
.png)
Alexande
Kozlov
August 21, 2024
Q2'24: Technology Update – Low Precision and Model Optimization
Authors
Alexander Kozlov, Nikita Savelyev, Vui Seng Chua, Souvikk Kundu, Nikolay Lyalyushkin, Andrey Anufriev, Pablo Munoz, Alexander Suslov, Liubov Talamanova, Yury Gorbachev, Nilesh Jain, Maxim Proshin
Summary
This quarter we see an increasing interest in KV-cache optimization of Large Language and Vision Models. This actually expected as KV-cache is getting a bottleneck after the weight compression problem is solved to some degree. We also believe that KV-cache optimization will continue being a hot topic as it is also involved in the Video Generations scenario where we see a lot of work going on nowadays.
Highlights
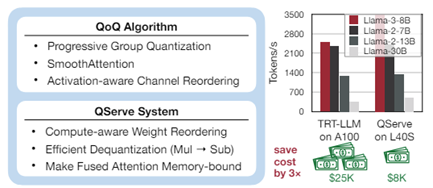
- QServe: W4A8KV4 Quantization and System Co-design for Efficient LLM Serving by MIT, NVIDIA, UMass Amherst, MIT-IBM Watson AI Lab (https://arxiv.org/pdf/2405.04532). A regular work from Song Han Lab which is a comprehensive study of deep LLM optimization and a reference design of a tool for LLM serving. The LLM optimization part includes: W4A8 and 4-bit KV-cache quantization approach; Progressive quantization of weights, to comply with 8-bit compute after dequantizing4-bit weights to 8-bits; SmoothAttention method, to reduce the error of 4-bit quantization of Key cache that is compatible with RoPE operation and can be fused into a preceding Linear layer; Progressive quantization of weights, to comply with 8-bit compute after dequantizing4-bit weights to 8-bits. The inference part contains tips and tricks to design efficient inference kernels and execution pipelines on the Nvidia GPUs. The method shows superior results comparing to competitive solutions and demonstrates the ability to substantially reduce LLM serving costs. Some code and pre-compiled binaries are available here: https://github.com/mit-han-lab/qserve.
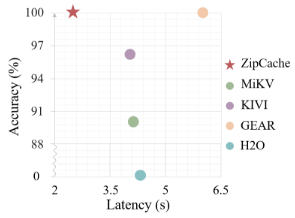
- ZipCache: Accurate and Efficient KV Cache Quantization with Salient Token Identification by Houmo AI and Chinese universities (https://arxiv.org/pdf/2405.14256).Authors present a KV cache quantization method for LLMs. First, they construct a strong baseline for quantizing KV cache. Through the proposed channel-separable token-wise quantization scheme, the memory overhead of quantization parameters is substantially reduced compared to fine-grained group-wise quantization. To enhance the compression ratio, they propose a normalized attention score. The quantization bit-width for each token is adaptively assigned based on their saliency. The authors also develop an approximation method that decouples the saliency metric from full attention scores compatible with FlashAttention. Experiments demonstrate that the method achieves good compression ratios at fast generation speed, for example, when evaluating Mistral-7B model on GSM8k dataset, the method is capable of compressing the KV cache by 4.98×,with only a 0.38% drop in accuracy.
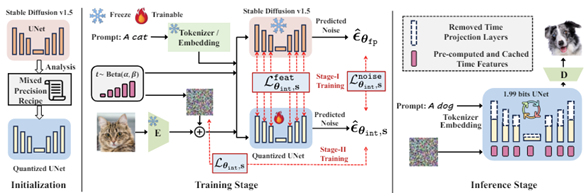
- BitsFusion: 1.99 bits Weight Quantization of Diffusion Model by Snap Inc. and Rutgers University (https://arxiv.org/pdf/2406.04333). The paper provides a thorough analysis of UNet weight-only quantization of Stable Diffusion 1.5 model. The authors propose an approach for mixed-precision quantization of diffusers. They quantize different layers into different bits according to their quantization error. The authors also introduce several techniques to initialize the quantized model to improve performance, including time embedding pre-computing and caching, adding balance integer, and alternating optimization for scaling factor initialization. Finally, they propose a two-stage Quantization-aware training where distillation is used at the first stage. The quantized model achieves very good results on various benchmarks. Code will be released here: https://github.com/snap-research/BitsFusion.
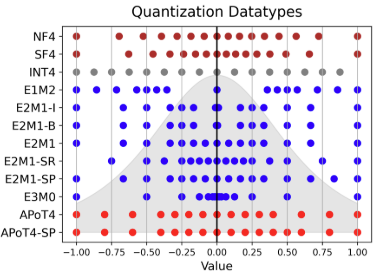
- Applying t-Distributions to Explore Accurate and Efficient Format[KA1] s for LLMs by Cornell University and Google (https://arxiv.org/abs/2405.03103). The paper investigates non-uniform quantization data formats by profiling the distributions of weight and activation across 30 models, including both LLM and non-LLM models. The authors discovered that Student’s t-Distribution is a better fit than the Gaussian distribution due to its flexible parameterization, which can resemble Gaussian, Cauchy, or other distributions observed indifferent neural networks. The authors derived Student Float (SF4) using a similar design process to Normal Float (NF4). SF4 outperforms NF4, FP4, and Int4 in accuracy retention across most cases and model architectures, making it a strong drop-in replacement for lookup-based datatypes like NF4. The paper proposes using SF4as a reference to extend supernormal support for existing datatypes like E2M1(one variant of FP4) and APoT4,by reassigning negative zero to a useful value, which is otherwise wasted. Additionally, the paper examines the Pareto frontier of datatypes in terms of model accuracy and MAC chip area, concluding that APoT4 and its supernormal extension are Pareto optimal for a set of models smaller than 7B parameters.
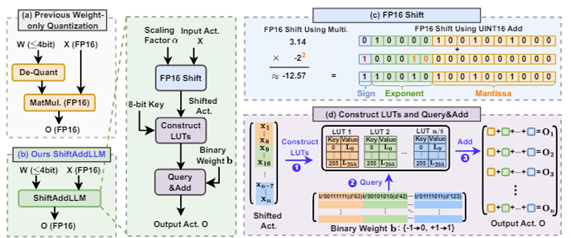
- ShiftAddLLM: MatMul-free LLM via Inference Time Reparameterization by Intel, Google Deep Mind, Google, Georgia Tech (https://arxiv.org/pdf/2406.05981).Authors developed an inference time reparameterization for traditional LLMs layers with MatMul ops to convert them to layers with Shift-Add and LUT query-based operations only. Specifically, authors quantize each weight matrix into binary matrices paired with group-wise scaling factors. The associated multiplications are reparameterized into (1) shifts between activations and scaling factors and (2) queries and adds according to the binary matrices. To reduce accuracy loss, they present a multi-objective optimization method to minimize both weight and output activation reparameterization errors. Additionally, based on varying sensitivity across layers to reparameterization, they develop an automated bit allocation strategy to further reduce memory usage and latency. The code is available at: https://github.com/GATECH-EIC/ShiftAddLLM.
Quantization
- QServe: W4A8KV4 Quantization and System Co-design for Efficient LLM Serving by MIT, NVIDIA, UMass Amherst, MIT-IBM Watson AI Lab (https://arxiv.org/pdf/2405.04532). A regular work from Song Han Lab which is a comprehensive study of deep LLM optimization and a reference design of a tool for LLM serving. The LLM optimization part includes: W4A8 and 4-bit KV-cache quantization approach; Progressive quantization of weights, to comply with 8-bit compute after dequantizing4-bit weights to 8-bits; SmoothAttention method, to reduce the error of 4-bit quantization of Key cache that is compatible with RoPE operation and can be fused into a preceding Linear layer; Progressive quantization of weights, to comply with 8-bit compute after dequantizing4-bit weights to 8-bits. The inference part contains tips and tricks to design efficient inference kernels and execution pipelines on the Nvidia GPUs. The method shows superior results comparing to competitive solutions and demonstrates the ability to substantially reduce LLM serving costs. Some code and pre-compiled binaries are available here: https://github.com/mit-han-lab/qserve.
- LQER: Low-Rank Quantization Error Reconstruction for LLMs by Imperial College London London and University of Cambridge (https://arxiv.org/pdf/2402.02446). The paper combines quantization and low-rank approximation techniques to achieve accurate and efficient LLM optimization. The method employs MXINT4 datatype (int4 + shared exponent for 4 elements) for weight quantization while quantizing activation into 8 or 6 bits with per-token scaling factors. The method also introduces 8-bit LoRA adapters to restore accuracy after weight quantization. It does not use any kind of fine-tuning. Instead, it introduces the error decomposition into two low-rank matrices. The method achieves very accurate results in W4A8 and W4A6 settings, especially on Llama-2 model family.
- LLM-QBench: A Benchmark Towards the Best Practice for Post-training Quantization of Large Language Models by Beihang University, SenseTime Research, and Nanyang Technological University (https://arxiv.org/pdf/2405.06001).The paper focuses on identifying the most effective practices for quantizing LLMs, with the goal of balancing performance with computational efficiency. Fora fair analysis, the authors develop a quantization toolkit LLMC and design four crucial principles considering the inference efficiency, quantized accuracy, calibration cost, and modularization. By benchmarking on various models and datasets with over 500 experiments, three takeaways corresponding to calibration data, quantization algorithm, and quantization schemes are derived. Finally, a best practice of LLM PTQ pipeline is constructed. All the benchmark results and the toolkit can be found at https://github.com/ModelTC/llmc.
- SKVQ: Sliding-window Key and Value Cache Quantization for Large Language Models Houmo AI by Houmo AI and Chinese universities (https://arxiv.org/pdf/2405.06219). The paper addresses the problem of extremely low bit-width KV cache quantization. To achieve this, it proposes a method that rearranges the channels of the KV cache in order to improve the similarity of channels in quantization groups and applies clipped dynamic quantization at the group level. Additionally, the method ensures that the most recent window tokens in the KV cache are preserved with high precision. This helps maintain the accuracy of a small but important portion of the KV cache. Evaluation on LLMs demonstrates that the method surpasses previous quantization approaches, allowing for quantization of the KV cache to 2-bit keys and 1.5-bit values with minimal loss of accuracy. The code is available at https://github.com/cat538/SKVQ.
- Integer Scale: A Free Lunch for Faster Fine-grained Quantization of LLMs by Meituan (https://arxiv.org/pdf/2405.14597). The paper proposes a scheme to use integer scales when computing dot products of W4A8quantized LLMs. It allows keeping group scales for weights in the integer precision as well and using INT32 buffer as the accumulator of partial dot products. An additional floating point scale is required and applied to the super-group of dot products between weights and activations. It brings the proposed method close to the known double quantization approach. The paper provides extensive evaluation data for Llama2 and Llama3 models showing close results to the baseline floating-point scales.
- Mitigating Quantization Errors Due to Activation Spikes in GLU-Based LLMs by Hanyang University (https://arxiv.org/pdf/2405.14428).The paper aims at reducing the accuracy degradation of fully-quantized LLM models (both weights and activations are quantized). Authors propose two empirical methods, Quantization-free Module (QFeM) and Quantization-free Prefix (QFeP), to isolate the activation spikes during quantization that cause most of the accuracy drop. Essentially, they propose a way to identify what layers are more error-prone and keep these layers in the floating-point precision. The code is available at https://github.com/onnoo/activation-spikes.
- AdpQ: A Zero-shot Calibration Free Adaptive Post Training Quantization Method for LLMs by Huawei Noah Lab and McGill University (https://arxiv.org/pdf/2405.13358).This paper presents a novel zero-shot adaptive PTQ method for LLMs that does not require any calibration data. Inspired by Adaptive LASSO regression model, the authors proposed approach that tackles the challenge of outlier activations by separating salient weights using an adaptive soft-thresholding method. Guided by Adaptive LASSO, this method ensures that the quantized weights distribution closely follows the originally trained weights and eliminates the need for calibration data entirely. The method achieves good results at much faster quantization time.
- PTQ4SAM: Post-Training Quantization for Segment Anything by Beihang University (https://arxiv.org/pdf/2405.03144).A practical study on quantization of the Segment Anything model. The authors observe a challenging bimodal distribution for quantization and analyze its characteristics. To overcome it, they propose a Bimodal Integration (BIG)strategy, which automatically detects it and transforms the bimodal distribution to normal distribution equivalently. They also present the Adaptive Granularity Quantization which represents diverse post-Softmax distributions accurately with appropriate granularity. Experiments show that the method can achieve good results even in low-bit quantization settings (6 or4 bits). Code is available at https://github.com/chengtao-lv/PTQ4SAM.
- QNCD: Quantization Noise Correction for Diffusion Models by Kuaishou Technology (https://arxiv.org/pdf/2403.20137). Authors identify two primary quantization challenges for Duffusion models: intra and inter quantization noise. Intra quantization noise, exacerbated by embeddings in the resblock module, extends activation quantization ranges, increasing disturbances in each single denoising step. Besides, inter quantization noise stems from cumulative quantization deviations across the entire denoising process, altering data distributions step-by-step. Authors propose embedding-derived feature smoothing for eliminating intra quantization noise and a runtime noise estimation module for dynamically filtering inter quantization noise. Experiments demonstrate that the method achieves good results in W4A8 and W8A8 quantization settings on ImageNet (LDM-4). Code is available at: https://github.com/huanpengchu/QNCD.
- SliM-LLM: Salience-DrivenMixed-Precision Quantization for Large Language Models by The ETH Zürich, University of Hong Kong, and Beihang University (https://arxiv.org/pdf/2405.14917).The paper focuses on the problem of ultra-low bit weight quantization of LLMs. Specifically, it proposes the method relies on two novel techniques: (1)Salience-Determined Bit Allocation utilizes the clustering characteristics of salience distribution to allocate the bit-widths of each quantization group. This increases the accuracy of quantized LLMs and maintains the inference efficiency high; (2) Salience-Weighted Quantizer Calibration optimizes the parameters of the quantizer by considering the element-wise salience within the group. The method is evaluated in two setups for quantization parameters tuning: greedy search and gradient based search. Evaluation shows good results on Llama 1/2/3 models. Code is available at https://github.com/Aaronhuang-778/SliM-LLM.
- LCQ: Low-Rank Codebook based Quantization for Large Language Models by Nanjing University (https://arxiv.org/pdf/2405.20973). The paper proposes a method for LLM optimization using customized low-ranking codebooks the rank of which can be larger than one, for quantization. A gradient-based optimization algorithm is proposed to optimize the parameters of the codebook. The method also adopts a double quantization strategy for compressing the parameters of the codebook, which can reduce the storage cost of the codebook. Experiments show that achieves better accuracy than existing methods with a negligibly extra storage cost.
- P2 -ViT: Power-of-Two Post-Training Quantization and Acceleration for Fully Quantized Vision Transformer by Nanjing University and Sun Yat-sen University (https://arxiv.org/pdf/2405.19915). The paper introduces a Power-of-Two (PoT) post-training quantization and acceleration framework for ViT models. The authors analyze ViTs’ properties and develop a dedicated quantization scheme. This scheme incorporates techniques such as adaptive PoT rounding and PoT Aware smoothing, allowing for the efficient quantization of ViTs with PoT scaling factors. By doing this, computationally expensive floating-point multiplications and divisions with in the re-quantization process can be traded with hardware-efficient bitwise shift operations. Furthermore, we introduce a coarse-to-fine automatic mixed-precision quantization methodology for better accuracy-efficiency trade-offs. Finally, authors build a dedicated accelerator engine to better everage our algorithmic properties for enhancing hardware efficiency. Code is available at: https://github.com/shihuihong214/P2-ViT.
- QJL: 1-Bit Quantized JLTransform for KV Cache Quantization with Zero Overhead by New York University and Adobe Research (https://arxiv.org/pdf/2406.03482).The paper studies problems of KV-cache quantization of LLMs, specifically the Key part as it is more error-prone when lowering its precision. Authors propose an approach that consists of a Johnson-Lindenstrauss (JL) transform followed by sign-bit quantization for Key cache. They introduce an asymmetric estimator for the inner product of two vectors and demonstrate that applying the method to one vector and a standard JL transform without quantization to the other provides an unbiased estimator with minimal distortion. They also developed a CUDA-based implementation for optimized computation. When applied across various LLMs and NLP tasks to quantize the KV cache to only 3 bits, the method demonstrates a more than fivefold reduction in KV cache memory usage without an insignificant accuracy drop. Codes will be available at https://github.com/amirzandieh/QJL.
- ViDiT-Q: Efficient and Accurate Quantization of Diffusion Transformers for Image and Video Generation by Tsinghua University, Infinigence AI, 3Microsoft, and Shanghai Jiao Tong University (https://arxiv.org/pdf/2406.02540).The paper tackles the problems of accurate quantization of diffusion vision transformer models. Essentially, authors apply dynamic 8-bit per-token quantization to activations. They also propose to smooth activation with a Smoothquant-like approach but with different α factors tuned to each iteration of the diffusion process. Finally, authors propose to select a per-layer weight bit-width (e.g.W4A8, W6A6, or W8A8) depending on the sensitivity and position of the layer in the Transformer block. All these tricks lead to very good accuracy results in the image and video generation tasks.
- Instance-Aware Group Quantization for Vision Transformers by Yonsei University and Articron (https://arxiv.org/pdf/2404.00928). In this paper an approach for instance-aware group quantization for ViTs(IGQ-ViT) is introduced. According to the approach, channels of activation maps are dynamically split into multiple groups where each group has its own set of quantization parameters. Authors also extend their scheme to quantize softmax attentions across tokens. IGQ-ViT demonstrates superior accuracy results across image classification, object detection and instance segmentation task. Authors claim that performance overhead induced by dynamic quantization is no more than 4% compared to layer-wise quantization.
- Reg-PTQ: Regression-specialized Post-training Quantization for Fully Quantized Object Detector by Beihang University (https://openaccess.thecvf.com/content/CVPR2024/papers/Ding_Reg-PTQ_Regression-specialized_Post-training_Quantization_for_Fully_Quantized_Object_Detector_CVPR_2024_paper.pdf). In this paper authors explore full quantization of object detection models contrary to most existing approaches which quantize only detection backbones and keep detection head in original precision. Based on the findings, the reason behind poor quantization of detector heads is that they are optimized to solve regression tasks. Specifically, authors argue that (1) regressors are more sensitive to perturbation compared to classifiers, (2) minimizing quantization error does not necessarily result in optimal scaling factors for regressor and(3) regressors weights follow non-uniform distribution contrary to classifiers. To tackle these problems a novel Reg-PTQ method is introduced. Based on the results it achieves 7.6x and 5.4x reduction in computation and storage consumption under INT4 precision with little performance degradation.
- Towards Accurate Post-training Quantization for Diffusion Models (https://openaccess.thecvf.com/content/CVPR2024/papers/Wang_Towards_Accurate_Post-training_Quantization_for_Diffusion_Models_CVPR_2024_paper.pdf). In this paper authors propose a method for accurate post-training quantization of diffusion models. The main idea is to split diffusion timesteps for each layer into groups where each group corresponds to its own set of quantization parameters. Such split is obtained by minimizing some optimization objective on a calibration dataset. Besides this, a special timestep selection method is employed for sampling timesteps for calibration. Overall, the method demonstrates superior generation quality results over such baselines as LSQ, PTQ4DM and Q-Diffusion.
Pruning/Sparsity
- Effective Interplay between Sparsity and Quantization: From Theory to Practice by Google and EcoCloud (https://arxiv.org/pdf/2405.20935). Authors provide the theoretical analysis of how sparsity and quantization interact. Mathematical proofs establish that applying sparsity before quantization (S → Q) is the optimal sequence for compression. Authors demonstrate that sparsity and quantization are not orthogonal operations. Combining them introduces additional errors beyond the sum of their individual errors. They validate theoretical findings through experiments covering a diverse range of models, including prominent LLMs (OPT, LLaMA) and ViTs. The code will be published at: https://github.com/parsa-epfl/quantization-sparsity-interplay.
- Prompt-prompted Mixture of Experts for Efficient LLM Generation by CMU (https://arxiv.org/pdf/2404.01365). Authors introduce GRIFFIN, a training-free MoE that selects unique FF experts at the sequence level for efficient generation across a plethora of LLMs with different non-ReLU activation functions. This is possible due to a critical observation that many trained LLMs naturally produce highly structured FF activation patterns within a sequence, which we call flocking. Despite the method’s simplicity, it shows with 50% of the FF parameters, GRIFFIN maintains the original model’s performance with little to no degradation on a variety of classification and generation tasks, all while improving latency (e.g. 1.25× speed-up in Llama 213B on an NVIDIA L40). Code is available at https://github.com/hdong920/GRIFFIN.
- Sparse maximal update parameterization: A holistic approach to sparse training dynamics by Cerebras Systems (https://arxiv.org/pdf/2405.15743).This paper addresses the common issue in sparse training where hyper parameters from dense training are reused, leading to suboptimal convergence, and requiring extensive tuning for different sparsity ratios. The researchers introduce a novel sparse training methodology called Sparse Maximal Update Parameterization (SuPar), which extends the maximal update parameterization (uP)to sparse training. SuPar involves reparameterizing (see Table 1) weight initialization and learning rates relative to changes in sparsity, effectively preventing exploding or vanishing signals and maintaining stable activation, gradient, and weight update scales across varying sparsity levels and model widths. SuPar reparameterization is remarkable, it allows zero-shot hyperparameter transfer, i.e. practitioners can now tune small proxy models(dense/sparse) and transfer optimal HPs directly to models at scale for any model sparsity, thus enhancing the efficiency and reducing the cost of sparse model development. Experiments demonstrate that SμPar sets the Pareto frontier best loss across all sparsities and widths, including large dense model with width equal to GPT-3 XL.
- Sparse Expansion and Neuronal Disentanglement by MIT, IST Austria, Neural Magic (https://arxiv.org/pdf/2405.15756). Sparse Expansion is an approach of converting dense LLMs to mixture of sparse experts to attain inference efficiency. The method begins with applying dimensionality reduction (PCA) on the inputs of FFN linear layers, followed by a k-means clustering. The intuition is that tokens within a cluster share a sparse expert better without significant distortion. SparseGPT is then used to create a sparse expert for each cluster group. During inference, the PCA and k-means models act as routers, directing tokens to the appropriate sparse expert based on their cluster. While this increases the overall model size, acceleration is achieved through the conditional execution of experts and the sparse execution of these experts, with minimal cost for the routers. The paper includes layer-wise speedup benchmarks and shows that Sparse Expansion outperforms other one-shot sparsification approaches in perplexity for the same inference FLOP budget per token. A significant portion of the paper is dedicated to the concept of neuron entanglement, explaining, and quantifying the efficacy of sparse expansion.
- MULTIFLOW: Shifting Towards Task-Agnostic Vision-Language Pruning by University of Trento and Cisco Research (https://arxiv.org/pdf/2404.05621). Authors highlight that existing techniques for pruning of Visual-Language models(VLMs) are task-specific and propose a task-agnostic method for pruning VLMs. The proposed Multimodal Flow Pruning framework has the following properties: (1) the importance of a weight is computed based on saliency of the neurons it connects; and (2) parameters are pruned considering features of which modality they are used to compute allowing to avoid pruning too much from a single modality and too little from another. Experiments show that the proposed MULTIFLOW method outperforms recent more sophisticated competitors.
Other methods
- Flash Diffusion: Accelerating Any Conditional Diffusion Model for Few Steps Image Generation by Jasper Research (https://arxiv.org/pdf/2406.02347). The paper proposes a LoRA-compatible distillation method aiming at reducing the number of sampling steps required to generate high-quality samples from a trained diffusion model. Authors emphasize the versatility of the method through an extensive experimental study across various tasks (text-to-image, image inpainting, super-resolution, face-swapping), diffusion model architectures (SD1.5, SDXL and Pixart-α) and illustrate its compatibility with adapters. The method is relatively lightweight and can optimize SD1.5 model with 2 Nvidia H100 80GB with 13 hours of fine-tuning. Code is available at https://github.com/gojasper/flash-diffusion.
- GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection by California Institute of Technology, Meta AI, University of Texas at Austin, and Carnegie Mellon University (https://arxiv.org/pdf/2403.03507). The paper introduces a Gradient Low-Rank Projection (GaLore), a training strategy that allows full-parameter learning but is more memory-efficient than common low-rank adaptation methods such as LoRA. The idea is to use PCA after a number of training steps to obtain a gradient projection matrix and use it to get a low-rank gradient matrix that is used for weights update. The approach reduces memory usage by up to 65.5% in optimizer states while maintaining both efficiency and performance for pre-training. 8-bit GaLore further reduces optimizer memory by up to 82.5% and total training memory by 63.3%, compared to a BF16 baseline. It demonstrates the feasibility of pre-training a 7B model on consumer GPUs with 24GB memory. The code is available at: https://github.com/jiaweizzhao/GaLore.
- MiniCache: KV Cache Compression in Depth Dimension for Large Language Models by ZIP Lab of Monash and Zhejiang University (https://arxiv.org/pdf/2405.14366).The authors propose a training-free KV cache compression technique by merging KV tokens across every two consecutive transformer layers, based on the observation that KV tokens are highly similar across depth, especially from the middle to the last transformer layers. Specifically, a pair of K/V projections from two consecutive layers can be encoded into respective scaling factors and a shared directional vector computed via Spherical Linear Interpolation(SLERP). To address the information loss from merging dissimilar tokens, the algorithm uses angular-based distance to filter KV positions for retention. The algorithm is straightforward, involving calibration of only two hyperparameters, and it has demonstrated to enhance a 4X compressed KV cache by4-bit quantization to over 5X compression while retaining reasonable accuracy of instruction-tuned Mistral, LLama2-7B across benchmarks.
- Scalable MatMul-free Language Modeling by University of California, Soochow University, LuxiTech (https://arxiv.org/pdf/2406.02528). Authors develop a MatMul-free language model by using additive operations in dense layers and element-wise Hadamard products for self-attention-like functions. Specifically, ternary weights eliminate MatMul in dense layers, similar to BNNs. To remove MatMul from self-attention, they optimize the Gated Recurrent to rely solely on element-wise products and show that this model competes with state-of-the-art Transformers while eliminating all MatMul operations. To quantify the hardware benefits of lightweight models, the authors provide an optimized GPU implementation in addition to a custom FPGA accelerator. By using fused kernels in the GPU implementation of the ternary dense layers, training is accelerated by 25.6% and memory consumption is reduced by up to 61.0% over an unoptimized baseline on GPU. Furthermore, by employing lower-bit optimized CUDA kernels, inference speed is increased by 4.57 times, and memory usage is reduced by a factor of 10 when the model is scaled up to 13B parameters. The code is available at https://github.com/ridgerchu/matmulfreellm.
- Unlocking Efficiency in Large Language Model Inference: A Comprehensive Survey of Speculative Decoding by Hong Kong Polytechnic, Peking University, Microsoft Research Asia and Alibaba (https://arxiv.org/abs/2401.07851). While LLMs are proliferating over the past two years, Speculative Decoding (SD) has emerged as a crucial paradigm to accelerate autoregressive generation. This survey is among the first to provide a comprehensive introduction and overview of the state of the art in SD, highlighting key developments in this space. A main contribution of this work is the introduction of Spec-Bench, a unified benchmark for evaluating SD methods across standardized subtasks such as multi-turn conversation, summarization, RAG, translation, question answering, and mathematical reasoning. The codes and benchmarks for various SD methods on RTX 3090 and A100 GPUs are accessible for further exploration and validation.
- Speculative Decoding via Early-exiting for Faster LLM Inference with Thompson Sampling Control Mechanism by Meituan and Meta AI (https://arxiv.org/pdf/2406.03853).The paper introduces an early-exiting framework for generating draft tokens, which allows a single LLM to fulfill the drafting and verification stages. The model is trained using self-distillation. The authors conceptualize the generation length of draft tokens as a multi-armed bandit problem and propose a control mechanism based on Thompson Sampling, which leverages sampling to devise an optimal strategy. They conducted experiments on three benchmarks and showed that the method can significantly improve the model’s inference speed.
- LayerSkip: Enabling Early Exit Inference and Self-Speculative Decoding by Meta, University of Toronto, Carnegie Mellon University, University of Wisconsin-Madison, Dana-Farber Cancer Institute (https://arxiv.org/pdf/2404.16710).Authors research the idea of early exit in LLMs for speculative decoding. First, during training, they apply layer dropout, with low dropout rates for earlier layers and higher dropout rates for later layers, and an early exit loss where all transformer layers share the same exit. Second, during inference, they show that this training recipe increases the accuracy of early exit at earlier layers, without adding any auxiliary layers or modules to the model. Third, they present a self-speculative decoding solution where we exit at early layers and verify and correct with remaining layers of the model. They run experiments on different Llama model sizes on different types of training: pretraining from scratch, continual pretraining, finetuning on specific data domain, and finetuning on specific task, and show speedups of up to 2.16× on summarization for CNN/DM documents, 1.82× on coding, and 2.0× on TOPv2 semantic parsing task.
Software
- INT4 Decoding GQA CUDA Optimizations for LLM Inference by Meta(https://pytorch.org/blog/int4-decoding).The authors provide a comprehensive study and ten practical steps, including KV-cache quantization, to improve the performance of Grouped-query Attention. All these optimizations result in performance improvements of up to 1.8x on the NVIDIA A100 GPU and 1.9x on the NVIDIA H100 GPU.
- torchao: PyTorch Architecture Optimization by Meta (https://github.com/pytorch/ao). PyTorch library for quantization and sparsity. Currently-available features contain full models quantization, INT8, INT4, MXFP4,6,8 weight-only quantization and efficient model fine-tuning with GaLore method.
- Introducing Apple’s On-Device and Server Foundation Models by Apple (https://machinelearning.apple.com/research/introducing-apple-foundation-models). Apple has established a set of pre-trained and optimized models for its HW. The claim is that 3B LLM model can be run at 30t/s on iPhone 15 Pro. In terms of optimizations that are being used, authors claim weight palletization to 2 and 4 bits, quantization of embeddings and activations and efficient Key-Value (KV) cache update. They use their own AXLearn library built on top of JAX and XLA for model pre-training and fine-tuning.
- BitBLAS by Microsoft (https://github.com/microsoft/BitBLAS).A library to support mixed-precision BLAS operations on GPUs. BitBLAS aims to support efficient mixed-precision DNN model deployment, especially the quantization in large language models (LLMs), for example, the 𝑊4𝐴16 in GPTQ, the 𝑊2𝐴16 in BitDistiller, the 𝑊2𝐴8 in BitNet-b1.58.































