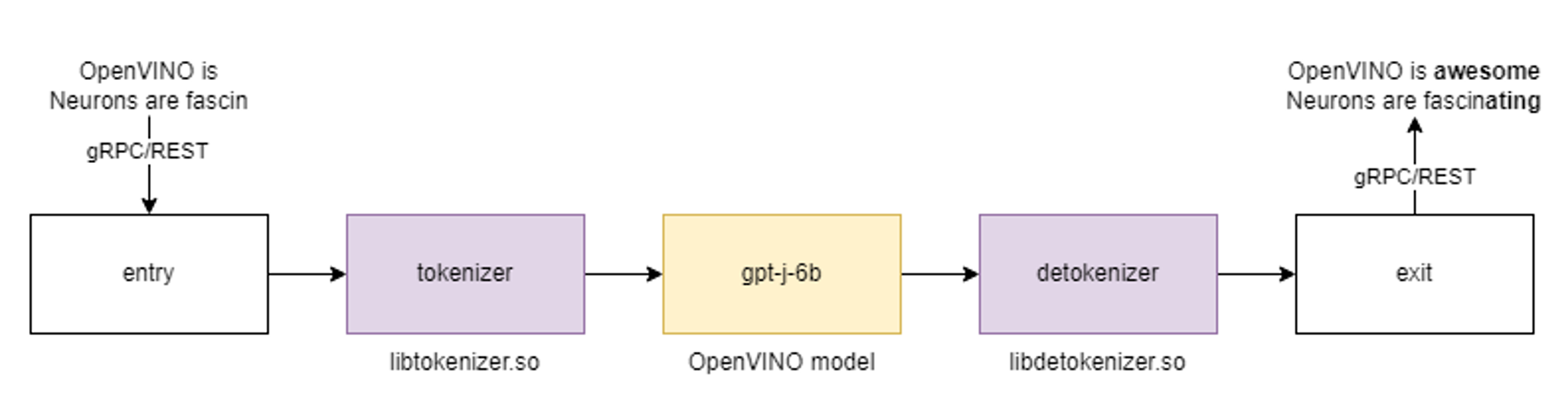
All steps to reproduce the demo above are documented here: https://docs.openvino.ai/2023.0/ovms_demo_gptj_causal_lm.html
Text generation can be executed iteratively in a loop. An example of the client application generating text output is shown below.

Multilingual Universal Sentence Encoder (MUSE)
The next demonstration includes serving the MUSE model from TensorFlow Hub. The demo shows how OpenVINO Model Server can be used to serve the MUSE model and with 2x better performance without any changes on the client side.
The calls to the model server are simple using a REST API. Below is an example of a call with a batch size 3.
A similar call can be made over gRPC interface using the ovmsclient library which is compatible with the TensorFlow Serving (TFS) API.
In addition to the TFS API, it is also possible to run inference calls using the KServe v2 API. Check the code snippets for more details.
Conclusion
OpenVINO Model Server can simplify writing AI applications that handle text. It can execute a complete text analysis pipeline with just few[TA4] lines of code on the client side without compromising performance by using a tokenizer in C++ and high performance OpenVINO backend to run the AI models. Together with widely used, standard APIs, OpenVINO Model Server is a great solution for deploying effective and efficient AI applications.
References
https://towardsdatascience.com/tokenization-algorithms-explained-e25d5f4322ac
https://www.tensorflow.org/api_docs/python/tfm/nlp/layers/SentencepieceTokenizer
https://docs.openvino.ai/2023.0/ovms_what_is_openvino_model_server.html
https://docs.openvino.ai/2023.0/openvino_docs_performance_benchmarks.html
Joint Pruning, Quantization and Distillation for Efficient Inference of Transformers
Introduction
Pre-trained transformer models are widely deployed for various NLP tasks such as text classification, question answering, and generation task. The recent trend is that models continue to scale while yielding improved performance. However, growth of transformers also leads to great amount of compute resources and energy needed for deployment. The goal of model compression is to achieve model simplification from the original without significantly diminished accuracy. Pruning, quantization, and knowledge distillation are the three most popular model compression techniques for deep learning models. Pruning is a technique for reducing the size of a model to improve efficiency or performance. By reducing the number of bits needed to represent data, quantization can significantly reduce storage and computational requirements. Knowledge distillation involves training a small model to imitate the behavior of a larger model.
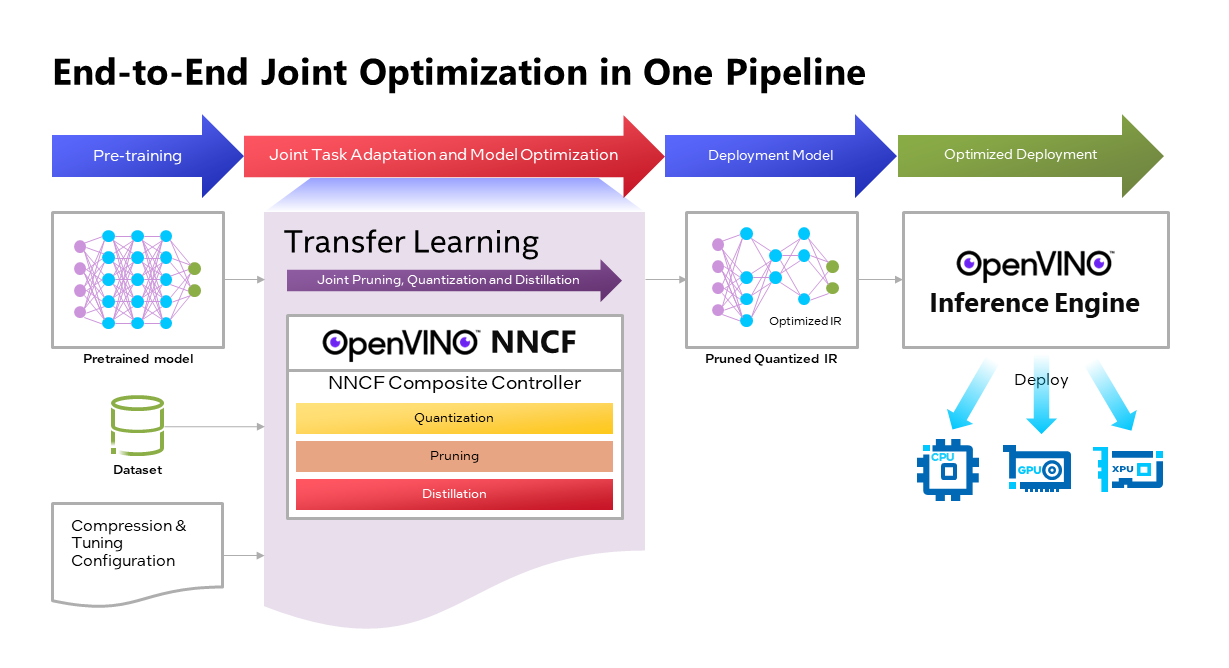
OpenVINOTM Neural Network Compression Framework (NNCF) develops Joint Pruning, Quantization and Distillation (JPQD) as a single joint-optimization pipeline to improve transformer inference performance by pruning, quantization, and distillation in parallel during transfer learning of a pretrained transformer. JPQD alleviates the developer complexity of sequential optimization of different compression techniques, resulting in an optimized model with significant efficiency improvement while preserving good task accuracy. The output of JPQD is a structurally pruned, quantized model in OpenVINOTM IR, which is ready to deploy with OpenVINOTM runtimes optimized on Intel platforms. Optimum intel provides simple API to integrate JPQD into training pipeline for Hugging Face Transformers.
JPQD of BERT-base Model with Optimum Intel
In this blog, we introduce how to apply JPQD to BERT-base model on GLUE benchmark for SST-2 text classification task.
Here is a compression config example with the format that follows NNCF specifications. We specify pruning and quantization in a list of compression algorithms with hyperparameters. The pruning method closely resembles the work of Movement Pruning (Sanh et al., 2020) and Block Pruning For Faster Transformers (Lagunas et al., 2021) for unstructured and structured movement sparsity. Quantization refers to Quantization-aware Training (QAT), see details for QAT in previous blog. At the beginning of training, the model under optimization will be initialized with pruning and quantization operators with this configuration.
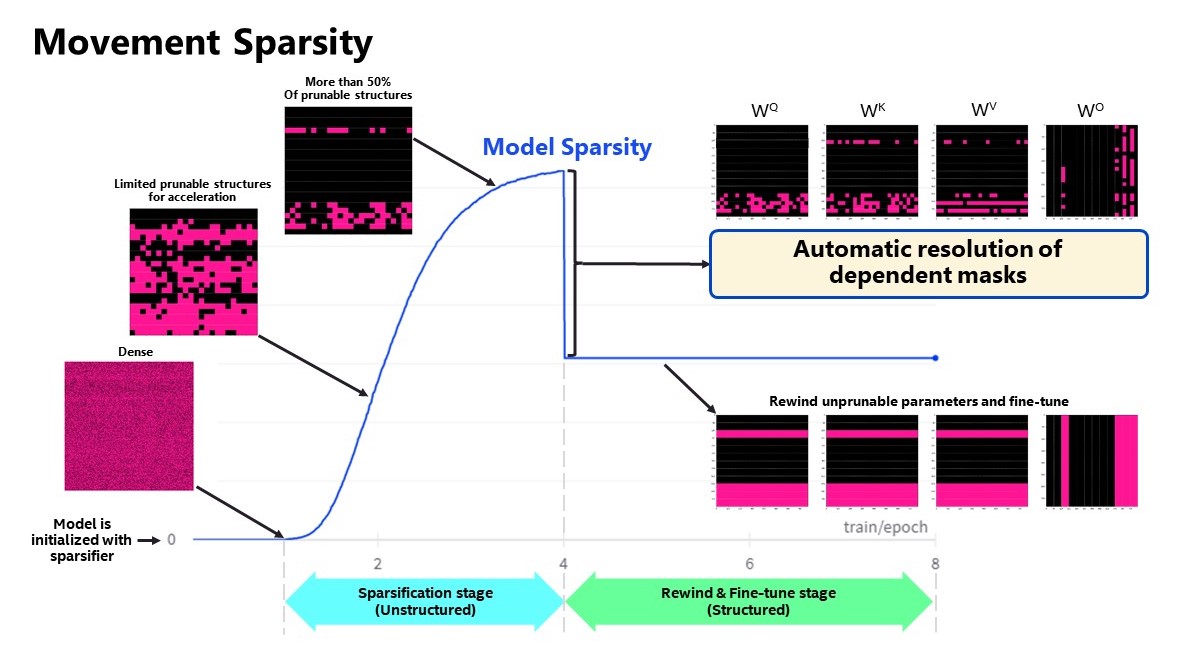
Figure 2 shows the sparsity level of BERT-base model over the optimization lifecycle, including two major stages:
- Unstructured sparsification: In the first stage, model weights are gradually sparsified in the grain size specified by "sparse_structure_by_scopes". The BertAttention layers (Multi-Head Attention: MHA) will be sparsified in 32x32 block size, while BertIntermediate, and BertOutput layers (Feed-Forward Network: FFN) will be sparsified in its row or column respectively. The first stage serves as a warmup stage defined by parameter “warmup_start_epoch” and “warmup_end_epoch”. The “importance_regularization_factor” defines regularization factor onweight importance scores. The factor stays zero before warmup stage, and gradually increases during warmup, finally stays at the fixed value after warmup, users might need some heuristics to find a satisfactory trade-off between sparsity and task accuracy.
- Structured masking and fine-tuning: The first warm-up stage will produce the unstructured sparsified model. Currently, unstructured sparsity optimized inference is only supported on 4th Gen Intel® Xeon® Scalable Processors with OpenVINO 2022.3 or a later version, for details, please refer to Accelerate Inference of Sparse Transformer Models with OpenVINO™ and 4th Gen Intel® Xeon®Scalable Processors. But it is possible to discard some sparse structure entirely from the model to save compute and memory footprint. NNCF provides a mechanism to achieve structured masking by “enable_structured_masking”: true, where it automatically resolves the structured masking between dependent layers and rewinds the sparsified parameters that do not participate in acceleration for task modeling. As Figure 2 shows, the sparsity level has dropped after “warmup_end_epoch” due to structured masking and the model will continue to be fine-tuned.
Known limitation: currently structured pruning with movement sparsity only supports BERT, Wav2vec2, and Swin family of models. See here for more information.
For distillation, the teacher model can be loaded with transformer API, e.g., a BERT-large pre-trained model from Hugging Face Hub. OVTrainingArguments extends transformers’ TrainingArguments with distillation hyperparameters, i.e., distillation weight and temperature for ease of use. The snippet below shows how we load a teacher model and create training arguments with OVTrainingArguments. Subsequently, the teacher model, with the instantiated OVConfig and OVTrainingArguments is fed to OVTrainer. The rest of the pipeline is identical to the native transformers' training, while internally the training is applied with pruning, quantization, and distillation.
Besides, NNCF provides JPQD examples of othertasks, e.g., question answering. Please refer to the examples provided here.
End-to-End JPQD of BERT-base Demo
Set up Python environment with necessary dependencies.
Run text classification example with JPQD of BERT on GLUE
All JPQD configurations and results are saved in ./jpqd-bert-base-ft-$TASK_NAME directory. Optimized OpenVINOTM IR is generated for efficient inference on intel platforms.
BERT-base Performance Evaluation and Accuracy Verification on Xeon

Table 1 shows BERT-base model for text classification task performance evaluation and accuracy verification results on 4th Gen Intel® Xeon® Scalable Processors. BERT-base FP32 model serves as the baseline. BERT-base INT8 (QAT) refers to the model optimized with the 8-bit quantization method only. BERT-base INT8 (JPQD) refers to the model optimized by pruning, quantization, and distillation method.
Here we use benchmark app with performance hint “throughput” to evaluate model performance with input sequence length=128.
As results shows, BERT-base INT8 (QAT) can already reach a 2.39x compression rate and 3.17x performance gain without significant accuracy drop (1.3%) on SST-2 compared with baseline. BERT-base INT8 (JPQD) can further increase compression rate to 5.24x to reach 4.19x performance improvement while keeping minimal accuracy drop (<1%) on SST-2 compared with baseline.

With proper fine-tuning, JPQD can even improve model accuracy while increasing performance in the meantime. Table 2 shows BERT-base model for question answering task performance evaluation and accuracy verification results on 4th Gen Intel® Xeon® Scalable Processors. BERT-base INT8 (JPQD) can increase compression rate to 5.15x to reach 4.25x performance improvement while improving Exact Match (1.35%) and F1 score (1.15%) metric on SQuAD compared with FP32 baseline.
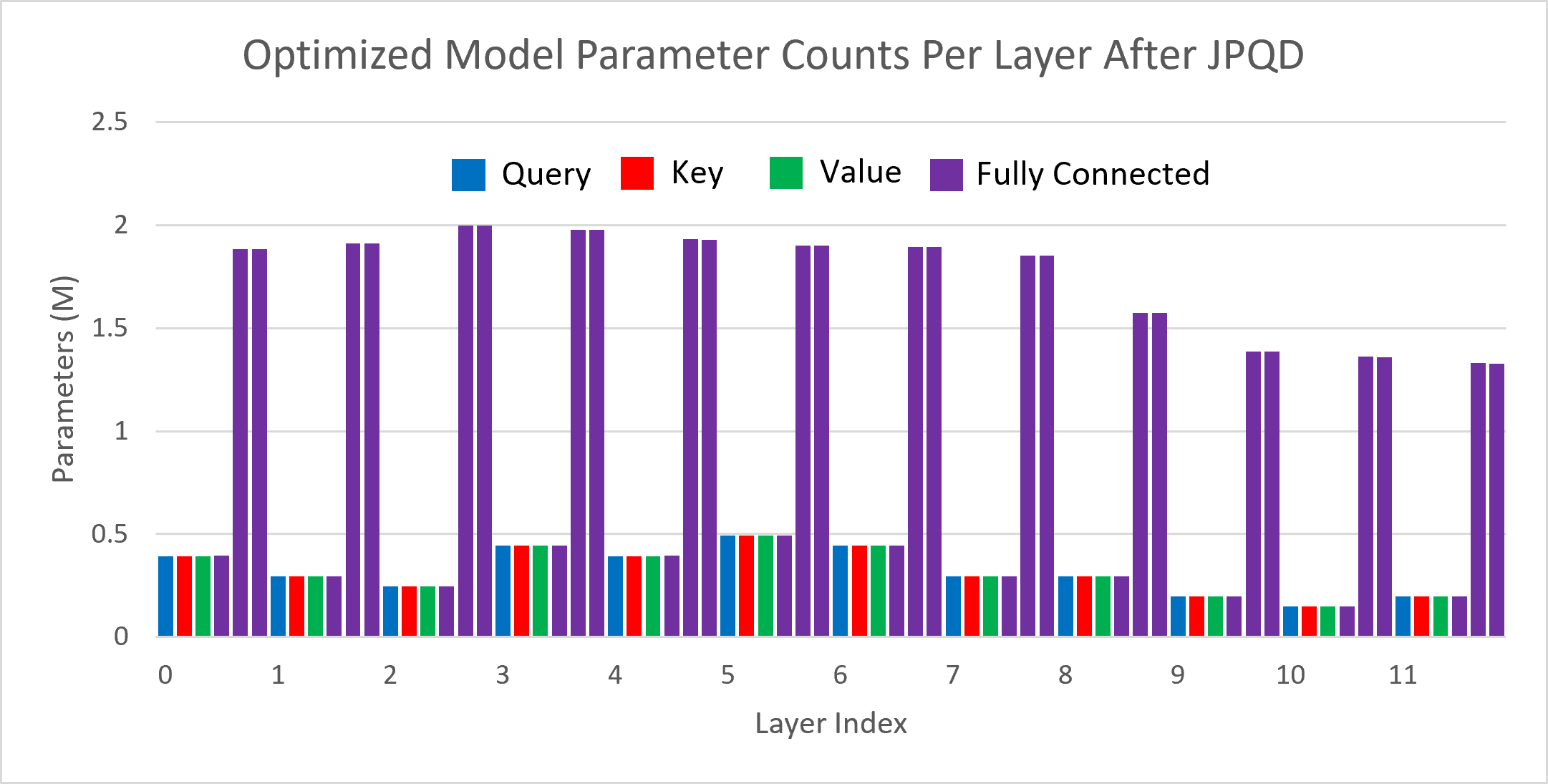
Figure 3 shows the visualization of parameter counts per layer in the BERT-base model optimized by JPQD for the text classification task. You can find that fully connected layers are actually “dense”, while most (Multi-Head Attention) MHA layers will be much sparser compared to the original model.
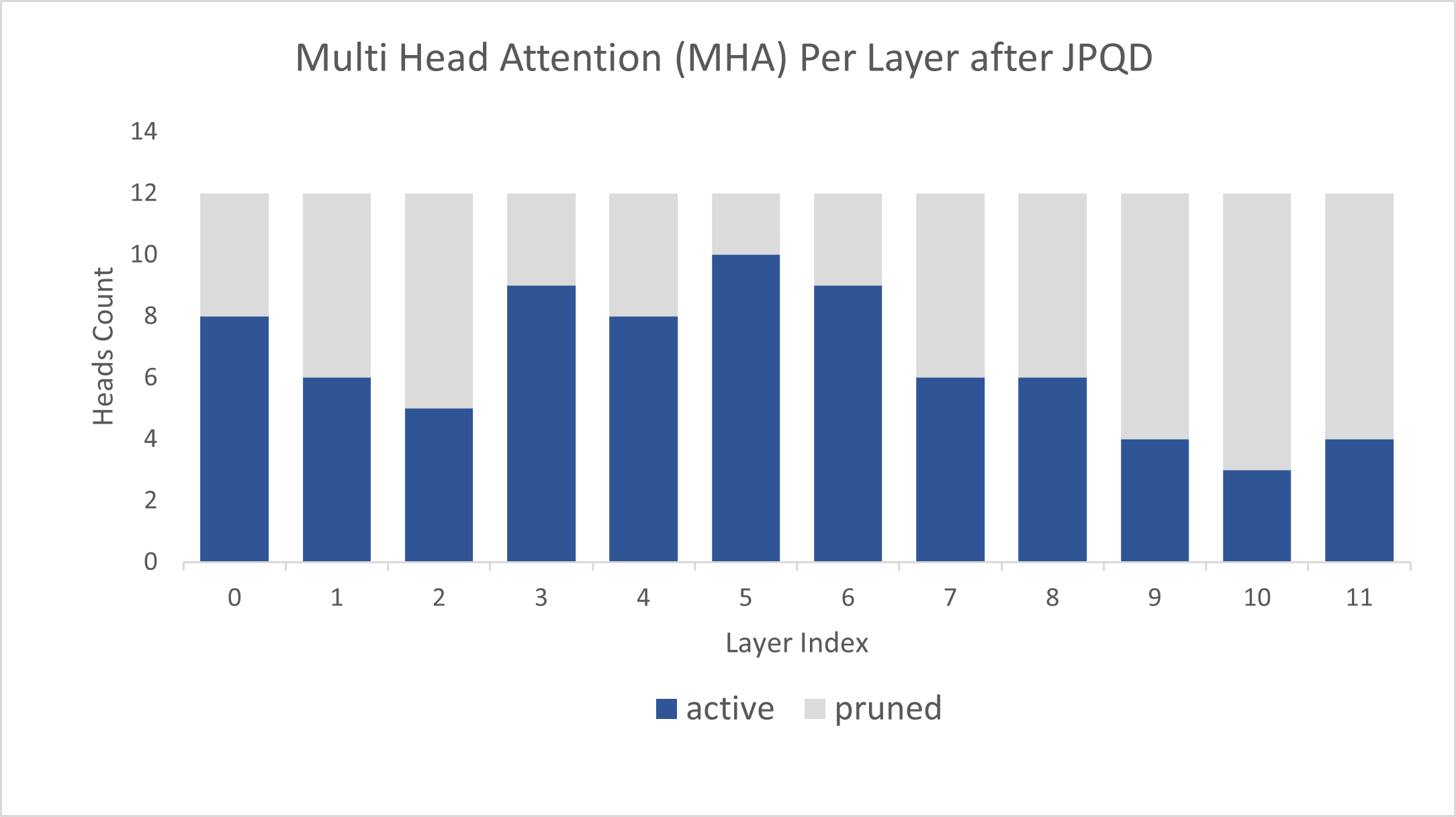
Figure 4 shows MHA head counts per layer in the BERT-base model optimized by JPQD for the text classification task, where active (blue) refer to remaining MHA head counts, while pruned (grey) refers to removed MHA head counts. Instead of pruning uniformly across all MHA heads in transformer layers, we observed that JPQD tends to preserve the weight to the lower layers while heavily pruning the highest layers, similar to experimental results from Movement Pruning (Sanh et al., 2020).
Conclusion
In this blog, we introduce a Joint Pruning, Quantization, and Distillation (JPQD) method to accelerate transformers inference on intel platforms. Here are three key takeaways:
- Optimum Intel provides simple API to integrate JPQD into training pipeline to enable pruning, quantization, and distillation in parallel during transfer learning of a pre-trained transformer. Optimized OpenVINOTM IR will be generated for efficient inference on intel architecture.
- BERT-base INT8 (JPQD) model for text classification task can reach 5.24x compression rate, leading to 4.19x performance improvement on 4th Gen Intel® Xeon® Scalable Processors while keeping minimal accuracy drop (<1%) on SST-2 compared with BERT-base FP32 models.
- BERT-base INT8 (JPQD) model for question answering task can reach 5.15x compression rate to achieve 4.25x performance improvement on 4th Gen Intel® Xeon® Scalable Processors while improving Exact Match (1.35%) and F1 score (1.15%) metric on SQuAD compared with BERT-base FP32 model.
Reference
- Hugging Face Optimum Intel
- Hugging Face Neural Networks Block Movement Pruning
- Intel®Xeon® Processors Are Still the Only CPU With MLPerf Results, Raising the Bar By5x
Additional Resources
Provide Feedback & Report Issues
Notices & Disclaimers
Intel technologies may require enabled hardware, software, or service activation.
No product or component can be absolutely secure.
Your costs and results may vary.
Intel does not control or audit third-party data. You should consult other sources to evaluate accuracy.
Intel disclaims all express and implied warranties, including without limitation, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement, as well as any warranty arising from course of performance, course of dealing, or usage in trade.
No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document.
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
Accelerate Inference of Sparse Transformer Models with OpenVINO™ and 4th Gen Intel® Xeon® Scalable Processors
Authors: Alexander Kozlov, Vui Seng Chua, Yujie Pan, Rajesh Poornachandran, Sreekanth Yalachigere, Dmitry Gorokhov, Nilesh Jain, Ravi Iyer, Yury Gorbachev
Introduction
When it comes to the inference of overparametrized Deep Neural Networks, perhaps, weight pruning is one of the most popular and promising techniques that is used to reduce model footprint, decrease the memory throughput required for inference, and finally improve performance. Since Language Models (LMs) are highly overparametrized and contain lots of MatMul operations with weights it looks natural to prune the redundant weights and benefit from sparsity at inference time. There are several types of pruning methods available:
- Fine-grained pruning (single weights).
- Coarse pruning: group-level pruning (groups of weights), vector pruning (rows in weights matrices), and filter pruning (filters in ConvNets).
Contemporary Language Models are basically represented by Transformer-based architectures. Using coarse pruning methods for such models is problematic because of the many connections between the layers. This trait means that, first, not every pruning type is applicable to such models and, second, pruning of some dimension in one layer requires adjustments in the rest of the layers connected to it.
Fine-grained sparsity does not have such a constraint and can be applied to each layer independently. However, it requires special support on the HW and inference SW level to get real performance improvements from weight sparsity. There are two main approaches that help to leverage from weight sparsity at inference:
- Skip multiplication and addition for zero weights in dot products of weights and activations. This usually results in a special instruction set that implements such logic.
- Weights compression/decompression to reduce the memory throughput. Compression is performed at the model load/compilation stage while decompression happens on the fly right before the computation when weights are in the cache. Such a method can be implemented on the HW or SW level.
In this blog post, we focus on the SW weight decompression method and showcase the end-to-end workflow from model optimization to deployment with OpenVINO.
Sparsity support in OpenVINO
Starting from OpenVINO 2022.3release, OpenVINO runtime contains a feature that enables weights compression/decompression that can lead to performance improvement on the 4thGen Intel® Xeon® Scalable Processors. However, there are some prerequisites that should be considered to enable this feature during the model deployment:
- Currently, this feature is available only to MatMul operations with weights (Fully-connected layers). So currently, there is no support for sparse Convolutional layers or other operations.
- MatMul layers should contain a high level of weights sparsity, for example, 80% or higher which is achievable, especially for large Transformer models trained on simple tasks such as Text Classification.
- The deployment scenario should be memory-bound. For example, this prerequisite is applicable to cloud deployment when there are multiple containers running inference of the same model in parallel and competing for the same RAM and CPU resources.
The first two prerequisites assume that the model is pruned using special optimization methods designed to introduce sparsity in weight matrices. It is worth noting that pruning methods require model fine-tuning on the target dataset in order to reduce accuracy degradation caused by zeroing out weights within the model. It assumes the availability of the HW capable of DL model training. Nowadays, many frameworks and libraries offer such methods. For example, PyTorch provides some capabilities for NN pruning. There are also resources that offer pre-trained sparse models that can be used as a starting point, for example, SparseZoo from Neural Magic.
OpenVINO also provides instruments for DL model pruning implemented in Neural Network Compression Framework (NNCF) that is aimed specifically for model optimization and offers different optimization options: from post-training optimization to deep compression when stacking several optimization methods. NNCF is also integrated into Hugging Face Optimum library which is designed to optimize NLP models from Hugging Face Hub.
Using only sparsity is not so beneficial compared to another popular optimization method such as bit quantization which can guarantee better performance-accuracy trade-offs after optimization in the general case. However, the good thing about sparsity is that it can be stacked with 8-bit quantization so that the performance improvements of one method reinforce the optimization effect of another one leading to a higher cumulative speedup when applying both. Considering this, OpenVINO runtime provides an acceleration feature for sparse and 8-bit quantized models. The runtime flow is shown in the scheme below:
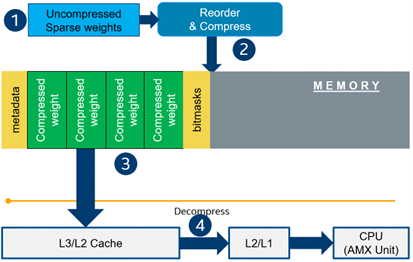
Below, we demonstrate two end-to-end workflows:
- Pruning and 8-bit quantization of the floating-point BERT model using Hugging Face Optimum and NNCF as an optimization backend.
- Quantization of sparse BERT model pruned with 3rd party optimization solution.
Both workflows end up with inference using OpenVINO API where we show how to turn on a runtime option that allows leveraging from sparse weights.
Pruning and 8-bit quantization with Hugging Face Optimum and NNCF
This flow assumes that there is a Transformer model coming from the Hugging Face Transformers library that is fine-tuned for a downstream task. In this example, we will consider the text classification problem, in particular the SST2 dataset from the GLUE benchmark, and the BERT-base model fine-tuned for it. To do the optimization, we used an Optimum-Intel library which contains the optimization capabilities based on the NNCF framework and is designed for inference with OpenVINO. You can find the exact characteristics and steps to reproduce the result in this model card on the Hugging Face Hub. The model is 80% sparse and 8-bit quantized.
To run a pre-optimized model you can use the following code from this notebook:
Quantization of already pruned model
In case if you deal with already pruned model, you can use Post-Training Quantization from the Optimum-Intel library to make it 8-bit quantized as well. The code snippet below shows how to quantize the sparse BERT model optimized for MNLI dataset using Neural Magic SW solution. This model is publicly available so that we download it using Optimum API and quantize on fly using calibration data from MNLI dataset. The code snippet below shows how to do that.
Enabling sparsity optimization inOpenVINO Runtime and 4th Gen Intel® Xeon® Scalable Processors
Once you get ready with the sparse quantized model you can use the latest advances of the OpenVINO runtime to speed up such models. The model compression feature is enabled in the runtime at the model compilation step using a special option called: “CPU_SPARSE_WEIGHTS_DECOMPRESSION_RATE”. Its value controls the minimum sparsity rate that MatMul operation should have to be optimized at inference time. This property is passed to the compile_model API as it is shown below:
An important note is that a high sparsity rate is required to see the performance benefit from this feature. And we note again that this feature is available only on the 4th Gen Intel® Xeon® Scalable Processors and it is basically for throughput-oriented scenarios. To simulate such a scenario, you can use the benchmark_app application supplied with OpenVINO distribution and limit the number of resources available for inference. Below we show the performance difference between the two runs sparsity optimization in the runtime:
- Benchmarking without sparsity optimization:
- Benchmarking when sparsity optimization is enabled:
Performance Results
We performed a benchmarking of our sparse and 8-bit quantized BERT model on 4th Gen Intel® Xeon® Scalable Processors with various settings. We ran two series of experiments where we vary the number of parallel threads and streams available for the asynchronous inference in the first experiments and we investigate how the sequence length impact the relative speedup in the second series of experiments.
The table below shows relative speedup for various combinations of number of streams and threads and at the fixed sequence length after enabling sparsity acceleration in the OpenVINO runtime.
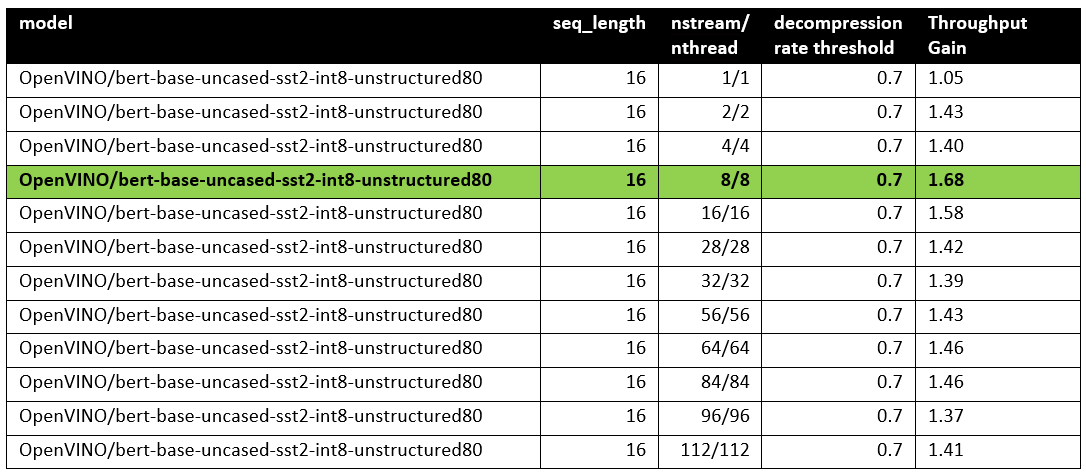
Based on this, we can conclude that one can expect significant performance improvement with any number of streams/threads larger than one. The optimal performance is achieved at eight streams/threads. However, we would like to note that this is model specific and depends on the model architecture and sparsity distribution.
The chart below also shows the relationship between the possible acceleration and the sequence length.
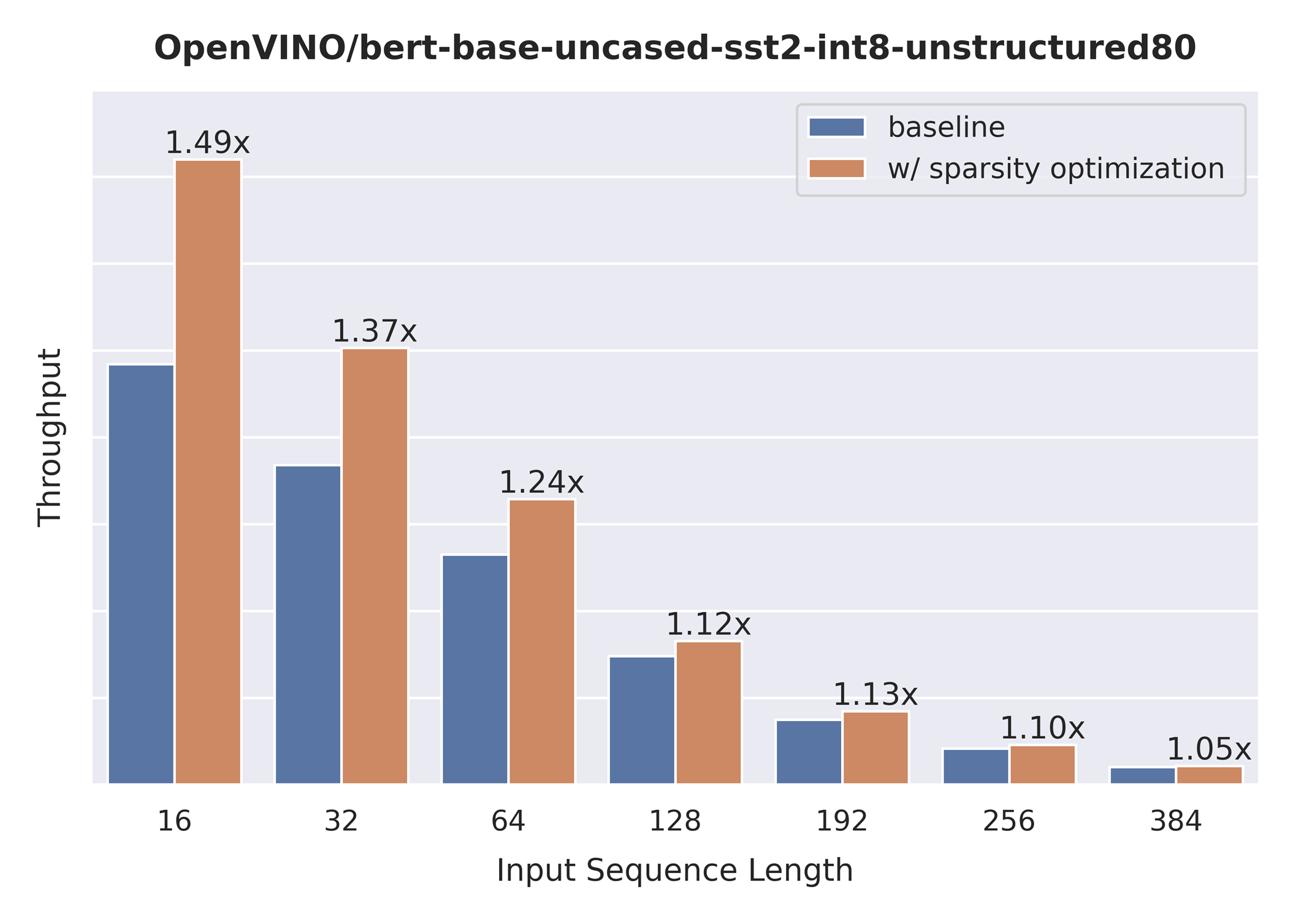
As you can see the benefit from sparsity is decreasing with the growth of the sequence length processed by the model. This effect can be explained by the fact that for larger sequence lengths the size of the weights is no longer a performance bottleneck and weight compression does not have so much impact on the inference time. It means that such a weight sparsity acceleration feature does not suit well for large text processing tasks but could be very helpful for Question Answering, Sequence Classification, and similar tasks.
References
Accelerate Inference of Hugging Face Transformer Models with Optimum Intel and OpenVINO™
Authors: Xiake Sun, Kunda Xu
1. Introduction

Hugging Face is a large open-source community that quickly became an enticing hub for pre-trained deep learning models across Natural Language Processing (NLP), Automatic Speech Recognition(ASR), and Computer Vision (CV) domains.
Optimum Intel provides a simple interface to optimize Transformer models and convert them to OpenVINO™ Intermediate Representation (IR) format to accelerate end-to-end pipelines on Intel® architectures using OpenVINO™ runtime.
Sentimental classification, as one of the popular NLP tasks, is the automated process of identifying opinions in the text and labeling them as positive or negative. In this blog, we use DistilBERT for the sentimental classification task as an example to show how Optimum Intel helps to optimize the model with Neural Network Compression Framework (NNCF) and accelerate inference with OpenVINO™ runtime.
2. Setup Environment
Install optimum-intel and its dependency in a new python virtual environment as follow:
3. Model Inference with OpenVINO™ Runtime
The Optimum inference models are API compatible with Hugging Face Transformers models; which means you could simply replace Hugging Face Transformer “AutoModelXXX” class with the “OVModelXXX” class to switch model inference with OpenVINO™ runtime. You could set “from_transformers=True” when loading the model with the from_pretrained() method, the loaded model will be automatically converted to an OpenVINO™ IR for inference with OpenVINO™ runtime.
Here is an example of how to perform inference with OpenVINO™ runtime for a sentimental classification task, the output of the pipeline consists of classification label (positive/negative) and corresponding confidence.
4. Model Quantization with NNCF framework
Most deep learning models are built using 32 bits floating-point precision (FP32). Quantization is the process to represent the model using less memory with minimal accuracy loss. To further optimize model performance on Intel® architecture via Intel® Deep Learning Boost, model quantization as 8 bits integer precision (INT8) is required.
Optimum Intel enables you to apply quantization on Hugging Face Transformer Models using the NNCF. NNCF provides two mainstream quantization methods - Post-Training Quantization (PTQ) and Quantization-Aware Training (QAT).
- Post-Training Quantization (PTQ) refers to quantizing a model with a representative calibration dataset without fine-tuning.
- Quantization-Aware Training (QAT) is applied to simulate the effects of quantization during training to mitigate its effect on the model’s accuracy
4.1. Model Quantization with NNCF PTQ
NNCF Post-training static quantization introduces an additional calibration step where data is fed through the network to compute the activations quantization parameters. Here is how to apply static quantization on a pre-trained DistilBERT using General Language Understanding Evaluation (GLUE) dataset as the calibration dataset:
The quantize() method applies post-training static quantization and export the resulting quantized model to the OpenVINO™ Intermediate Representation (IR), which can be deployed on any target Intel® architecture.
4.2. Model Quantization with NNCF QAT
Quantization-Aware Training (QAT) aims to mitigate model accuracy issue by simulating the effects of quantization during training. If post-training quantization results in accuracy degradation, QAT can be used instead.
NNCF provides an “OVTrainer” class to replace Hugging Face Transformer’s “Trainer” class to enable quantization during training with additional quantization configuration. Here is an example on how to fine-tune a DistilBERT with Stanford Sentiment Treebank (SST) dataset while applying quantization aware training (QAT):
4.3. Comparison of FP32 and INT8 model outputs
“OVModelForXXX” class provided the same API to load FP32 and quantized INT8 OpenVINO™ models by setting “from_transformers=False”. Here is an example of how to load quantized INT8 models optimized by NNCF and inference with OpenVINO™ runtime.
Here is an example for sentimental classification output of FP32 and INT8 models:

5. Mitigation of accuracy issue cause by saturation
8-bit instructions of old CPU generations (based on SSE,AVX-2, AVX-512 instruction sets) are prone to so-called saturation(overflow) of the intermediate buffer when calculating the dot product, which is an essential part of Convolutional or MatMul operations. This saturation can lead to a drop in accuracy when running inference of 8-bit quantized models on the mentioned architectures. The problem does not occur on GPUs or CPUs with Intel® Deep Learning Boost (VNNI) technology and further generations.
In the case a significant difference in accuracy (>1%) occurs after quantization with NNCF default quantization configuration, here is an example code to check if deployed platform supports Intel® Deep Learning Boost (VNNI) and further generations:
While quantizing activations use the full range of 8-bit data types, there is a workaround using only 7 bits to represent weights (of Convolutional or Fully-Connected layers) to mitigate saturation issue for many models on old CPU platform.
NNCF provides three options to deal with the saturation issue. The options can be enabled in the NNCF quantization configuration using the “overflow_fix” parameter:
- "disable": (default) option do not apply saturation fix at all
- "enable": option to apply for all layers in the model
- "first_layer_only": option to fix saturation issue for the first layer
Here is an example to enable overflow fix in quantization configuration to mitigate accuracy issue on old CPU platform:
After model quantization with updated quantization configuration with NNCF PTQ/NNCF, you can repeat step 4.3 to verify if quantized INT8 model inference results are consistent with FP32 model outputs.
Additional Resources
Provide Feedback & Report Issues
Notices & Disclaimers
Intel technologies may require enabled hardware, software, or service activation.
No product or component can be absolutely secure.
Your costs and results may vary.
Intel does not control or audit third-party data. You should consult other sources to evaluate accuracy.
Intel disclaims all express and implied warranties, including without limitation, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement, as well as any warranty arising from course of performance, course of dealing, or usage in trade.
No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document.
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.