
.png)
Alexander
Kozlov
Accelerate Inference of Sparse Transformer Models with OpenVINO™ and 4th Gen Intel® Xeon® Scalable Processors
Authors: Alexander Kozlov, Vui Seng Chua, Yujie Pan, Rajesh Poornachandran, Sreekanth Yalachigere, Dmitry Gorokhov, Nilesh Jain, Ravi Iyer, Yury Gorbachev
Introduction
When it comes to the inference of overparametrized Deep Neural Networks, perhaps, weight pruning is one of the most popular and promising techniques that is used to reduce model footprint, decrease the memory throughput required for inference, and finally improve performance. Since Language Models (LMs) are highly overparametrized and contain lots of MatMul operations with weights it looks natural to prune the redundant weights and benefit from sparsity at inference time. There are several types of pruning methods available:
- Fine-grained pruning (single weights).
- Coarse pruning: group-level pruning (groups of weights), vector pruning (rows in weights matrices), and filter pruning (filters in ConvNets).
Contemporary Language Models are basically represented by Transformer-based architectures. Using coarse pruning methods for such models is problematic because of the many connections between the layers. This trait means that, first, not every pruning type is applicable to such models and, second, pruning of some dimension in one layer requires adjustments in the rest of the layers connected to it.
Fine-grained sparsity does not have such a constraint and can be applied to each layer independently. However, it requires special support on the HW and inference SW level to get real performance improvements from weight sparsity. There are two main approaches that help to leverage from weight sparsity at inference:
- Skip multiplication and addition for zero weights in dot products of weights and activations. This usually results in a special instruction set that implements such logic.
- Weights compression/decompression to reduce the memory throughput. Compression is performed at the model load/compilation stage while decompression happens on the fly right before the computation when weights are in the cache. Such a method can be implemented on the HW or SW level.
In this blog post, we focus on the SW weight decompression method and showcase the end-to-end workflow from model optimization to deployment with OpenVINO.
Sparsity support in OpenVINO
Starting from OpenVINO 2022.3release, OpenVINO runtime contains a feature that enables weights compression/decompression that can lead to performance improvement on the 4thGen Intel® Xeon® Scalable Processors. However, there are some prerequisites that should be considered to enable this feature during the model deployment:
- Currently, this feature is available only to MatMul operations with weights (Fully-connected layers). So currently, there is no support for sparse Convolutional layers or other operations.
- MatMul layers should contain a high level of weights sparsity, for example, 80% or higher which is achievable, especially for large Transformer models trained on simple tasks such as Text Classification.
- The deployment scenario should be memory-bound. For example, this prerequisite is applicable to cloud deployment when there are multiple containers running inference of the same model in parallel and competing for the same RAM and CPU resources.
The first two prerequisites assume that the model is pruned using special optimization methods designed to introduce sparsity in weight matrices. It is worth noting that pruning methods require model fine-tuning on the target dataset in order to reduce accuracy degradation caused by zeroing out weights within the model. It assumes the availability of the HW capable of DL model training. Nowadays, many frameworks and libraries offer such methods. For example, PyTorch provides some capabilities for NN pruning. There are also resources that offer pre-trained sparse models that can be used as a starting point, for example, SparseZoo from Neural Magic.
OpenVINO also provides instruments for DL model pruning implemented in Neural Network Compression Framework (NNCF) that is aimed specifically for model optimization and offers different optimization options: from post-training optimization to deep compression when stacking several optimization methods. NNCF is also integrated into Hugging Face Optimum library which is designed to optimize NLP models from Hugging Face Hub.
Using only sparsity is not so beneficial compared to another popular optimization method such as bit quantization which can guarantee better performance-accuracy trade-offs after optimization in the general case. However, the good thing about sparsity is that it can be stacked with 8-bit quantization so that the performance improvements of one method reinforce the optimization effect of another one leading to a higher cumulative speedup when applying both. Considering this, OpenVINO runtime provides an acceleration feature for sparse and 8-bit quantized models. The runtime flow is shown in the scheme below:
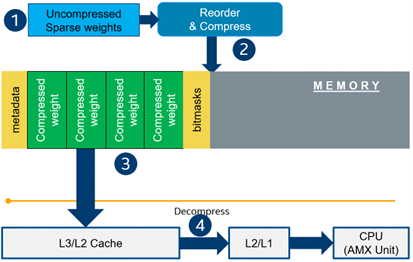
Below, we demonstrate two end-to-end workflows:
- Pruning and 8-bit quantization of the floating-point BERT model using Hugging Face Optimum and NNCF as an optimization backend.
- Quantization of sparse BERT model pruned with 3rd party optimization solution.
Both workflows end up with inference using OpenVINO API where we show how to turn on a runtime option that allows leveraging from sparse weights.
Pruning and 8-bit quantization with Hugging Face Optimum and NNCF
This flow assumes that there is a Transformer model coming from the Hugging Face Transformers library that is fine-tuned for a downstream task. In this example, we will consider the text classification problem, in particular the SST2 dataset from the GLUE benchmark, and the BERT-base model fine-tuned for it. To do the optimization, we used an Optimum-Intel library which contains the optimization capabilities based on the NNCF framework and is designed for inference with OpenVINO. You can find the exact characteristics and steps to reproduce the result in this model card on the Hugging Face Hub. The model is 80% sparse and 8-bit quantized.
To run a pre-optimized model you can use the following code from this notebook:
Quantization of already pruned model
In case if you deal with already pruned model, you can use Post-Training Quantization from the Optimum-Intel library to make it 8-bit quantized as well. The code snippet below shows how to quantize the sparse BERT model optimized for MNLI dataset using Neural Magic SW solution. This model is publicly available so that we download it using Optimum API and quantize on fly using calibration data from MNLI dataset. The code snippet below shows how to do that.
Enabling sparsity optimization inOpenVINO Runtime and 4th Gen Intel® Xeon® Scalable Processors
Once you get ready with the sparse quantized model you can use the latest advances of the OpenVINO runtime to speed up such models. The model compression feature is enabled in the runtime at the model compilation step using a special option called: “CPU_SPARSE_WEIGHTS_DECOMPRESSION_RATE”. Its value controls the minimum sparsity rate that MatMul operation should have to be optimized at inference time. This property is passed to the compile_model API as it is shown below:
An important note is that a high sparsity rate is required to see the performance benefit from this feature. And we note again that this feature is available only on the 4th Gen Intel® Xeon® Scalable Processors and it is basically for throughput-oriented scenarios. To simulate such a scenario, you can use the benchmark_app application supplied with OpenVINO distribution and limit the number of resources available for inference. Below we show the performance difference between the two runs sparsity optimization in the runtime:
- Benchmarking without sparsity optimization:
- Benchmarking when sparsity optimization is enabled:
Performance Results
We performed a benchmarking of our sparse and 8-bit quantized BERT model on 4th Gen Intel® Xeon® Scalable Processors with various settings. We ran two series of experiments where we vary the number of parallel threads and streams available for the asynchronous inference in the first experiments and we investigate how the sequence length impact the relative speedup in the second series of experiments.
The table below shows relative speedup for various combinations of number of streams and threads and at the fixed sequence length after enabling sparsity acceleration in the OpenVINO runtime.
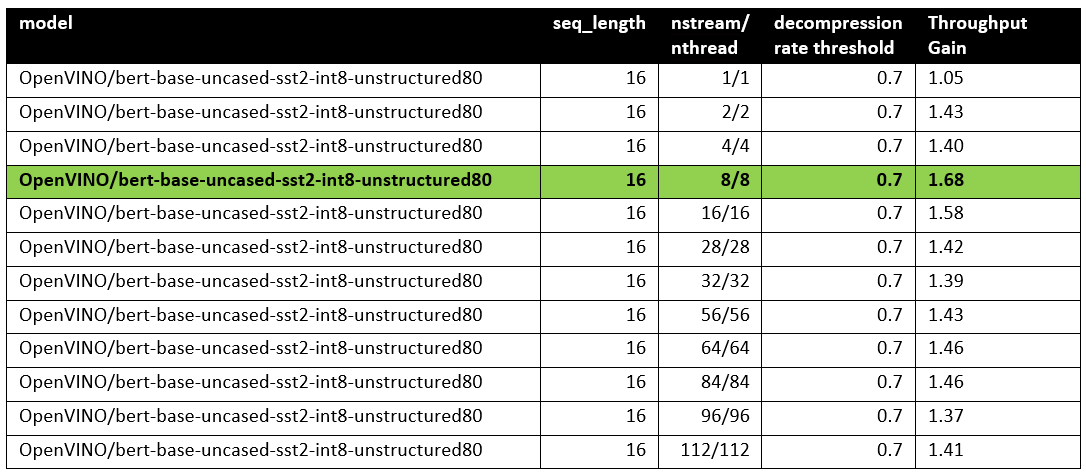
Based on this, we can conclude that one can expect significant performance improvement with any number of streams/threads larger than one. The optimal performance is achieved at eight streams/threads. However, we would like to note that this is model specific and depends on the model architecture and sparsity distribution.
The chart below also shows the relationship between the possible acceleration and the sequence length.
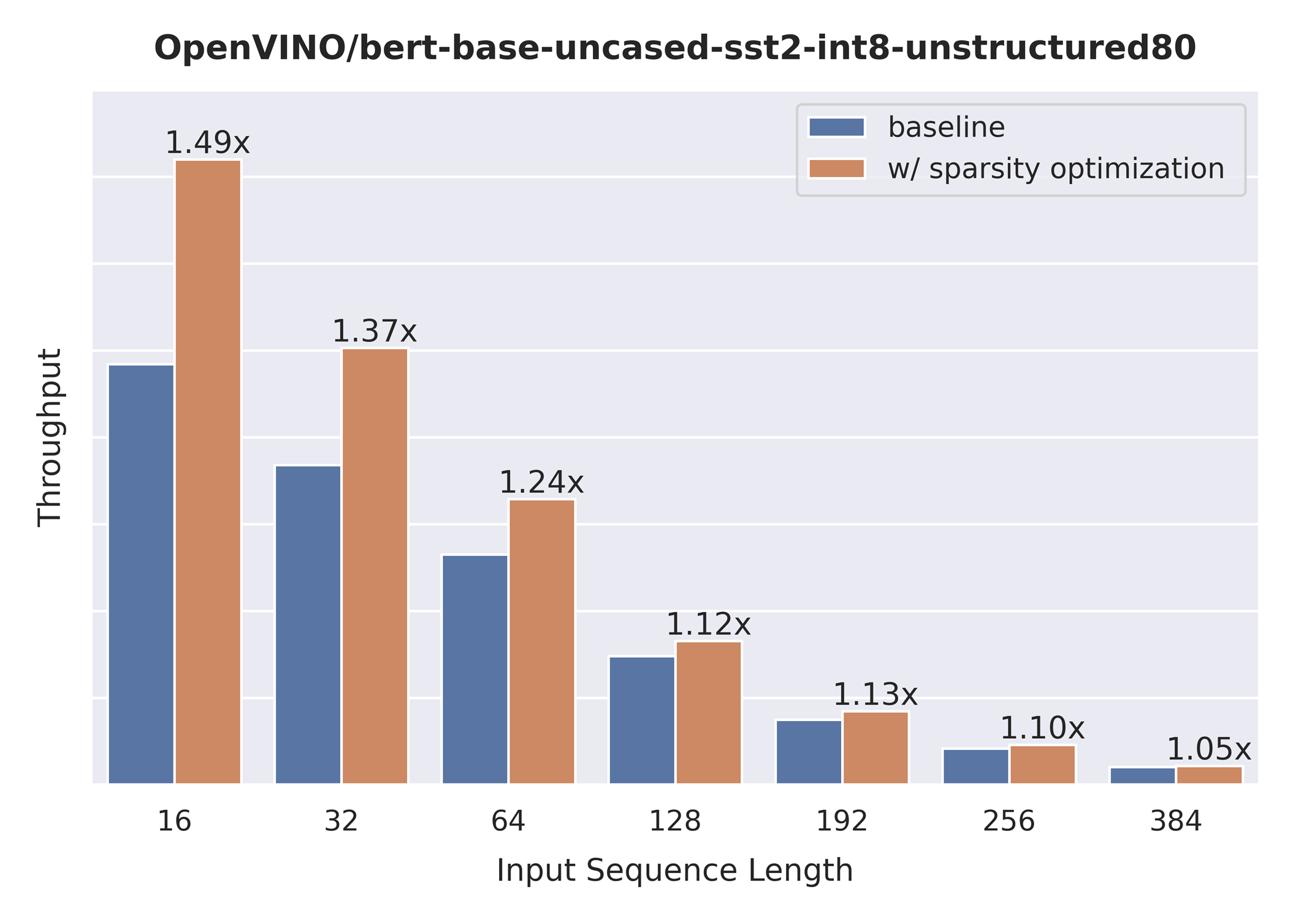
As you can see the benefit from sparsity is decreasing with the growth of the sequence length processed by the model. This effect can be explained by the fact that for larger sequence lengths the size of the weights is no longer a performance bottleneck and weight compression does not have so much impact on the inference time. It means that such a weight sparsity acceleration feature does not suit well for large text processing tasks but could be very helpful for Question Answering, Sequence Classification, and similar tasks.































