Audio


Optimizing Whisper and Distil-Whisper for Speech Recognition with OpenVINO and NNCF
Authors: Nikita Savelyev, Alexander Kozlov, Ekaterina Aidova, Maxim Proshin
Introduction
Whisper is a general-purpose speech recognition model from OpenAI. The model can transcribe speech across dozens of languages and even handle poor audio quality or excessive background noise. You can find more information about this model in the research paper, OpenAI blog, model card and GitHub repository.
Recently, a distilled variant of the model called Distil-Whisper has been proposed in the paper Robust Knowledge Distillation via Large-Scale Pseudo Labelling. Compared to Whisper, Distil-Whisper runs several times faster with 50% fewer parameters, while performing to within 1% word error rate (WER) on out-of-distribution evaluation data.
Whisper is a Transformer-based encoder-decoder model, also referred to as a sequence-to-sequence model. It maps a sequence of audio spectrogram features to a sequence of text tokens. First, the raw audio inputs are converted to a log-Mel spectrogram by action of the feature extractor. Then, the Transformer encoder encodes the spectrogram to form a sequence of encoder hidden states. Finally, the decoder autoregressively predicts text tokens, conditional on both the previous tokens and the encoder's hidden states.
You can see the model architecture in the diagram below:

In this article, we would like to demonstrate how to improve Whisper and Distil-Whisper inference speed with OpenVINO for Intel hardware. Additionally, we show how to make models even faster by applying 8-bit Post-training Quantization with Neural Network Compression Framework (NNCF). In the end we present evaluation results from accuracy and performance standpoints on a large-scale dataset.
All code snippets presented in this article are from the Automatic speech recognition using Distil-Whisper and OpenVINO Jupyter notebook, so you can follow along.
Converting Model to OpenVINO format
We are going to load models from Hugging Face Hub with the help of Optimum Intel library which makes it easier to load and run OpenVINO-optimized models. For more details, pleaes refer to the Hugging Face Optimum documentation.
For example, the following code loads the Distil-Whisper large-v2 model ready for inference with OpenVINO.
Models from the Distil-Whisper family are available at Distil-Whisper Models collection and Whisper models are available at OpenAI Hugging Face page.
To transcribe an input audio with the loaded model, we first compile the model to the device of choice and then call generate() method on input features prepared by corresponding processor.
The output is the following. As you can see the transcription equals the reference text.
Running Post-Training Quantization with NNCF
NNCF enables post-training quantization by adding quantization layers into the model graph and then using a subset of the training dataset to initialize parameters of these additional quantization layers. During quantization, some layers (e.g., MatMuls, Convolutions) are transformed to be executed in INT8 instead of FP16/FP32. If a quantized operation is parameterized then its corresponding weight variable is also converted to INT8.
In general, the optimization process contains the following steps:
- Create a calibration dataset for quantization.
- Run nncf.quantize() to obtain quantized encoder and decoder models.
- Serialize the INT8 models using openvino.save_model() function.
Whisper model consists of an encoder and decoder submodels. Furthermore, for the decoder model its forward() signature is different for the first call compared to all subsequent calls. During the first call, key-value cache is empty and is not needed for decoder inference. Starting from the second call, key-value cache is fed to the decoder. Because of this, these two cases are represented by two separate OpenVINO models: openvino_decoder_model.xml and openvino_decoder_with_past_model.xml. Since the first decoder model is inferred only once it does not make much sense to quantize it. So, we apply quantization to the encoder and the decoder with past models.
The first step towards quantization is collecting calibration data. For that, we need to collect some number of model inputs for both models. To do that, we patch OpenVINO model request objects with an InferRequestWrapper class instance that will intercept model inputs during inference and store them in a list. We infer the model on about 50 samples from validation split of librispeech_asr dataset.
With the collected calibration data for encoder and decoder models we can proceed to quantization itself. Let's examine the quantization call for the encoder model. For the decoder model, it is similar.
After both models are quantized and saved, the quantized Whisper model can be loaded and run the same way as shown previously. Comparing the transcriptions produced by original and quantized models results in the following.
As you can see for the quantized distil-whisper-large-v2 transcription is the same.
Evaluating on Common Voice Dataset
We evaluate Whisper and Distil-Whisper large-v2 model variants on a Common Voice 13.0 speech-to-text dataset. We use en/test split containing 16372 audio samples amounting to about 27 hours of recordings.
The evaluation is done across three model types: original PyTorch model, original OpenVINO model and quantized OpenVINO model. Additionally, we run tests on three Intel CPUs: Cascade Lake Intel(R) Core(TM) i9-10980XE, Ice Lake Intel(R) Xeon(R) Gold 6338 and Sapphire Rapids Intel(R) Xeon(R) Gold 6430L.
For all combinations above we measure transcription time and accuracy. When measuring time for a model we sum up generate() call durations for all audio samples. Transcription accuracy is represented as Accuracy = (100 - WER), WER stands for Word Error Rate. We compute accuracy for each audio sample and then take the average value across the dataset. The results are given in the table below.
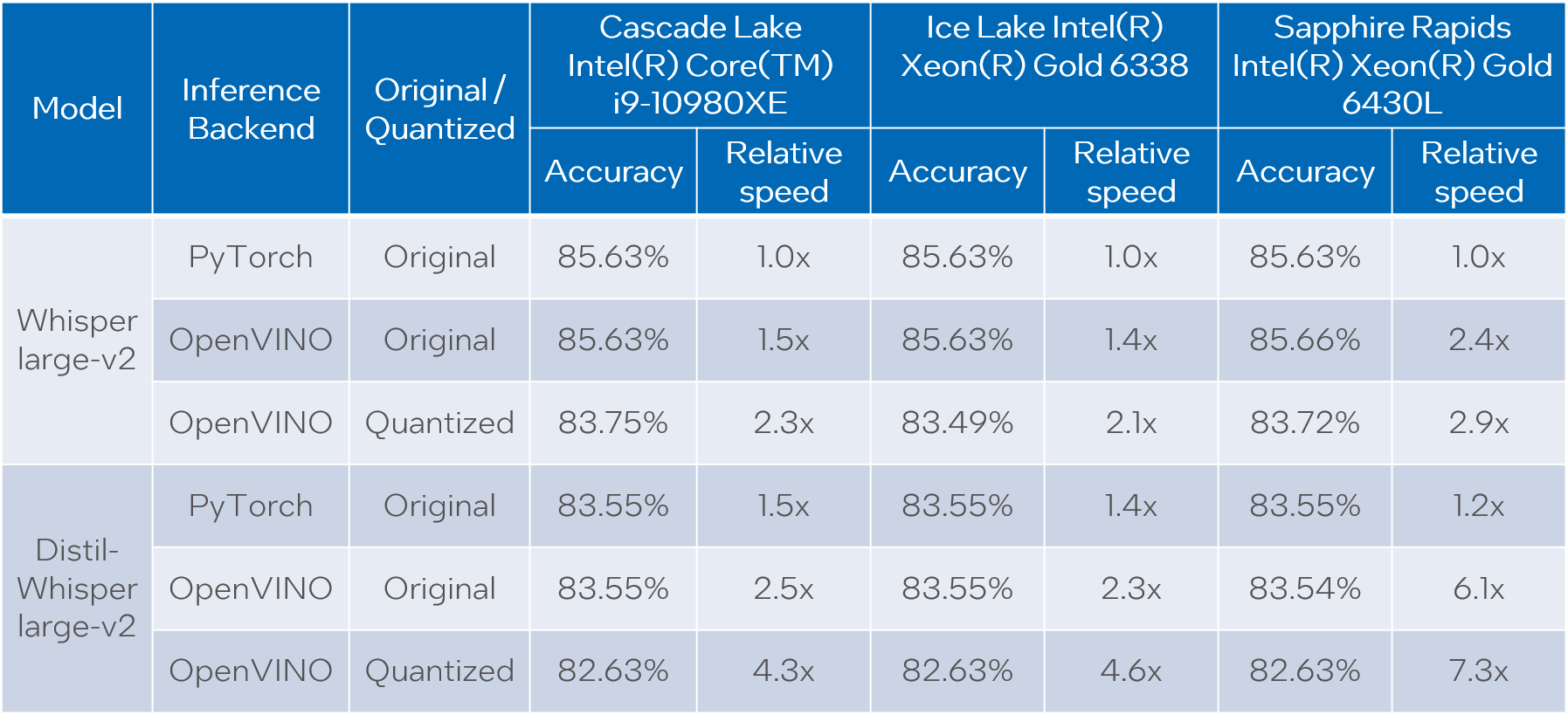
Please note that we report transcription time in relative terms such that the values for each CPU are normalized over its corresponding column. The duration of audio data in the dataset is 27.06 hours and the absolute transcription time values for Whisper large-v2 PyTorch on each CPU are:
- 20.35 hours for Core i9-10980XE
- 14.09 hours for Xeon Gold 6338
- 15.03 hours for Xeon Gold 6430L
Based on the results we can conclude that:
- OpenVINO models execute 1.4x - 5.1x faster than PyTorch models with pretty much the same accuracy across all cases.
- When compared to original PyTorch models, quantized OpenVINO models provide 2.1x - 6.1x performance boost with 1-2% accuracy drop.
NOTE: in terms of this article we focus on presenting performance values. Accuracy of quantized models can be improved with a more careful selection of calibration data.
Notices and Disclaimers:
Performance varies by use, configuration, and other factors. Learn more at www.intel.com/PerformanceIndex. Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. No product or component can be absolutely secure. Intel technologies may require enabled hardware, software or service activation.
The products described may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are available on request.
Test Configuration: Intel® Core™ i9-10980XE CPU Processor at 3.00GHz with DDR4 128 GB at 3000MHz, OS: Ubuntu 20.04.3 LTS; Intel® Xeon® Gold 6338 CPU Processor at 2.00GHz with DDR4 256 GB at 3200MHz, OS: Ubuntu 20.04.3 LTS; Intel® Xeon® Gold 6430L CPU Processor at 1.90GHz with DDR5 1024 GB at 4800MHz, OS: Ubuntu 20.04.6 LTS. Testing was performed using distil-whisper-asr notebook for model export and whisper evaluation notebook for model evaluation.
The test was conducted by Intel in December 2023.
Conclusion
We demonstrated how to load and run Whisper and Distil-Whisper models for audio transcription task with OpenVINO and Optimum Intel, and how to perform INT8 post-training quantization of these models with NNCF. Further we evaluated these models on a large scale speech-to-text dataset across multiple CPU devices. The evaluation results show a significant performance boost of OpenVINO vs PyTorch models without loss of transcription quality, and even a larger boost with a tolerable accuracy drop when we apply INT8 quantization.
OpenVINO™ optimize Fairseq S2T model
OpenVINO™ Optimize Fairseq S2T Model
Introduction
Fairseq is a sequence modeling toolkit that allows researchers and developers to train custom models for translation, summarization, language modeling and other text generation tasks.
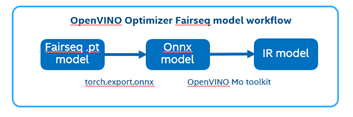
There are 2 steps to generate model ready for OpenVINO™ acceleration:
1. Use torch.export.onnx function convert the “.pt” model to “.onnx” model;
2. Use OpenVINO™ MO toolkit convert the “.onnx” model to “IR” model.
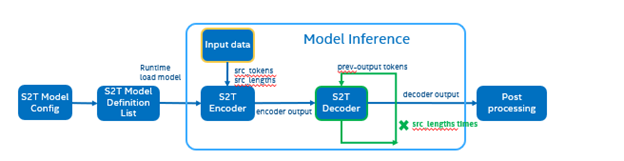
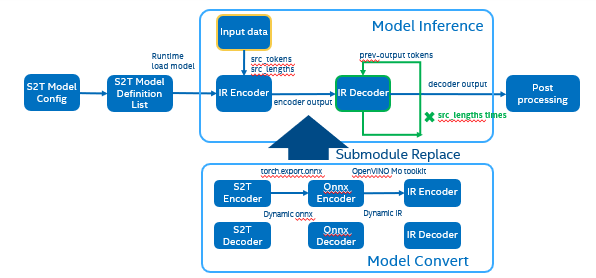
The following graph is the Fairseq framework inference workflow, it defines the model structure by “Model Config”, composes “Model Definition List” through multiple subgraph models, and dynamically loads the submodules in the model inference runtime.
Such as in the S2T task, model consists of two parts: Encoder and Decoder.
· Encoder is for extracting feature information from audio file.
· Decoder is for decoding the feature information to generate text information.
Fairseq Inference workflow
The length of audio information will affect the length of the feature information, and the length of the feature information will affect the Decoder submodule loop’s times. Therefore, the structure of the S2T model is dynamically defined according to the length of the input audio.
To optimize Fairseq framework model there’re 4 challenges need to be solved:
- Fairseq define submodules for various function, include variable in model layer define.
- Model structure is dynamically loaded in runtime and can’t export a whole torch model graph.
- Encoder and Decoder part models’ input shapes are dynamic, depending on input data size.
- Decoder part loop times depends by input sequence lengths.
OpenVINO™ optimize Fairseq workflow
So that we should use some optimization tricks to solve these problems, to make sure the pipeline optimized by OpenVINO™.
- Divide model into Encoder and Decoder two parts, and separately export to onnx model,
- Because of the model structure define by input seq_len, should export dynamic shape onnx model.
- Convert onnx to IR model by OpenVINO™ MO toolkit.
- Replace the Fairseq S2T task pipeline Encoder and Decoder into IR model.
- Loading Inference Engine to run pipeline the pipeline on OpenVINO™.
Requirement
- Fairseq is a sequence modeling toolkit that allows researchers and developers to train custom models for translation, summarization, language modeling and other text generation tasks
- OpenVINO™ is an open-source toolkit for optimizing and deploying AI inference which can boost deep learning performance in computer vision, automatic speech recognition, natural language processing and other common task.
- Python version >=3.8
- PyTorch version >=1.10.0
Reference: GitHub: Fairseq-OpenVINO
Quick Start Demo
Step 1. Install fairseq and requirement
#Install OpenVINO™
Reference: Install OpenVINO by source code for Linux
Reference: Install OpenVINO by release package
Step 2. Download audio file and pre-train model file
In this blog we refer the “S2T Example: STon CoVoST” as sample, Preparation dataset and pre-train model can follow the Fairseq original step. Also, you can use “torch audio” to convert audio file to build customer dataset.
Step 3. Modify code to export onnx
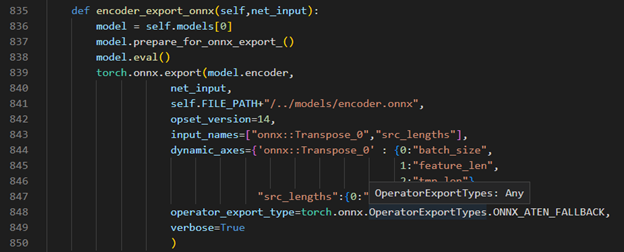
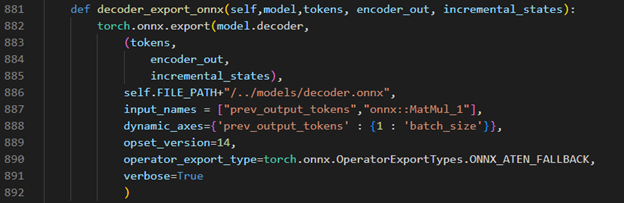
Torch model export to onnx, We should adjust the contents in fairseq/sequence_generator.py +781 line "self.save_onnx = True" , +782 line "self.openvino_engine = False" The encoder.onnx and decoder.onnx will save in models
Encoder part model export to dynamic onnx
Decoder part model export to dynamic onnx
Step 4. Convert Model to IR
Convert encoder.onnx and decoder.onnx to encoder.xml and decoder.xml
Step 5. OpenVINO™ Inference Engine optimize S2T pipeline
OpenVINO™ Inference S2T pipeline We should adjust the contents in fairseq/sequence_generator.py +781 line "self.save_onnx = False" , +782 line "self.openvino_engine =True" Use the converted the model to run OpenVINO™ Inference S2T pipeline.
OpenVINO™ Inference Engine initialization
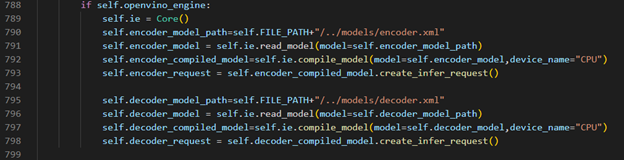
Encoder part inference by OpenVINO™

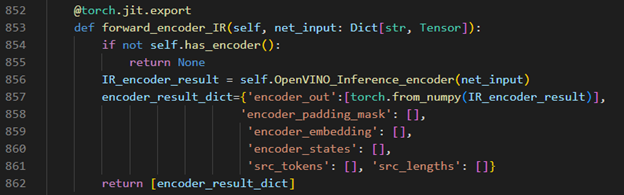
Decoder part inference by OpenVINO™

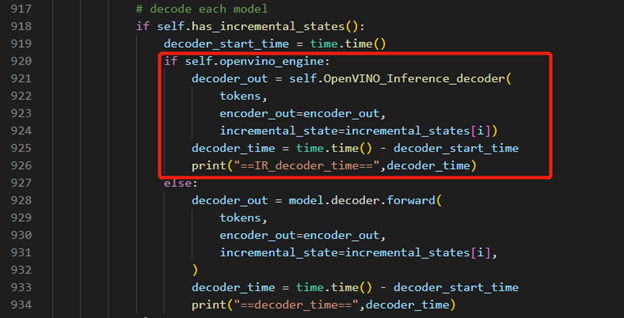
Inference Result