.png)
Nooshin
Nabizadeh
Creating AI Pipeline for Cell Image Analysis: Insights, Challenges, and CHO Use Case (Part 1 of 2, Intel Edge AI in the Realm of Biopharma and Drug Development)
In the ever-evolving landscape of biopharmaceutical technology and drug development, a recent effort in the field of Cell Analytics for Monoclonal Antibody Production has shed light on the crucial role of Edge AI Technology in navigating complex challenges of scaling and producing solutions.
In this 2-part blog series, we will explore the use of Intel Edge AI Technology in biopharma and drug development, addressing challenges and providing insights into the development of AI pipelines for cell segmentation and analysis.
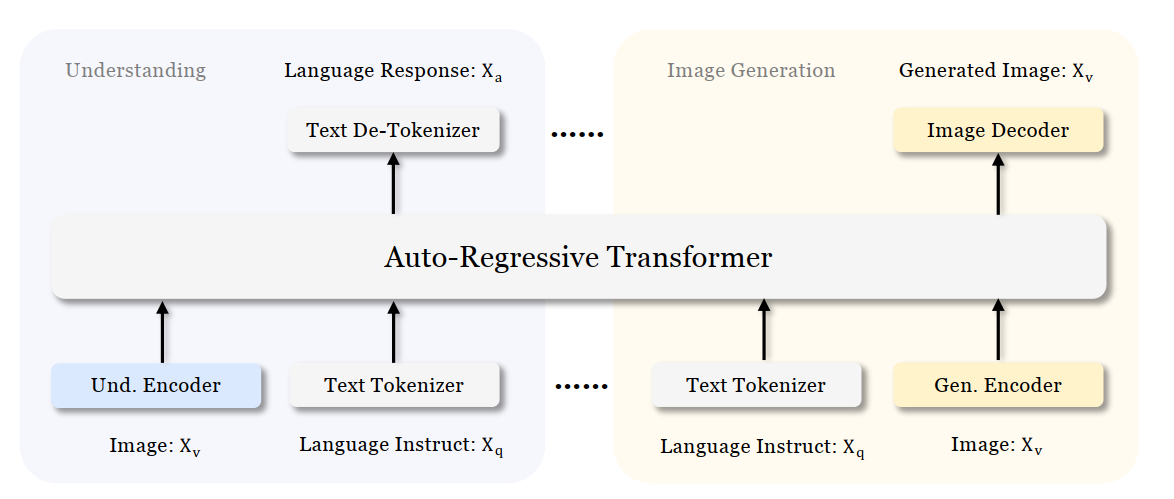
Intel has been involved in this process with a variety of partners. One of Intel’s contributions to the cell image project centers around processing brightfield1 images using an AI pipeline containing multiple deep learning models. The pipeline's purpose is to identify cells and other biological components and provide feedback on dynamic biological characteristics such as cell morphology, viability, and phenotypic changes, among others. Throughout this process, working on cell-AI projects usually brings a unique set of challenges to the forefront.
First, it is an interdisciplinary field and the knowledge gap between data scientists and biopharma experts requires more back-and-forth clear communications for planning and validity checks. Frequently when attempting to implement AI solutions in the laboratory, data scientists and bench scientists struggle to fully grasp the nature and needs of each other’s role. This lack of mutual understanding can also hinder the usability and scalability of an AI solution needing to be integrated into diverse lab environments.
The second challenge is instrument variability. Different plate reader2 microscopes have different hardware, optics, and apertures which cause their produced images not to be consistent. This adds an extra layer of work to assess and address these inconsistencies along the way (like regular tracked calibration and adjustment). Additionally, equipment vendor-to-vendor differences, culture temperature, medium conditions, and genetic modifications can all affect the variability of data and the inherent transferability of the deep learning pipeline. This would drive the need to monitor the performance of DL models at the edge and cloud ML ops components.
The third challenge is obtaining peer-review labels because the process is based on supervised Machine Learning and obtaining clean accurate labels is very costly and time-consuming.
And the last challenge is about the model deployment. In most cases, cloud deployment is not an option due to data size and data privacy. Produced images from plate reader microscopes are huge and transferring data to the cloud and sending the results back would create high latency because a huge amount of data must be streamed (30Gb per hour). And more importantly, laboratories are usually not willing to share the data. Due to these two constraints, cloud deployments are not usually an option, and the pipeline must be deployed at the edge.
Now, let’s talk about a specific application of this technology: the CHO Cell Segmentation Use Case.
CHO Cell Segmentation Use Case
CHO cells, or Chinese Hamster Ovary cells, are a cornerstone in the production of complex protein molecules such as monoclonal antibodies, fusion proteins, hormones, and coagulation factors. Unlike stem cells or CAR-T cells, where the cells themselves are the therapeutic product, in CHO cells, it is the proteins they produce that are of paramount importance. Monitoring the health, viability, and production capability of these cells is a critical step in commercial protein production.
Traditionally, assessing the condition of CHO cells involves a multi-step process that is not only time-consuming but also requires the use of expensive reagents and chemicals. Depending on the process, the workflow can be something like below.
- Culture cells
- Fix cells – wash in expensive reagents to remove the culture medium.
- Permeabilization – wash in more expensive chemicals to permeabilize the cell membrane (to stain for intercellular proteins).
- Blocking – incubate cells in another expensive reagent to prevent binding of no specific antibodies.
- Primary Antibody Incubation – antibody specifically to bind to a protein that is being produced.
- Washing – removing unbound Primary Antibodies using more expensive chemicals.
- Nuclear staining – use nuclear stain like DAPI to visualize cell nuclei then wash with the same chemicals from the washing step
- Mounting – get ready to read in the microscope (plate reader1)
- Imaging – Stained cells …. count them up and determine the state in the protein production cycle and relative cell health (eventually they peter out and stop producing and the batch needs to be flushed. (Cell count, viability number, etc. are the output not the image)
From culturing to imaging, each step plays a vital role in ensuring the quality of the protein product. However, with the advent of AI and deep learning, there is an opportunity to streamline this workflow significantly. Using an AI pipeline including multiple Deep Learning models and data pre and post-processing, we can go from Step 1 directly to Step 9, removing the majority of the labor and latency in getting actionable results out of a staining workflow and bypassing expensive specialty chemicals requirement. Intel has put together a reference implementation for deploying said pipeline and inferencing of these images on the edge as part of the Cell Image project https://www.cellimage.ie/. OpenVINO Toolkit, OpenVINO Model Server, and AI Connect for Scientific Data are used in this design. Let’s briefly talk about each of these wonderful SW packages in part 2 of this article series. Stay tuned!
Conclusion
In conclusion, the integration of Intel Edge AI Technology into the biopharmaceutical sector represents a transformative step towards more efficient and scalable drug development processes. As we have seen in this first installment of our blog series, the deployment of AI pipelines for cell segmentation and analysis in monoclonal antibody production is not without its challenges. These include bridging the interdisciplinary knowledge gap, managing instrument variability, acquiring peer-reviewed labels, and overcoming the hurdles associated with model deployment.
Despite these challenges, the potential benefits of Edge AI in biopharma are substantial. By leveraging Intel's advanced AI technologies, we can significantly reduce the time and cost associated with traditional cell analysis methods, while also enhancing the accuracy and reliability of the results. The use of edge computing addresses the concerns of data size and privacy, allowing for real-time processing and analysis without the need for cloud transfer.
As we move forward in this blog series, we will delve deeper into the specifics of Intel's Edge AI solutions, including the OpenVINO toolkit, OpenVINO Model Server, and AI Connect for Scientific Data. We will explore how these tools are being applied in real-world scenarios to drive innovation and improve outcomes in the realm of biopharma and drug development in the next part of this series.
Reach out to Intel's Health and Life Sciences team at health.lifesciences@intel.com or learn more about what we do at https://www.intel.com/health.

We'd like to hear from you! Let us know in the comments or discuss – which AI use cases in health and life sciences do you think will have the greatest impact on global health?
If you enjoyed hearing from the Health and Life Sciences team and want to hear more, give this post a like and ensure you subscribe to get the latest updates from the team.
About the Author
Nooshin Nabizadeh has Ph.D. in Electrical and Computer Engineering from the University of Miami and works at Intel Corporation as AI Solutions Architect. She enjoys photography, writing poetry, reading about psychology and philosophy, and optimizing solutions to run as fast as possible on a given piece of hardware. Connect with her on LinkedIn https://www.linkedin.com/in/nooshin-nabizadeh/ by mentioning this blog.
- Brightfield microscopy is a widely used technique for observing the morphology of cells and tissues.
- A plate reader is a laboratory instrument used to obtain images from samples in microtiter plates. The reader shines a specific calibrated frequency of light (UV, visible, fluorescence, etc.) through the samples in the wells of the plate. Plate reader microscopy data sets have inherent variability which drives the requirement of regular tracked calibration and adjustment.