
.png)
Xiake
Sun
DeepSeek Janus-Pro Model Enabling with OpenVINO
1. Introduction
Janus is a unified multimodal understanding and generation model developed by DeepSeek. Janus proposed decoupling visual encoding to alleviate the conflict between multimodal understanding and generation tasks. Janus-Pro further scales up the Janus model to larger model size (deepseek-ai/Janus-Pro-1B & deepseek-ai/Janus-Pro-7B) with optimized training strategy and training data, achieving significant advancements in both multimodal understanding and text-to-image tasks.
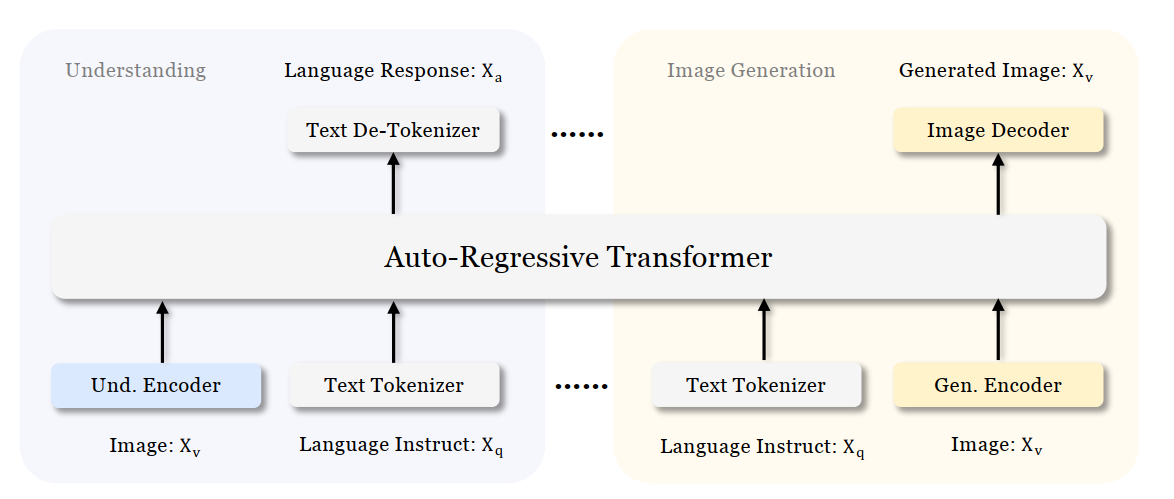
Figure 1 shows the architecture of Janus-Pro, which decouples visual encoding for multimodal understanding and visual generation. “Und. Encoder” and “Gen. Encoder” are abbreviations for “Understanding Encoder” and “Generation Encoder”. For the multimodal understanding task, SigLIP vision encoder used to extract high-dimensional semantic features from the image, while for the vision generation task, VQ tokenizer used to map images to discrete IDs. Both the understanding adaptor and the generation adaptor are two-layer MLPs to map the embeddings to the input space of LLM.
In this blog, we will introduce how to deploy Janus-Pro model with OpenVINOTM runtime on the intel platform.
2. Janus-Pro Pytorch Model to OpenVINOTM Model Conversion
2.1. Setup Python Environment
2.2 Download Janus Pytorch model (Optional)
2.3. Convert Pytorch Model to OpenVINOTM INT4 Model
The converted OpenVINO will be saved in Janus-Pro-1B-OV directory for deployment.
3. Janus-Pro Inference with OpenVINOTM Demo
In this section, we provide several examples to show Janus-Pro for multimodal understanding and vision generation tasks.
3.1. Multimodal Understanding Task – Image Caption with OpenVINOTM
Prompt: Describe image in details
Input image:

Generated Output:
3.2. Multimodal Understanding Task – Equation Description with OpenVINOTM
Prompt: Generate the latex code of this formula
Input Image:
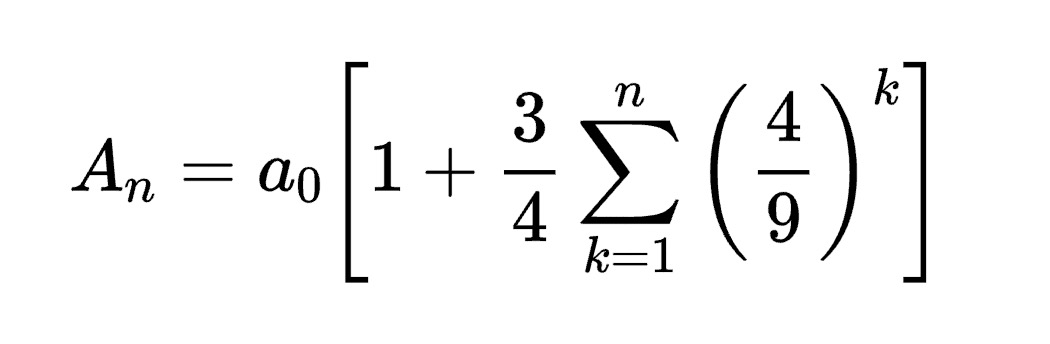
Generated Output:
3.3. Multimodal Understanding Task – Code Generation with OpenVINOTM
Prompt: Generate the matplotlib pyplot code for this plot
Input Image:
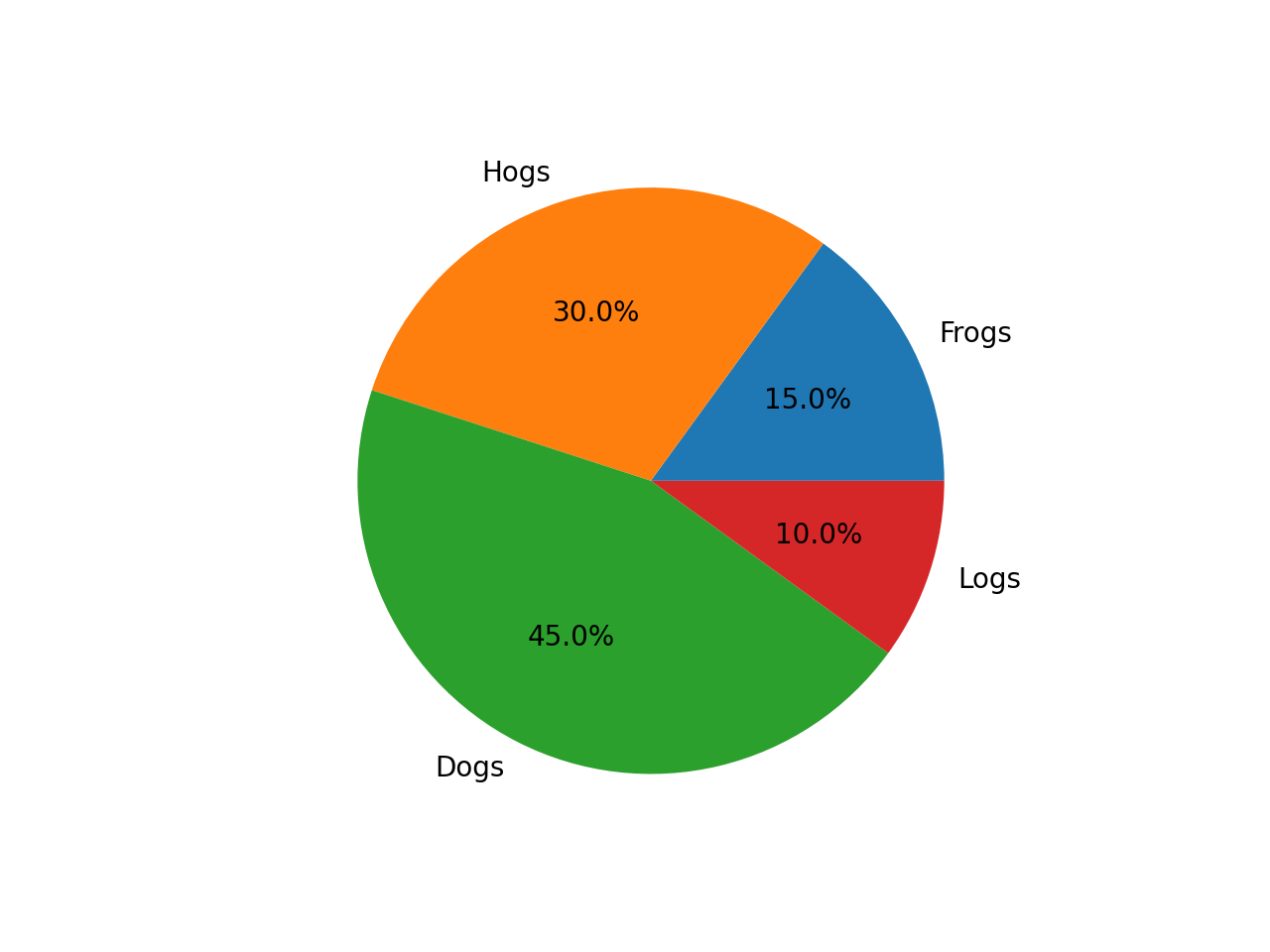
Generated Output:
3.4. Vision Generation Task with OpenVINOTM
Input Prompt: A cute and adorable baby fox with big brown eyes, autumn leaves in the background enchanting, immortal, fluffy, shiny mane, Petals, fairyism, unreal engine 5 and Octane Render, highly detailed, photorealistic, cinematic, natural colors.
Generated image:


4. Performance Evaluation & Memory Usage Analysis
We also provide benchmark scripts to evaluate Janus-Pro model performance and memory usage with OpenVINOTM inference, you may specify model name and device for your target platform.
4.1. Benchmark Janus-Pro for Multimodal Understanding Task with OpenVINOTM
Here are some arguments for benchmark script for Multimodal Understanding Task:
--model_id: specify the Janus OpenVINOTM model directory
--prompt: specify input prompt for multimodal understanding task
--image_path: specify input image for multimodal understanding task
--niter: specify number of test iteration, default is 5
--device: specify which device to run inference
--max_new_tokens: specify max number of generated tokens
By default, the benchmark script will run 5 round multimodal understanding tasks on target device, then report pipeline initialization time, average first token latency (including preprocessing), 2nd+ token throughput and max RSS memory usage.
4.2. Benchmark Janus-Pro for Text-to-Image Task with OpenVINOTM
Here are some arguments for benchmark scripts for Text-to-Image Task
--model_id: specify the Janus OpenVINO TM model directory
--prompt: specify input prompt for text-to-image generation task
--niter: specify number of test iteration
--device: specify which device to run inference
By default, the benchmark script will run 5 round image generation tasks on target device, then report the pipeline initialization time, average image generation latency and max RSS memory usage.
5. Conclusion
In this blog, we introduced how to enable Janus-Pro model with OpenVINOTM runtime, then we demonstrated the Janus-Pro capability for various multimodal understanding and image generation tasks. In the end, we provide python script for performance & memory usage evaluation for both multimodal understanding and image generation task on target platform.































