
.png)
Xiake
Sun
Joint Pruning, Quantization and Distillation for Efficient Inference of Transformers
Introduction
Pre-trained transformer models are widely deployed for various NLP tasks such as text classification, question answering, and generation task. The recent trend is that models continue to scale while yielding improved performance. However, growth of transformers also leads to great amount of compute resources and energy needed for deployment. The goal of model compression is to achieve model simplification from the original without significantly diminished accuracy. Pruning, quantization, and knowledge distillation are the three most popular model compression techniques for deep learning models. Pruning is a technique for reducing the size of a model to improve efficiency or performance. By reducing the number of bits needed to represent data, quantization can significantly reduce storage and computational requirements. Knowledge distillation involves training a small model to imitate the behavior of a larger model.
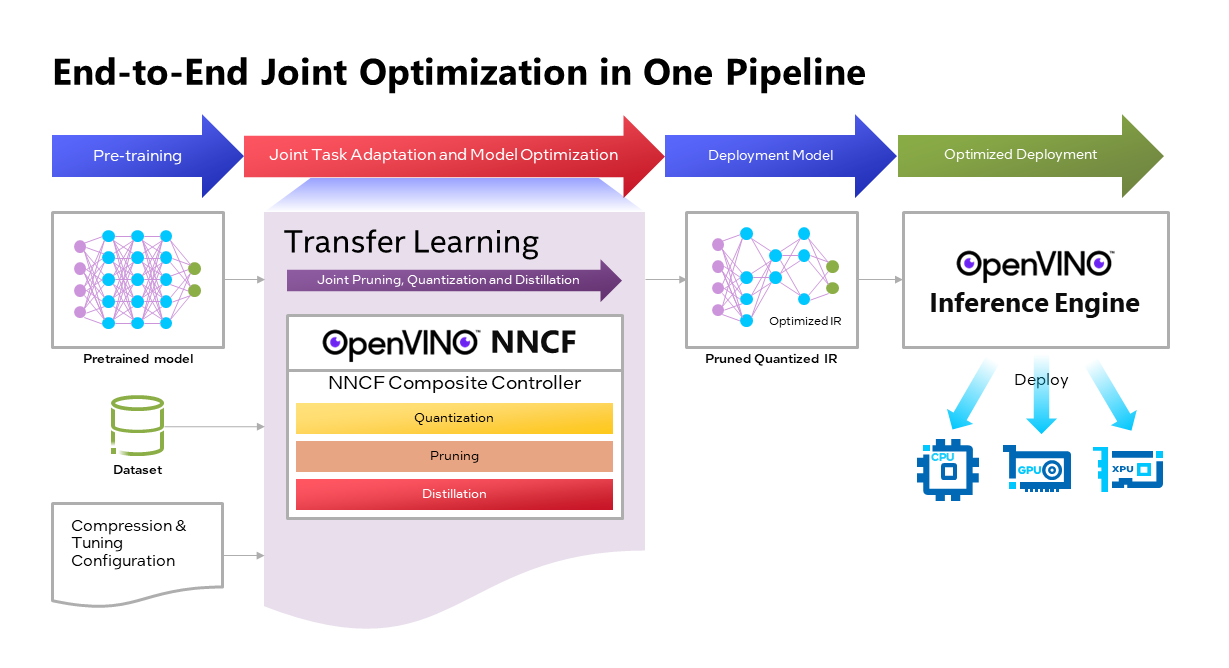
OpenVINOTM Neural Network Compression Framework (NNCF) develops Joint Pruning, Quantization and Distillation (JPQD) as a single joint-optimization pipeline to improve transformer inference performance by pruning, quantization, and distillation in parallel during transfer learning of a pretrained transformer. JPQD alleviates the developer complexity of sequential optimization of different compression techniques, resulting in an optimized model with significant efficiency improvement while preserving good task accuracy. The output of JPQD is a structurally pruned, quantized model in OpenVINOTM IR, which is ready to deploy with OpenVINOTM runtimes optimized on Intel platforms. Optimum intel provides simple API to integrate JPQD into training pipeline for Hugging Face Transformers.
JPQD of BERT-base Model with Optimum Intel
In this blog, we introduce how to apply JPQD to BERT-base model on GLUE benchmark for SST-2 text classification task.
Here is a compression config example with the format that follows NNCF specifications. We specify pruning and quantization in a list of compression algorithms with hyperparameters. The pruning method closely resembles the work of Movement Pruning (Sanh et al., 2020) and Block Pruning For Faster Transformers (Lagunas et al., 2021) for unstructured and structured movement sparsity. Quantization refers to Quantization-aware Training (QAT), see details for QAT in previous blog. At the beginning of training, the model under optimization will be initialized with pruning and quantization operators with this configuration.
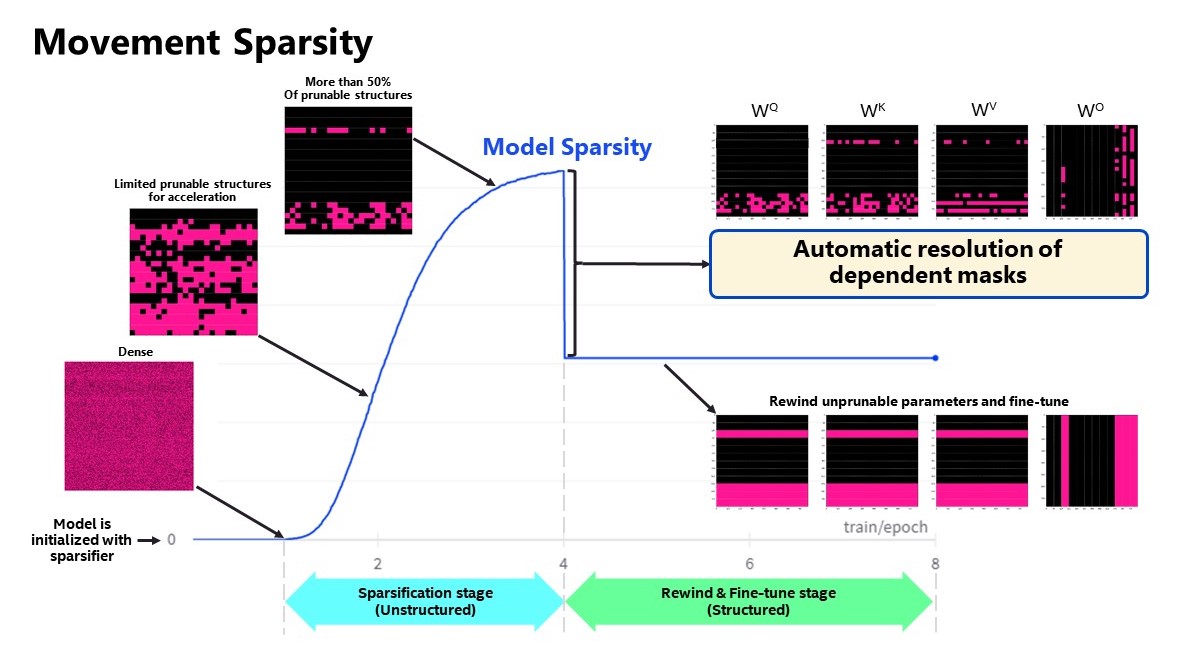
Figure 2 shows the sparsity level of BERT-base model over the optimization lifecycle, including two major stages:
- Unstructured sparsification: In the first stage, model weights are gradually sparsified in the grain size specified by "sparse_structure_by_scopes". The BertAttention layers (Multi-Head Attention: MHA) will be sparsified in 32x32 block size, while BertIntermediate, and BertOutput layers (Feed-Forward Network: FFN) will be sparsified in its row or column respectively. The first stage serves as a warmup stage defined by parameter “warmup_start_epoch” and “warmup_end_epoch”. The “importance_regularization_factor” defines regularization factor onweight importance scores. The factor stays zero before warmup stage, and gradually increases during warmup, finally stays at the fixed value after warmup, users might need some heuristics to find a satisfactory trade-off between sparsity and task accuracy.
- Structured masking and fine-tuning: The first warm-up stage will produce the unstructured sparsified model. Currently, unstructured sparsity optimized inference is only supported on 4th Gen Intel® Xeon® Scalable Processors with OpenVINO 2022.3 or a later version, for details, please refer to Accelerate Inference of Sparse Transformer Models with OpenVINO™ and 4th Gen Intel® Xeon®Scalable Processors. But it is possible to discard some sparse structure entirely from the model to save compute and memory footprint. NNCF provides a mechanism to achieve structured masking by “enable_structured_masking”: true, where it automatically resolves the structured masking between dependent layers and rewinds the sparsified parameters that do not participate in acceleration for task modeling. As Figure 2 shows, the sparsity level has dropped after “warmup_end_epoch” due to structured masking and the model will continue to be fine-tuned.
Known limitation: currently structured pruning with movement sparsity only supports BERT, Wav2vec2, and Swin family of models. See here for more information.
For distillation, the teacher model can be loaded with transformer API, e.g., a BERT-large pre-trained model from Hugging Face Hub. OVTrainingArguments extends transformers’ TrainingArguments with distillation hyperparameters, i.e., distillation weight and temperature for ease of use. The snippet below shows how we load a teacher model and create training arguments with OVTrainingArguments. Subsequently, the teacher model, with the instantiated OVConfig and OVTrainingArguments is fed to OVTrainer. The rest of the pipeline is identical to the native transformers' training, while internally the training is applied with pruning, quantization, and distillation.
Besides, NNCF provides JPQD examples of othertasks, e.g., question answering. Please refer to the examples provided here.
End-to-End JPQD of BERT-base Demo
Set up Python environment with necessary dependencies.
Run text classification example with JPQD of BERT on GLUE
All JPQD configurations and results are saved in ./jpqd-bert-base-ft-$TASK_NAME directory. Optimized OpenVINOTM IR is generated for efficient inference on intel platforms.
BERT-base Performance Evaluation and Accuracy Verification on Xeon

Table 1 shows BERT-base model for text classification task performance evaluation and accuracy verification results on 4th Gen Intel® Xeon® Scalable Processors. BERT-base FP32 model serves as the baseline. BERT-base INT8 (QAT) refers to the model optimized with the 8-bit quantization method only. BERT-base INT8 (JPQD) refers to the model optimized by pruning, quantization, and distillation method.
Here we use benchmark app with performance hint “throughput” to evaluate model performance with input sequence length=128.
As results shows, BERT-base INT8 (QAT) can already reach a 2.39x compression rate and 3.17x performance gain without significant accuracy drop (1.3%) on SST-2 compared with baseline. BERT-base INT8 (JPQD) can further increase compression rate to 5.24x to reach 4.19x performance improvement while keeping minimal accuracy drop (<1%) on SST-2 compared with baseline.

With proper fine-tuning, JPQD can even improve model accuracy while increasing performance in the meantime. Table 2 shows BERT-base model for question answering task performance evaluation and accuracy verification results on 4th Gen Intel® Xeon® Scalable Processors. BERT-base INT8 (JPQD) can increase compression rate to 5.15x to reach 4.25x performance improvement while improving Exact Match (1.35%) and F1 score (1.15%) metric on SQuAD compared with FP32 baseline.
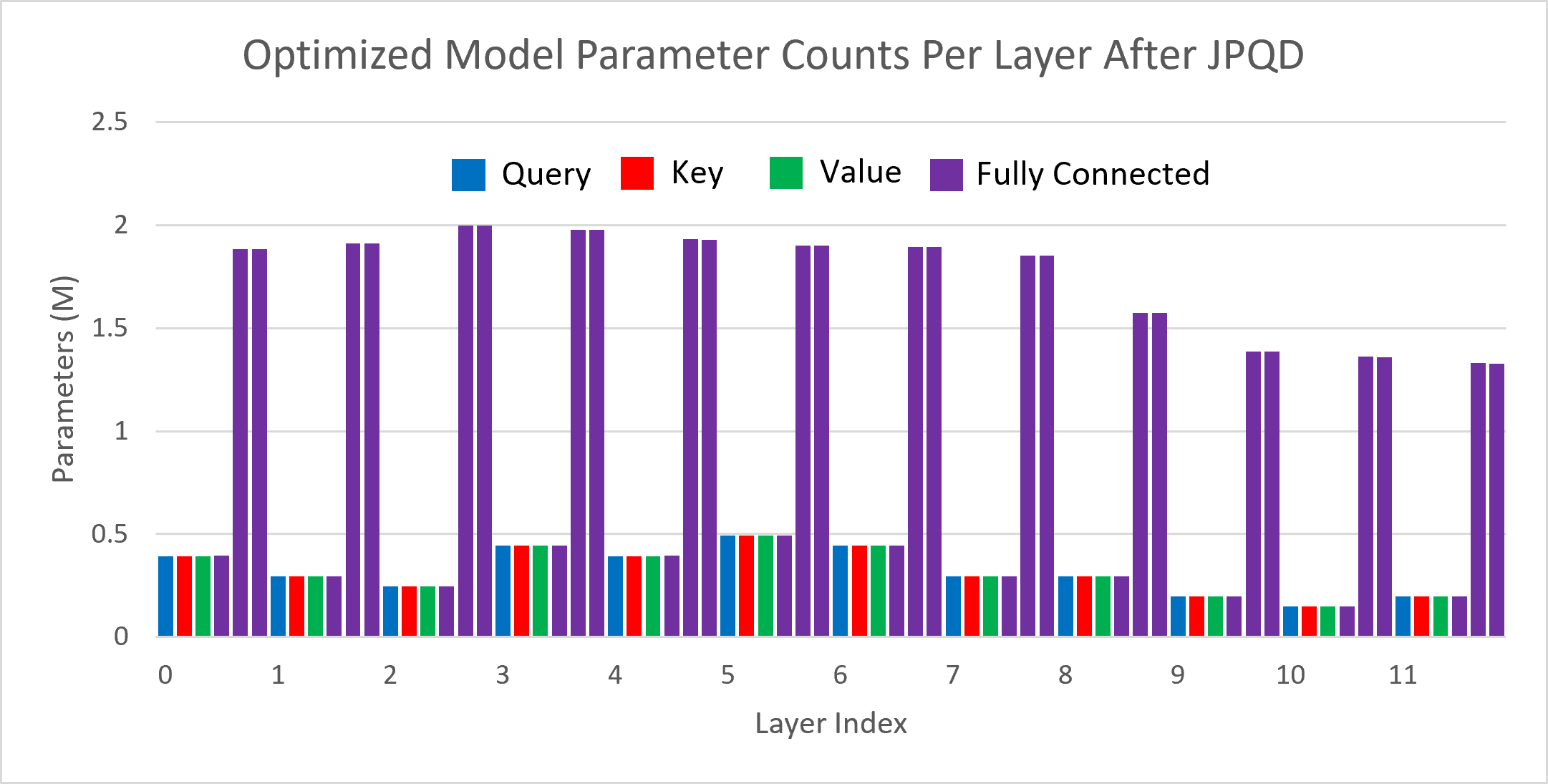
Figure 3 shows the visualization of parameter counts per layer in the BERT-base model optimized by JPQD for the text classification task. You can find that fully connected layers are actually “dense”, while most (Multi-Head Attention) MHA layers will be much sparser compared to the original model.
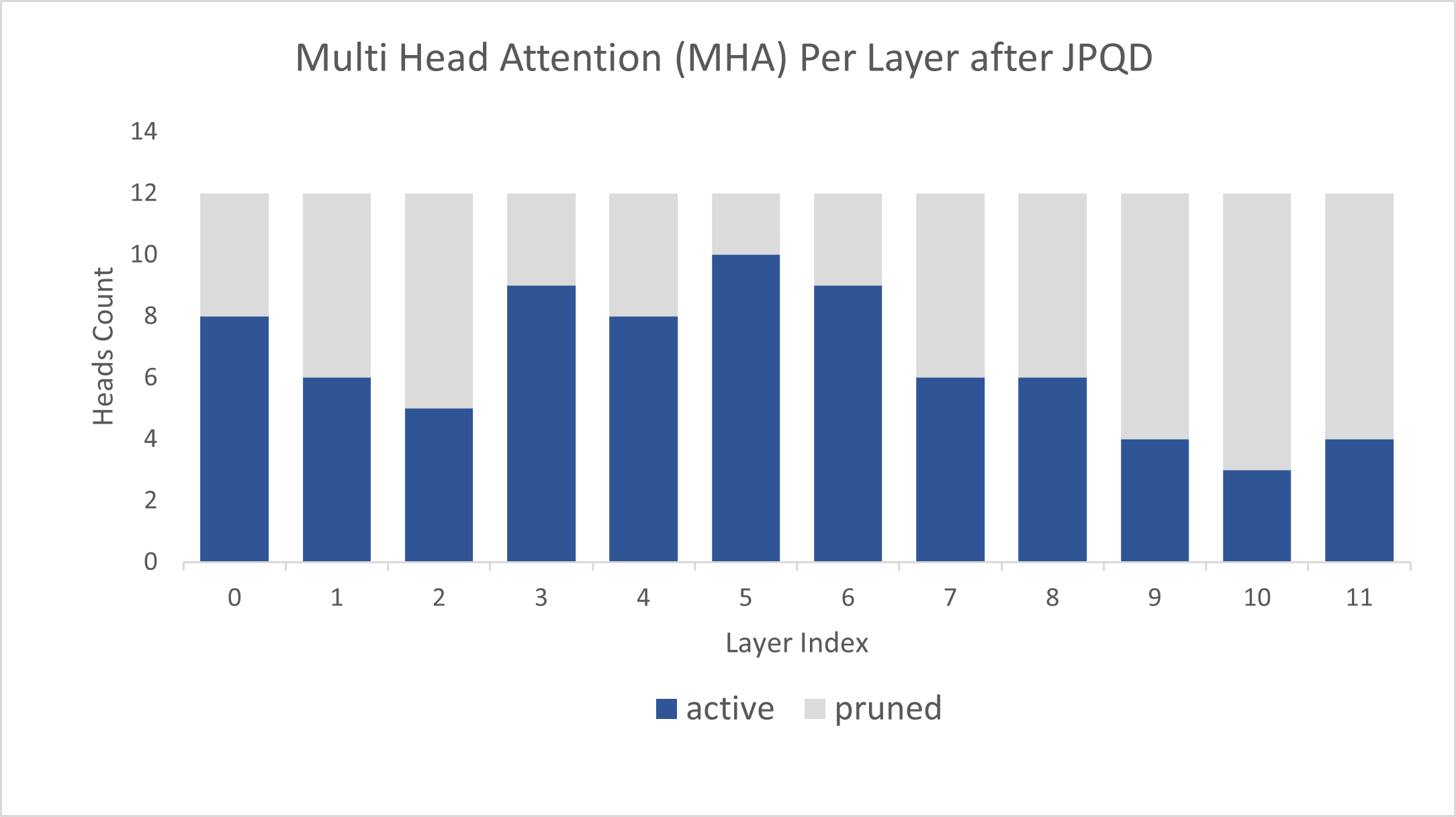
Figure 4 shows MHA head counts per layer in the BERT-base model optimized by JPQD for the text classification task, where active (blue) refer to remaining MHA head counts, while pruned (grey) refers to removed MHA head counts. Instead of pruning uniformly across all MHA heads in transformer layers, we observed that JPQD tends to preserve the weight to the lower layers while heavily pruning the highest layers, similar to experimental results from Movement Pruning (Sanh et al., 2020).
Conclusion
In this blog, we introduce a Joint Pruning, Quantization, and Distillation (JPQD) method to accelerate transformers inference on intel platforms. Here are three key takeaways:
- Optimum Intel provides simple API to integrate JPQD into training pipeline to enable pruning, quantization, and distillation in parallel during transfer learning of a pre-trained transformer. Optimized OpenVINOTM IR will be generated for efficient inference on intel architecture.
- BERT-base INT8 (JPQD) model for text classification task can reach 5.24x compression rate, leading to 4.19x performance improvement on 4th Gen Intel® Xeon® Scalable Processors while keeping minimal accuracy drop (<1%) on SST-2 compared with BERT-base FP32 models.
- BERT-base INT8 (JPQD) model for question answering task can reach 5.15x compression rate to achieve 4.25x performance improvement on 4th Gen Intel® Xeon® Scalable Processors while improving Exact Match (1.35%) and F1 score (1.15%) metric on SQuAD compared with BERT-base FP32 model.
Reference
- Hugging Face Optimum Intel
- Hugging Face Neural Networks Block Movement Pruning
- Intel®Xeon® Processors Are Still the Only CPU With MLPerf Results, Raising the Bar By5x
Additional Resources
Provide Feedback & Report Issues
Notices & Disclaimers
Intel technologies may require enabled hardware, software, or service activation.
No product or component can be absolutely secure.
Your costs and results may vary.
Intel does not control or audit third-party data. You should consult other sources to evaluate accuracy.
Intel disclaims all express and implied warranties, including without limitation, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement, as well as any warranty arising from course of performance, course of dealing, or usage in trade.
No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document.
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.































