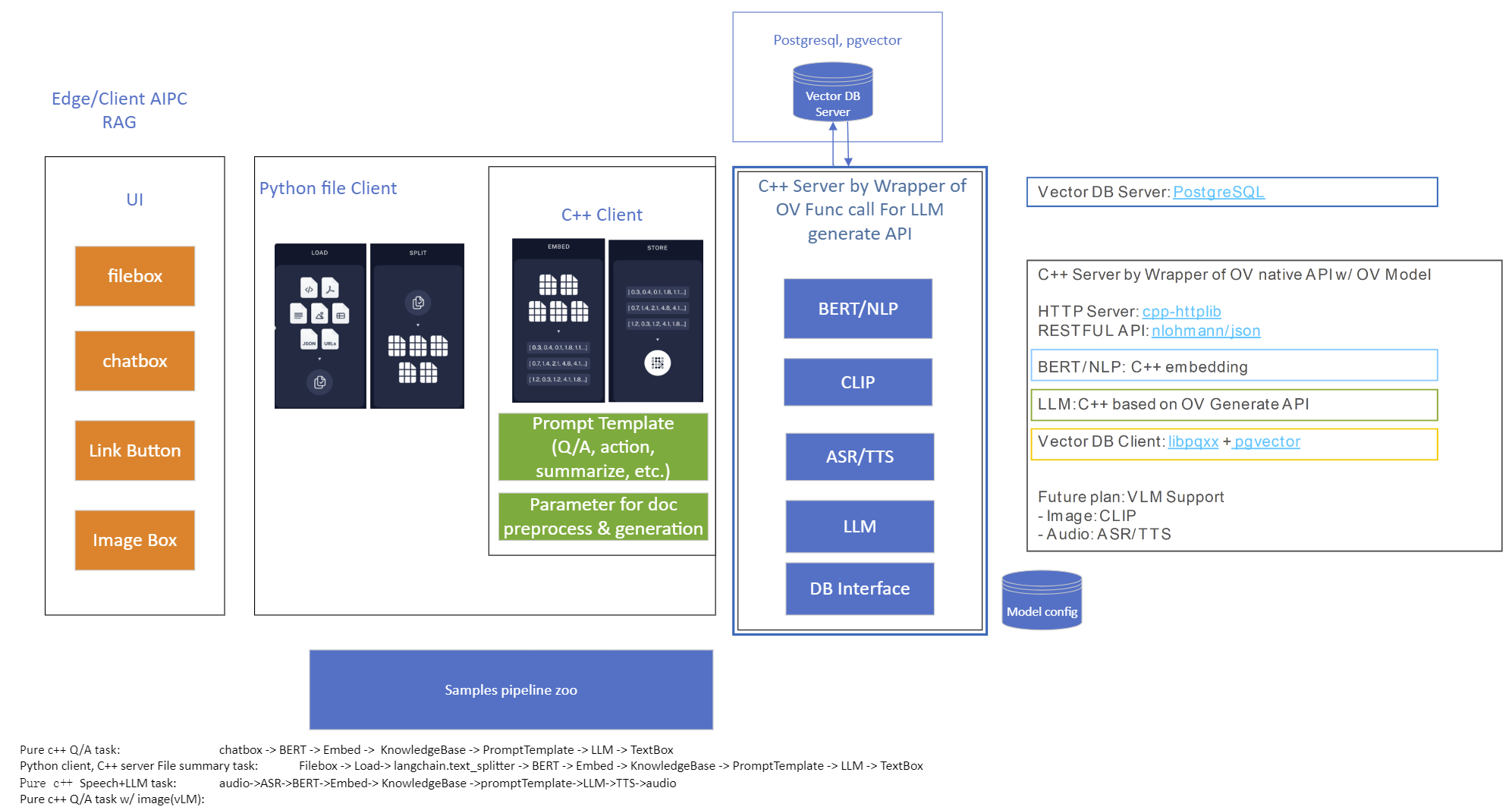
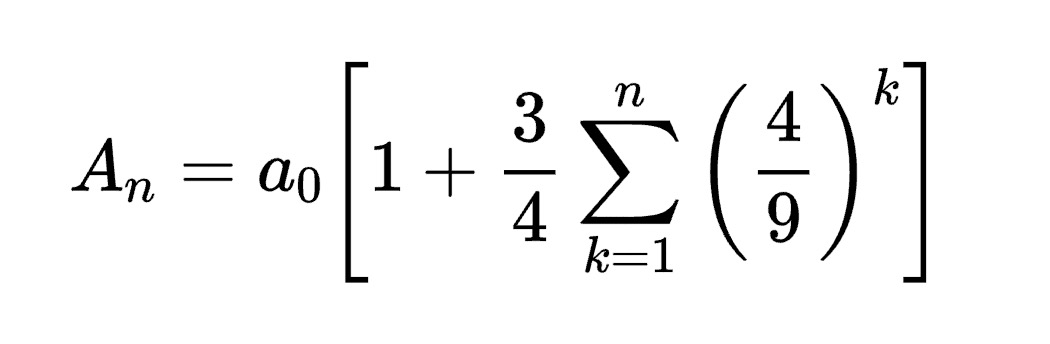Use Case 1: C++ RAG Sample that supports most popular models like LLaMA 2
This example showcases for Retrieval-Augmented Generation based on text-generation Large Language Models (LLMs): chatglm, LLaMA, Qwen and other models with the same signature and Bert model for embedding feature extraction. The sample fearures ov::genai::LLMPipeline and configures it for the chat scenario. There is also a Jupyter notebook which provides an example of LLM-powered RAG in Python.
Download and convert the model and tokenizers
The --upgrade-strategy eager option is needed to ensure optimum-intel is upgraded to the latest version.
Load: document_loaders is used to load document data.
Split: text_splitter breaks large Documents into smaller chunks. This is useful both for indexing data and for passing it in to a model, since large chunks are harder to search over and won’t in a model’s finite context window.
PostgreSQL
Download postgresql from enterprisedb.(postgresql-16.2-1-windows-x64.exe is tested)
Install PostgreSQL with postgresqltutorial. Setup of PostgreSQL: 1. Open pgAdmin 4 from Windows Search Bar. 2. Click Browser (left side) > Servers > Postgre SQL 10. 3. Create the user postgres with password openvino (or your own setting) 4. Open SQL Shell from Windows Search Bar to check this setup. 'Enter' to set Server, Database, Port, Username as default and type Password.
Server [localhost]:
Database [postgres]:
Port [5432]:
Username [postgres]:
Password for user postgres:
Open-source vector similarity search for Postgres.
By default, pgvector performs exact nearest neighbor search, which provides perfect recall. It also supports approximate nearest neighbor search (HNSW), which trades some recall for speed.
For Windows, Ensure C++ support in Visual Studio 2022 is installed, then use nmake to build in Command Prompt for VS 2022(run as Administrator). Please follow with the pgvector
Enable the extension (do this once in each database where you want to use it), run SQL Shell from Windows Search Bar with "CREATE EXTENSION vector;".
Printing CREATE EXTENSION shows successful setup of Pgvector.
pgvector support for C++ (supports libpqxx). The headers (pqxx.hpp, vector.hpp, halfvec.hpp) are copied into the local folder rag_sample\include. Our pipeline does the vector similarity search for the chunks embeddings in PostgreSQL, based on pgvector-cpp.
Install OpenVINO, VS2022 and Build this pipeline
Download 2024.2 release from OpenVINO™ archives*. This OV built package is for C++ OpenVINO pipeline, no need to build the source code. Install latest Visual Studio 2022 Community for the C++ dependencies and LLM C++ pipeline editing.
Extract the zip file in any location and set the environment variables with dragging this setupvars.bat in the terminal Command Prompt. setupvars.ps1 is used for terminal PowerShell. <INSTALL_DIR> below refers to the extraction location. Run the following CMD in the terminal Command Prompt.
Install on Windows: Copy all the DLL files of PostgreSQL, OpenVINO and tbb and openvino-genai into the release folder. The SQL DLL files locate in the installed PostgreSQL path like "C:\Program Files\PostgreSQL\16\bin".
If cmake not installed in the terminal Command Prompt, please use the terminal Developer Command Prompt for VS 2022 instead.
The openvino tokenizer in the third party needs several minutes to build. Set 8 for -j option to specify the number of parallel jobs.
Once the cmake finishes, check rag_sample_client.exe and rag_sample_server.exe in the relative path .\build\samples\cpp\rag_sample\Release.
If Cmake completed without errors, but not find exe, please open the .\build\OpenVINOGenAI.sln in VS2022, and set the solution configuration as Release instead of Debug, then build the llm project within VS2022 again.
Run
Launch RAG Server
rag_sample_server.exe --llm_model_path TinyLlama-1.1B-Chat-v1.0 --llm_device CPU --embedding_model_path bge-large-zh-v1.5 --embedding_device CPU --db_connection "user=postgres host=localhost password=openvino port=5432 dbname=postgres"
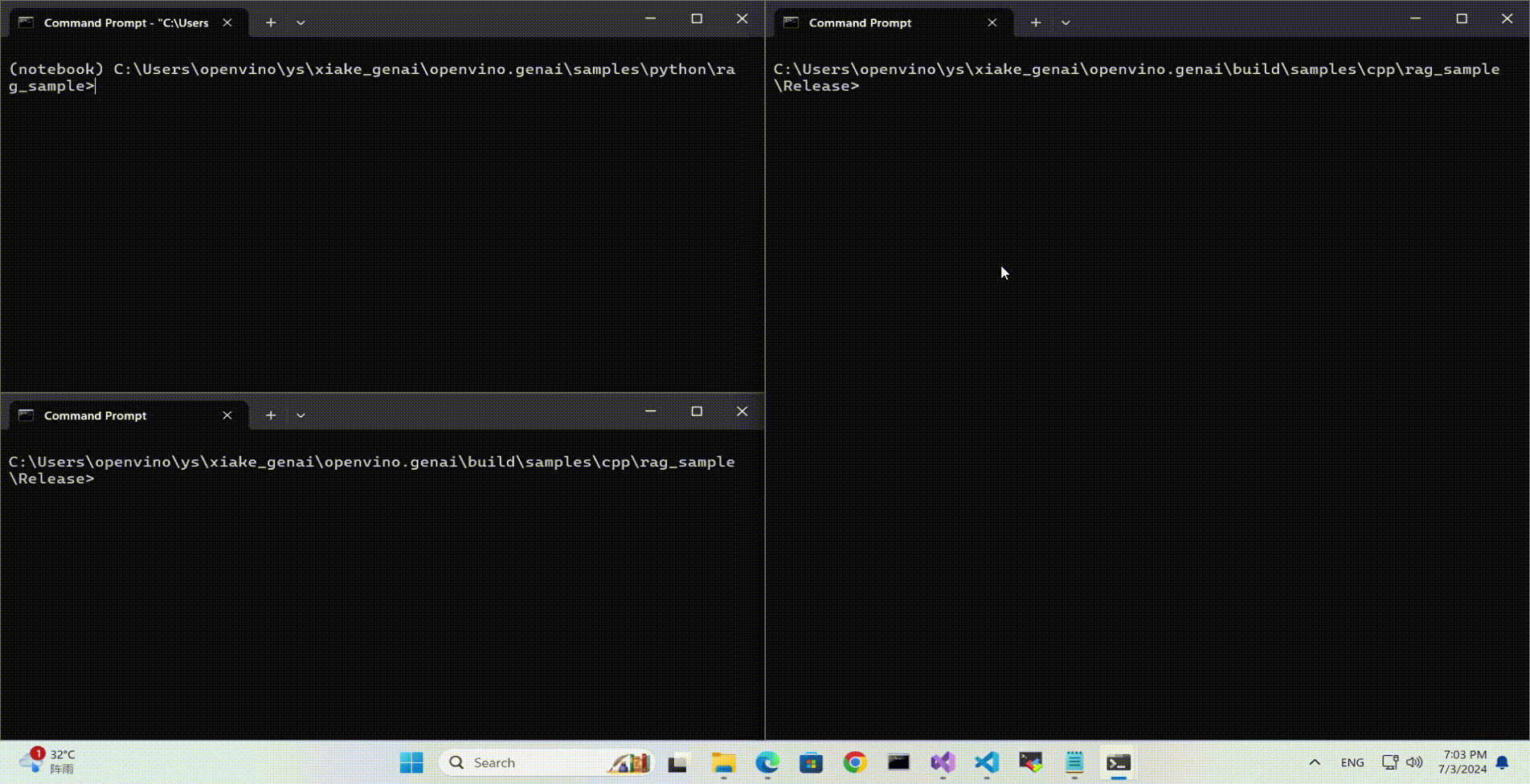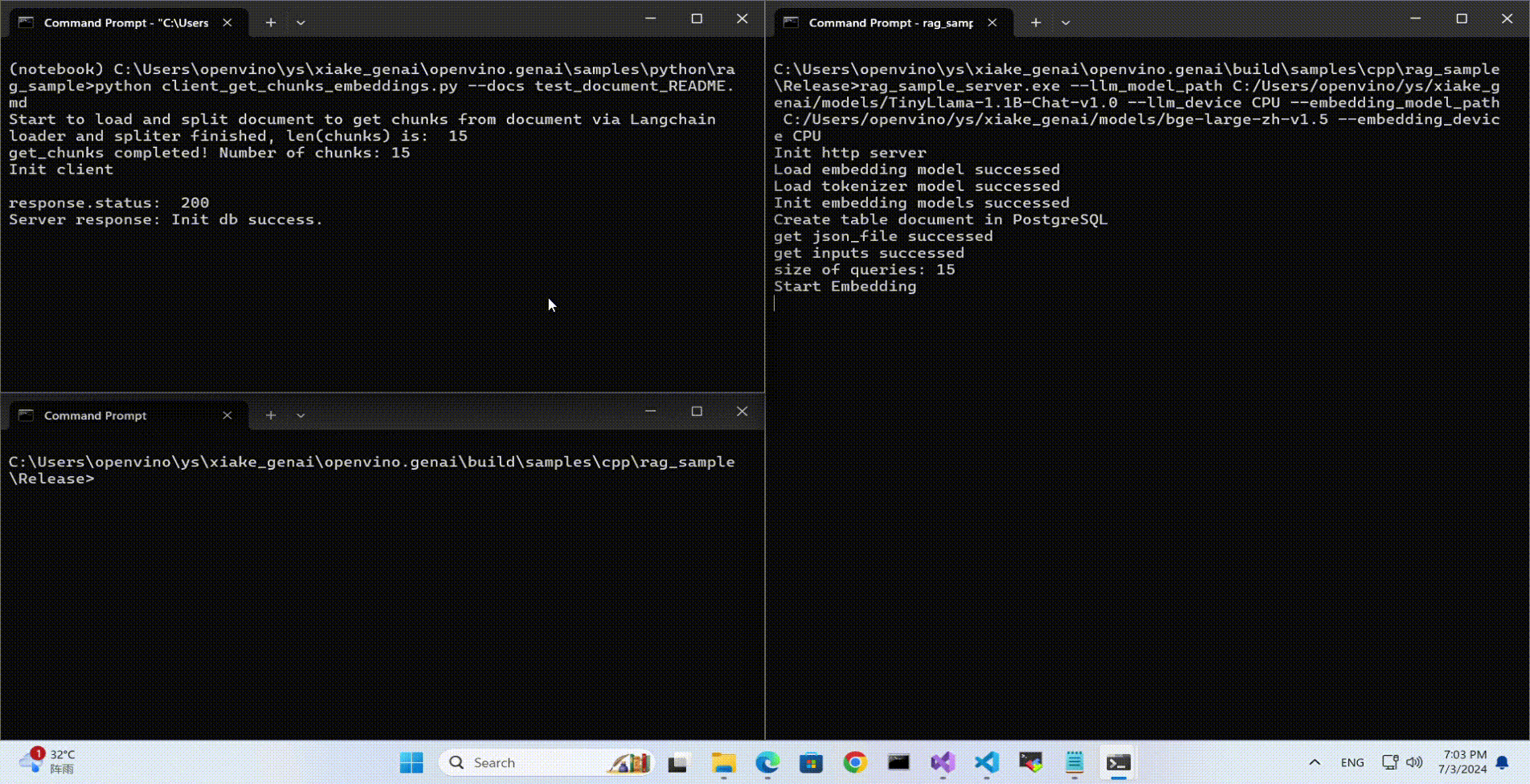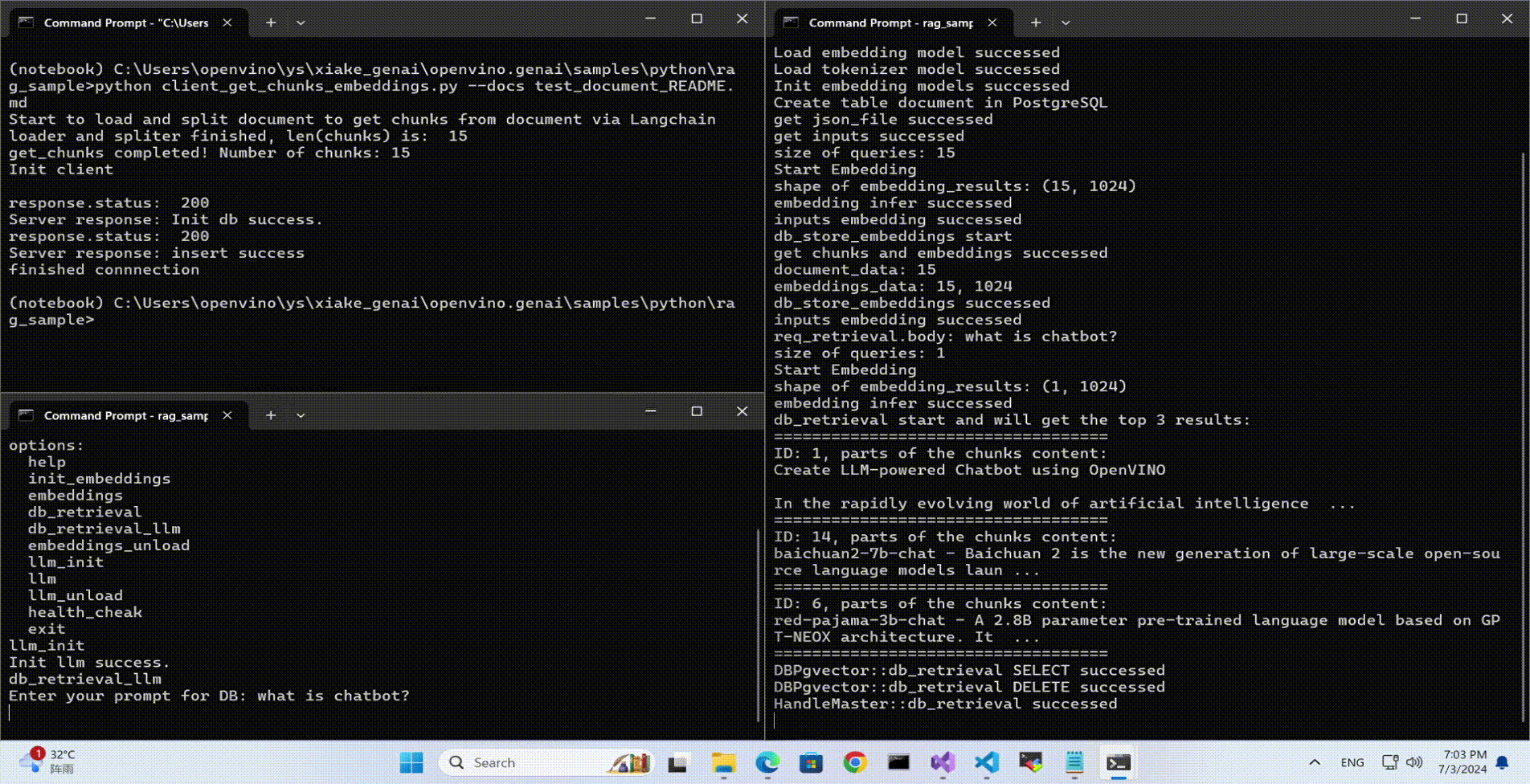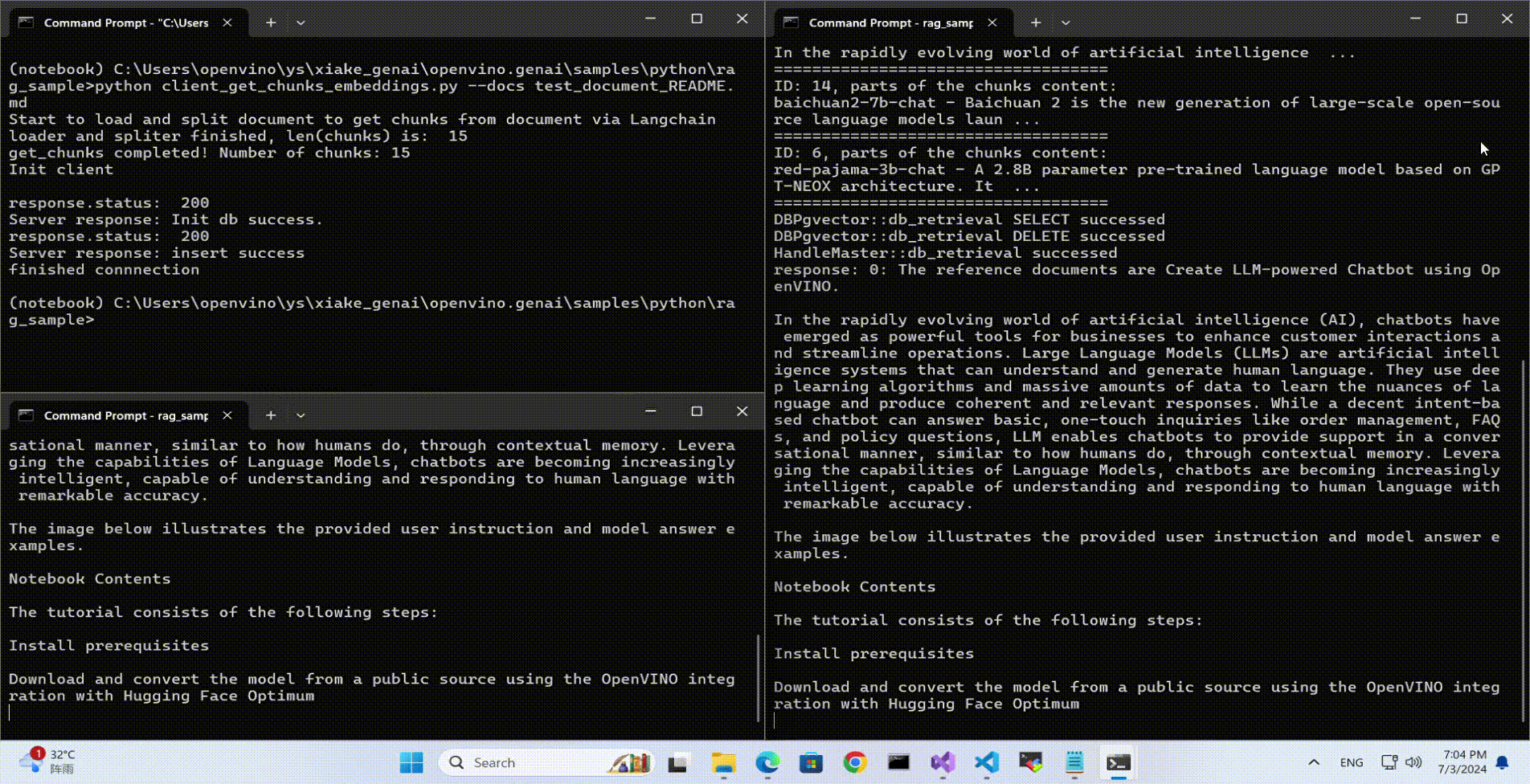
Lanuch RAG Client
rag_sample_client.exe
Lanuch python Client
Use python client to send the message of DB init and send the document chunks to DB for embedding and storing.
Starting with OpenVINO.GenAI 2025.1, the C API has been introduced, primarily to enhance interoperability with other programming languages, enabling developers to more effectively utilize OpenVINO-based generative AI across diverse coding environments.
Compared to C++, C's ABI is more stable, often serving as an interface layer or bridge language for cross-language interoperability and integration. This allows developers to leverage the performance benefits of C++ in the backend while using other high-level languages for easier implementation and integration.
As a milestone, we have currently delivered only the LLMPipeline and its associated C API interface. If you have other requirements or encounter any issues during usage, please submit an issue to OpenVINO.GenAI
Currently, we have implemented a Go application Ollama using the C API (Please refer to https://blog.openvino.ai/blog-posts/ollama-integrated-with-openvino-accelerating-deepseek-inference), which includes more comprehensive features such as performance benchmarking for developers reference.
Now, let's dive into the design logic of the C API, using a .NET C# example as a case study, based on the Windows platform with .NET 8.0.
Live Demo
Before we dive into the details, let's take a look at the final C# version of the ChatSample, which supports multi-turn conversations. Below is a live demo
How to Build a Chat Sample by C#
P/Invoke: Wrapping Unmanaged Code in .NET
First, the official GenAI C API can be found in this folder https://github.com/openvinotoolkit/openvino.genai/tree/master/src/c/include/openvino/genai/c . We also provide several pure C samples https://github.com/openvinotoolkit/openvino.genai/tree/master/samples/c/text_generation . Now, we will build our own C# Chat Sample based on the chat_sample_c. This sample can facilitate multi-turn conversations with the LLM.
C# can access structures, functions and callbacks in the unmanaged library openvino_genai_c.dll through P/Invoke. This example demonstrates how to invoke unmanaged functions from managed code.
The dynamic library openvino_genai_c.dll is imported, which relies on openvino_genai.dll. CallingConvention = CallingConvention.Cdecl here corresponds to the default calling convention _cdecl in C, which defines the argument-passing order, stack-maintenance responsibility, and name-decoration convention. For more details, refer to Argument Passing and Naming Conventions.
Additionally, the return value ov_status_e reuses an enum type from openvino_c.dll to indicate the execution status of the function. We need to implement a corresponding enum type in C#, such as
Next, we will implement our C# LLMPipeline, which inherits the IDisposable interface. This means that its instances require cleanup after use to release the unmanaged resources they occupy. In practice, object allocation and deallocation for native pointers are handled through the C interface provided by OpenVINO.GenAI. The OpenVINO.GenAI library takes full responsibility for memory management, which ensures memory safety and eliminates the risk of manual memory errors.
publicclassLlmPipeline : IDisposable
{
private IntPtr _nativePtr;
publicLlmPipeline(string modelPath, string device){
var status = NativeMethods.ov_genai_llm_pipeline_create(modelPath, device, out _nativePtr);
if (_nativePtr == IntPtr.Zero || status != ov_status_e.OK)
{
Console.WriteLine($"Error: {status} when creating LLM pipeline.");
thrownew Exception("Failed to create LLM pipeline.");
}
Console.WriteLine("LLM pipeline created successfully!");
}
publicvoidDispose(){
if (_nativePtr != IntPtr.Zero)
{
NativeMethods.ov_genai_llm_pipeline_free(_nativePtr);
_nativePtr = IntPtr.Zero;
}
GC.SuppressFinalize(this);
}
// Other Methods}
Callback Implementation
Next, let's implement the most complex method of the LLMPipeline, the GenerateStream method. This method encapsulates the LLM inference process. Let's take a look at the original C code. The result can be retrieved either via ov_genai_decoded_results or streamer_callback. ov_genai_decoded_results provides the inference result all at once, while streamer_callback allows for streaming inference results. ov_genai_decoded_results or streamer_callback must be non-NULL; neither can be NULL at the same time. For more information please refer to the comments https://github.com/openvinotoolkit/openvino.genai/blob/master/src/c/include/openvino/genai/c/llm_pipeline.h
// code snippets from //https://github.com/openvinotoolkit/openvino.genai/blob/master/src/c/include/openvino/genai/c/llm_// pipeline.h typedefenum { OV_GENAI_STREAMMING_STATUS_RUNNING = 0, // Continue to run inference OV_GENAI_STREAMMING_STATUS_STOP =
1, // Stop generation, keep history as is, KV cache includes last request and generated tokens OV_GENAI_STREAMMING_STATUS_CANCEL = 2// Stop generate, drop last prompt and all generated tokens from history, KV// cache includes history but last step} ov_genai_streamming_status_e;
// ...typedefstruct { ov_genai_streamming_status_e(
OPENVINO_C_API_CALLBACK* callback_func)(constchar* str, void* args); //!< Pointer to the callback functionvoid* args; //!< Pointer to the arguments passed to the callback function} streamer_callback;
// ...OPENVINO_GENAI_C_EXPORTS ov_status_e ov_genai_llm_pipeline_generate(ov_genai_llm_pipeline* pipe,
constchar* inputs,
const ov_genai_generation_config* config,
const streamer_callback* streamer,
ov_genai_decoded_results** results);
The streamer_callback structure includes not only the callback function itself, but also an additional void* args for enhanced flexibility. This design allows developers to pass custom context or state information to the callback.
For example, in C++ it's common to pass a this pointer through args, enabling the callback function to access class members or methods when invoked.
// args is a this pointervoidcallback_func(constchar* str, void* args){
MyClass* self = static_cast<MyClass*>(args);
self->DoSomething();
}
This C# code defines a class StreamerCallback that helps connect a C callback function with a C# method. It wraps a C function pointer MyCallbackDelegate and a void* args into a struct.
- ToNativePTR method constructs the streamer_callback structure, allocates a block of memory, and copies the structure's data into it, allowing it to be passed to a native C function.
- GCHandle is used to safely pin the C# object so that it can be passed as a native pointer to unmanaged C code.
- CallbackWrapper method is the actual function that C code will call.
[UnmanagedFunctionPointer(CallingConvention.Cdecl)]
public delegate ov_genai_streamming_status_e MyCallbackDelegate(IntPtr str, IntPtr args);
[StructLayout(LayoutKind.Sequential)]
publicstructstreamer_callback{public MyCallbackDelegate callback_func;
public IntPtr args;
}
publicclassStreamerCallback : IDisposable
{
public Action<string> OnStream;
public MyCallbackDelegate Delegate;
private GCHandle _selfHandle;
publicStreamerCallback(Action<string> onStream){
OnStream = onStream;
Delegate = new MyCallbackDelegate(CallbackWrapper);
_selfHandle = GCHandle.Alloc(this);
}
public IntPtr ToNativePtr(){
var native = new streamer_callback
{
callback_func = Delegate,
args = GCHandle.ToIntPtr(_selfHandle)
};
IntPtr ptr = Marshal.AllocHGlobal(Marshal.SizeOf<streamer_callback>());
Marshal.StructureToPtr(native, ptr, false);
return ptr;
}
publicvoidDispose(){
if (_selfHandle.IsAllocated)
_selfHandle.Free();
}
private ov_genai_streamming_status_e CallbackWrapper(IntPtr str, IntPtr args){
string content = Marshal.PtrToStringAnsi(str) ?? string.Empty;
if (args != IntPtr.Zero)
{
var handle = GCHandle.FromIntPtr(args);
if (handle.Target is StreamerCallback self)
{
self.OnStream?.Invoke(content);
}
}
return ov_genai_streamming_status_e.OV_GENAI_STREAMMING_STATUS_RUNNING;
}
}
Then We implemented the GenerateStream method in class LLMPipeline.
publicvoidGenerateStream(string input, GenerationConfig config, StreamerCallback? callback = null){
IntPtr configPtr = config.GetNativePointer();
IntPtr decodedPtr;// placeholder IntPtr streamerPtr = IntPtr.Zero;
if (callback != null)
{
streamerPtr = callback.ToNativePtr();
}
var status = NativeMethods.ov_genai_llm_pipeline_generate(
_nativePtr,
input,
configPtr,
streamerPtr,
out decodedPtr
);
if (streamerPtr != IntPtr.Zero)
Marshal.FreeHGlobal(streamerPtr);
callback?.Dispose();
if (status != ov_status_e.OK)
{
Console.WriteLine($"Error: {status} during generation.");
thrownew Exception("Failed to generate results.");
}
return;
}
We use the following code to invoke our callback and GenerateStream.
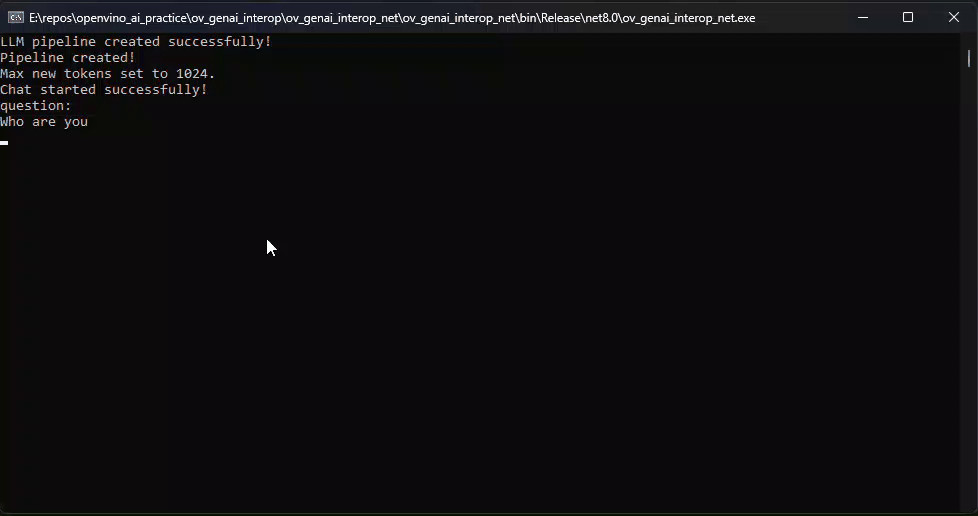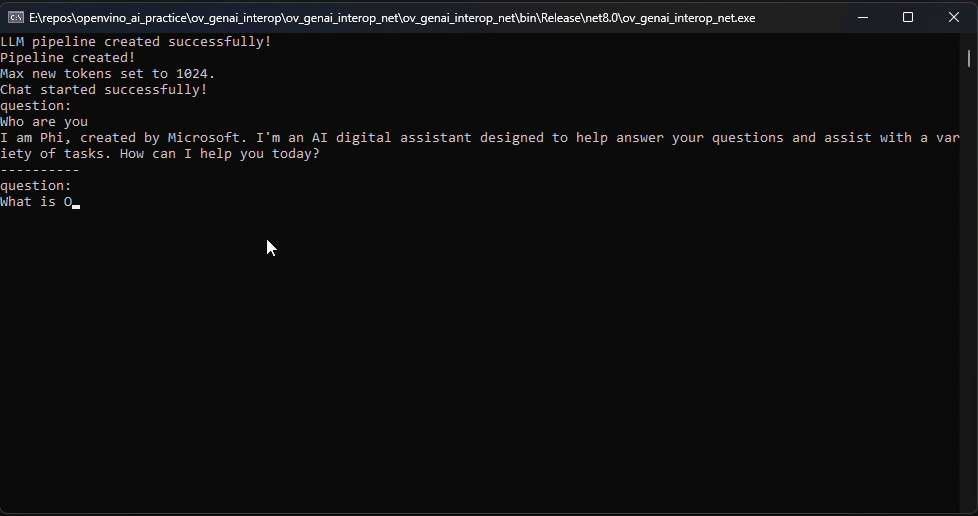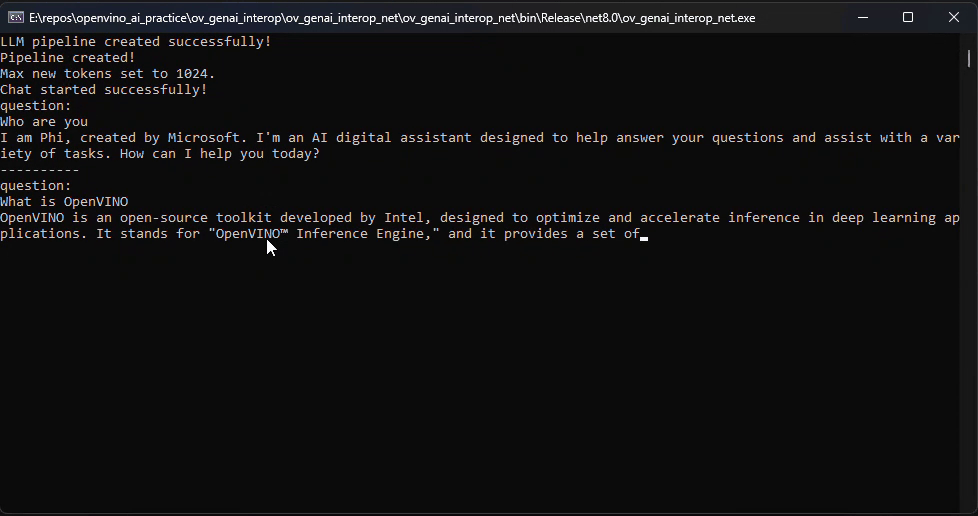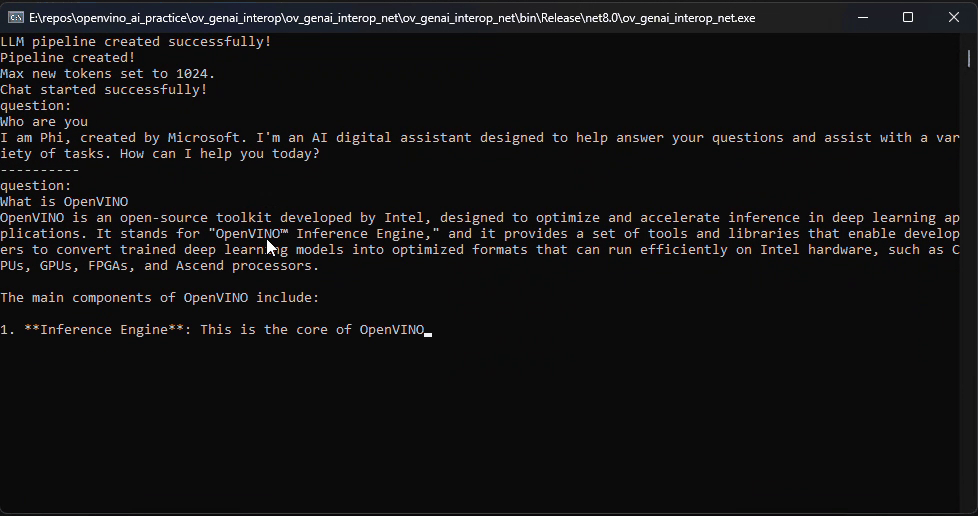
pipeline.StartChat(); // Start chat with keeping history in kv cache.Console.WriteLine("question:");
while (true)
{
string? input = Console.ReadLine();
if (string.IsNullOrWhiteSpace(input)) break;
using var streamerCallback = new StreamerCallback((string chunk) =>
{
Console.Write(chunk);
});
pipeline.GenerateStream(input, generationConfig, streamerCallback);
input = null;
Console.WriteLine("\n----------\nquestion:");
}
pipeline.FinishChat(); // Finish chat and clear history in kv cache.
About Deployment
We can directly download the OpenVINO official release of the LLM's IR from Hugging Face using this link.
The OpenVINO.GenAI 2025.1 package can be downloaded via this link.
The C# project directly depends on openvino_genai_c.dll, which in turn has transitive dependencies on other toolkit-related DLLs, including Intel TBB libraries.
To ensure proper runtime behavior, all the DLLs delivered with OpenVINO.GenAI — including openvino_genai_c.dll and its dependencies — are bundled and treated as part of the C# project’s runtime dependencies.
We use the following cmd commands to download the genai package and copy all the required dependent DLLs to the directory containing the *.csproj file.
The integration of Ollama and OpenVINO delivers a powerful dual-engine solution for the management and inference of large language models (LLMs). Ollama offers a streamlined model management toolchain, while OpenVINO provides efficient acceleration capabilities for model inference across Intel hardware (CPU/GPU/NPU). This combination not only simplifies the deployment and invocation of models but also significantly enhances inference performance, making it particularly suitable for scenarios demanding high performance and ease of use.
You can find more information on github repository:
1. Streamlined LLM Management Toolchain: Ollama provides a user-friendly command-line interface, enabling users to effortlessly download, manage, and run various LLM models.
2. One-Click Model Deployment: With simple commands, users can quickly deploy and invoke models without complex configurations.
3. Unified API Interface: Ollama offers a unified API interface, making it easy for developersto integrate into various applications.
4. Active Open-Source Community: Ollama boasts a vibrant open-source community, providing users with abundant resources and support.
Limitations of Ollama
Currently, Ollama only supports llama.cpp as itsbackend, which presents some inconveniences:
1. Limited Hardware Compatibility: llama.cpp is primarily optimized for CPUs and NVIDIA GPUs, and cannot fully leverage the acceleration capabilities of Intel GPUs or NPUs, resulting in suboptimal performance in high-performance computing scenarios.
2.Performance Bottlenecks: For large-scale models or high-concurrency scenarios, the performance of llama.cpp may fall short, especially when handling complex tasks, leading to slower inference speeds.
Breakthrough Capabilities of OpenVINO
1. Deep Optimization for Intel Hardware (CPU/iGPU/Arc dGPU/NPU): OpenVINO is deeply optimized for Intel hardware, fully leveraging the performance potential of CPUs, iGPUs, dGPUs, and NPUs.
2. Cross-Platform Heterogeneous Computing Support: OpenVINO supports cross-platform heterogeneous computing, enabling efficient model inference across different hardware platforms.
3. Model Quantization and Compression Toolchain: OpenVINO provides a comprehensive toolchain for model quantization and compression, significantly reducing model size and improving inference speed.
4. Significant Inference Performance Improvement: Through OpenVINO's optimizations, model inference performance can be significantly enhanced, especially for large-scale models and high-concurrency scenarios.
5. Extensibility and Flexibility Support: OpenVINO GenAI offers robust extensibility and flexibility for Ollama-OV, supporting pipeline optimization techniques such as speculative decoding, prompt-lookup decoding, pipeline parallelization, and continuous batching, laying a solid foundation for future pipeline serving optimizations.
Developer Benefits of Integration
1.Simplified Development Experience: Retains Ollama's CLI interaction features, allowing developers to continue using familiar command-line tools for model management and invocation.
2.Performance Leap: Achieves hardware-level acceleration through OpenVINO, significantly boosting model inference performance, especially for large-scale models and high-concurrency scenarios.
3.Multi-Hardware Adaptation and Ecosystem Expansion: OpenVINO's support enables Ollama to adapt to multiple hardware platforms, expanding its application ecosystem and providing developers with more choices and flexibility.
For Windows systems, first extract the downloaded OpenVINO GenAI package to the directory openvino_genai_windows_2025.2.0.0.dev20250320_x86_64, then execute the following commands:
cd openvino_genai_windows_2025.2.0.0.dev20250320_x86_64
setupvars.bat
3. Set Up cgocheck
Windows:
set GODEBUG=cgocheck=0
Linux:
export GODEBUG=cgocheck=0
At this point, the executable files have been downloaded, and the OpenVINO GenAI, OpenVINO, and CGO environments have been successfully configured.
Custom Model Deployment Guide
Since the Ollama Model Library does not support uploading non-GGUF format IR models, we will create an OCI image locally using OpenVINO IR that is compatible with Ollama. Here, we use the DeepSeek-R1-Distill-Qwen-7B model as an example:
With these steps, we have successfully created the DeepSeek-R1-Distill-Qwen-7B-int4-ov:v1 model, which is now ready for use with the Ollama OpenVINO backend.
Janus is a unified multimodal understanding and generation model developed by DeepSeek. Janus proposed decoupling visual encoding to alleviate the conflict between multimodal understanding and generation tasks. Janus-Pro further scales up the Janus model to larger model size (deepseek-ai/Janus-Pro-1B & deepseek-ai/Janus-Pro-7B) with optimized training strategy and training data, achieving significant advancements in both multimodal understanding and text-to-image tasks.
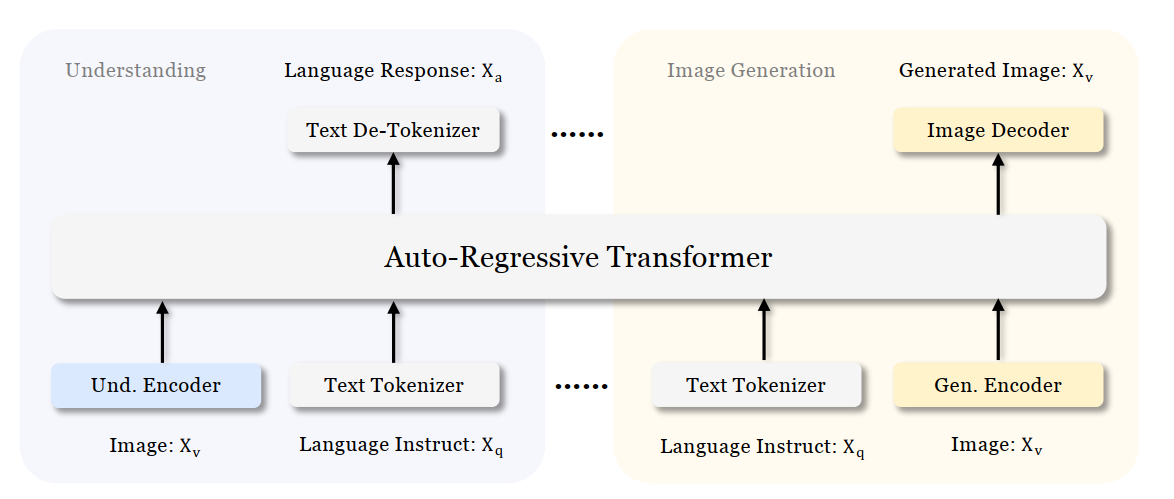
Figure 1: Overview of Janus-Pro Architecture
Figure 1 shows the architecture of Janus-Pro, which decouples visual encoding for multimodal understanding and visual generation. “Und. Encoder” and “Gen. Encoder” are abbreviations for “Understanding Encoder” and “Generation Encoder”. For the multimodal understanding task, SigLIP vision encoder used to extract high-dimensional semantic features from the image, while for the vision generation task, VQ tokenizer used to map images to discrete IDs. Both the understanding adaptor and the generation adaptor are two-layer MLPs to map the embeddings to the input space of LLM.
In this blog, we will introduce how to deploy Janus-Pro model with OpenVINOTM runtime on the intel platform.
2. Janus-Pro Pytorch Model to OpenVINOTM Model Conversion
The converted OpenVINO will be saved in Janus-Pro-1B-OV directory for deployment.
3. Janus-Pro Inference with OpenVINOTM Demo
In this section, we provide several examples to show Janus-Pro for multimodal understanding and vision generation tasks.
3.1. Multimodal Understanding Task – Image Caption with OpenVINOTM
$ python run_janus_vlm_ov.py -m Janus-Pro-1B-OV -p "Describe image in det
ails" -i images/cat_in_box.png -d GPU
Prompt: Describe image in details
Input image:
Generated Output:
The image shows a gray tabby cat lying inside an open cardboard box on a carpeted floor. The cat is lying on its back with its belly exposed, looking relaxed and comfortable. The background includes a beige-colored sofa and a light-colored curtain,
suggesting a cozy indoor setting. The cat's tail is curled around its body, and it appears to be enjoying itself.
3.2. Multimodal Understanding Task – Equation Description with OpenVINOTM
$ python run_janus_vlm_ov.py -m Janus-Pro-1B-OV -p "Generate the latex code of this formula" -i images/equation.png -d GPU
Prompt: Generate the latex code of this formula
Input Image:
Generated Output:
\[ A_n = a_0 \begin{bmatrix} 1 & + \frac{3}{4} \sum_{k=1}^{n} \begin{bmatrix} 4 \\ 9 \end{bmatrix}^k \end{bmatrix} \]
This formula represents the cumulative sum of the first \( n \) terms of the sequence \( a_n \), where \( a_n \) is the sequence of \( a_0 \), \( \frac{3}{4} \), and \( \begin{bmatrix} 4 \\ 9 \end{bmatrix}^k \). The first term \( a_0 \) is the first term of the sequence, the second term is the sum of the first \( n-1 \) terms, and the third term is the sum of the first \( n \) terms. The sequence \( \begin{bmatrix} 4 \\ 9 \end{bmatrix}^k \) represents the \( k \)-th term of the sequence. The
formula calculates the cumulative sum of the sequence \( a_n \).
This formula can be used to calculate the cumulative sum of the sequence \( a_n \) for any given \( n \).
3.3. Multimodal Understanding Task – Code Generation with OpenVINOTM
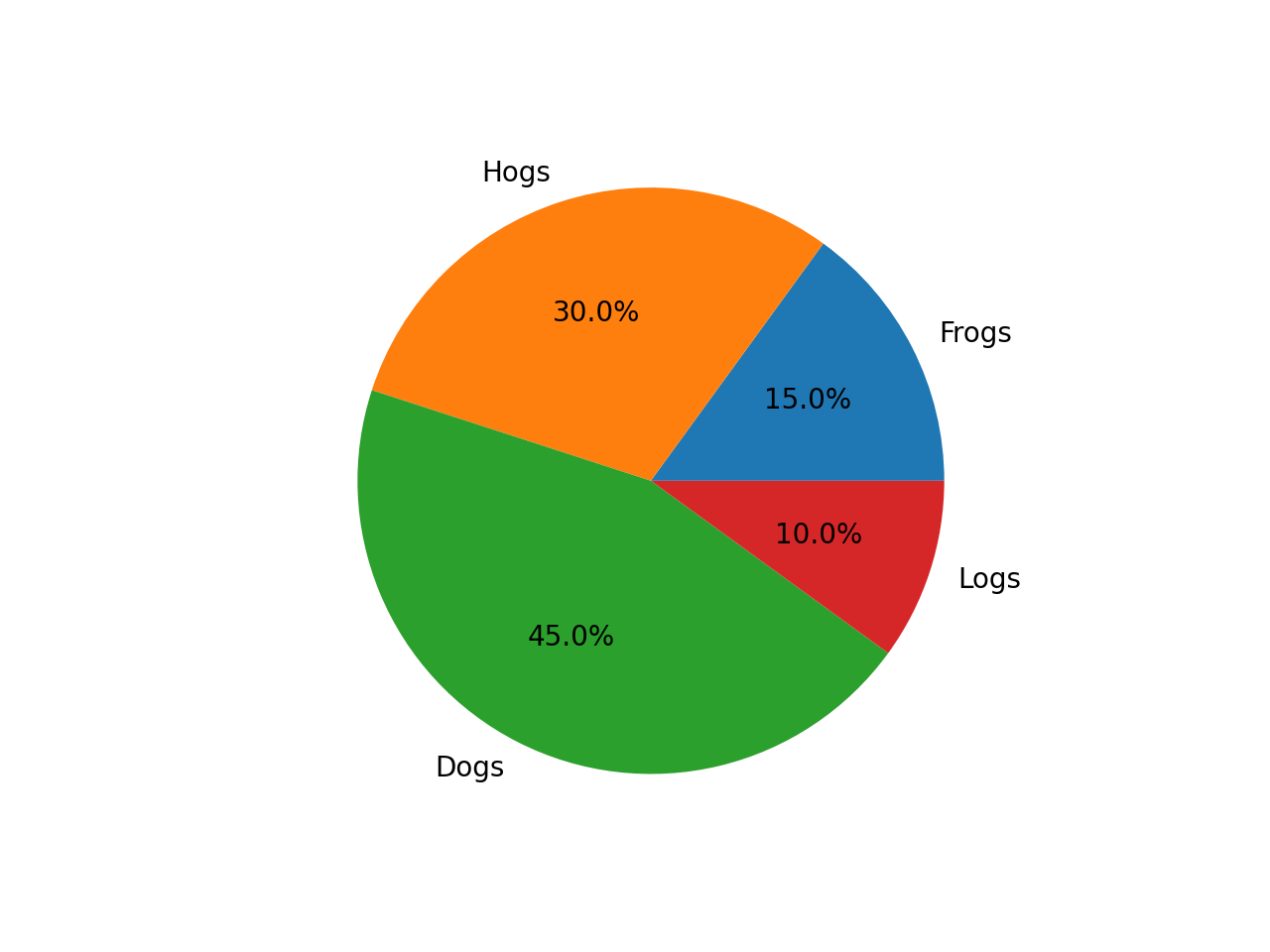
$ python run_janus_vlm_ov.py -m Janus-Pro-1B-OV -p "Generate the matplotlib pyplot code for this plot" -i images\pie_chart.png -d GPU
Prompt: Generate the matplotlib pyplot code for this plot
Input Image:
Generated Output:
The attention mask is not set and cannot be inferred from input because pad token is same as eos token. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Sure, here is the code to generate the matplotlib plot based on the information in the image:
```python
import matplotlib.pyplot as plt
# Data
data = {
'Hogs': 30,
'Frogs': 15,
'Logs': 10,
'Dogs': 45
}
# Create the plot
plt.figure(figsize=(10, 6))
# Pie chart
for key, value in data.items():
# Calculate the percentage of the pie chart
percentage = value / 100
# Add the pie slice
plt.pie(percentage, labels=data.keys(), autopct='%1.1f%%')
# Title and labels
plt.title('Pie chart')
plt.xlabel('Categories')
plt.ylabel('Percentage')
# Show the plot
plt.show()
```
This code will create a pie chart based on the data provided in the image.
Input Prompt: A cute and adorable baby fox with big brown eyes, autumn leaves in the background enchanting, immortal, fluffy, shiny mane, Petals, fairyism, unreal engine 5 and Octane Render, highly detailed, photorealistic, cinematic, natural colors.
We also provide benchmark scripts to evaluate Janus-Pro model performance and memory usage with OpenVINOTM inference, you may specify model name and device for your target platform.
4.1. Benchmark Janus-Pro for Multimodal Understanding Task with OpenVINOTM
Here are some arguments for benchmark script for Multimodal Understanding Task:
--model_id: specify the Janus OpenVINOTM model directory
--prompt: specify input prompt for multimodal understanding task
--image_path: specify input image for multimodal understanding task
--niter: specify number of test iteration, default is 5
--device: specify which device to run inference
--max_new_tokens: specify max number of generated tokens
By default, the benchmark script will run 5 round multimodal understanding tasks on target device, then report pipeline initialization time, average first token latency (including preprocessing), 2nd+ token throughput and max RSS memory usage.
4.2. Benchmark Janus-Pro for Text-to-Image Task with OpenVINOTM
Here are some arguments for benchmark scripts for Text-to-Image Task
--model_id: specify the Janus OpenVINO TM model directory
--prompt: specify input prompt for text-to-image generation task
--niter: specify number of test iteration
--device: specify which device to run inference
By default, the benchmark script will run 5 round image generation tasks on target device, then report the pipeline initialization time, average image generation latency and max RSS memory usage.
5. Conclusion
In this blog, we introduced how to enable Janus-Pro model with OpenVINOTM runtime, then we demonstrated the Janus-Pro capability for various multimodal understanding and image generation tasks. In the end, we provide python script for performance & memory usage evaluation for both multimodal understanding and image generation task on target platform.

.png)