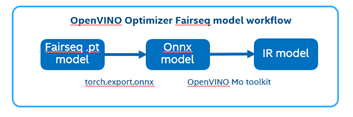
Fairseq is a sequence modeling toolkit that allows researchers and developers to train custom models for translation, summarization, language modeling and other text generation tasks.
There are 2 steps to generate model ready for OpenVINO™ acceleration:
1. Use torch.export.onnx function convert the “.pt” model to “.onnx” model;
2. Use OpenVINO™ MO toolkit convert the “.onnx” model to “IR” model.
Figure 1. OpenVINO™ optimize Fairseq model workflow
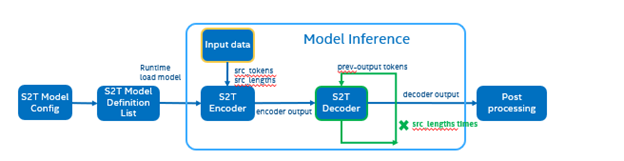
The following graph is the Fairseq framework inference workflow, it defines the model structure by “Model Config”, composes “Model Definition List” through multiple subgraph models, and dynamically loads the submodules in the model inference runtime.
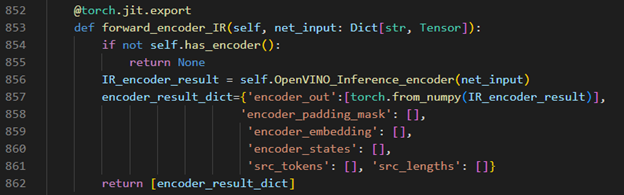
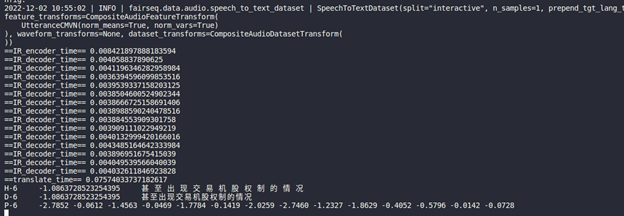
Such as in the S2T task, model consists of two parts: Encoder and Decoder. · Encoder is for extracting feature information from audio file. · Decoder is for decoding the feature information to generate text information.
Fairseq Inference workflow
The length of audio information will affect the length of the feature information, and the length of the feature information will affect the Decoder submodule loop’s times. Therefore, the structure of the S2T model is dynamically defined according to the length of the input audio.
Figure 2. Fairseq S2T model inference workflow
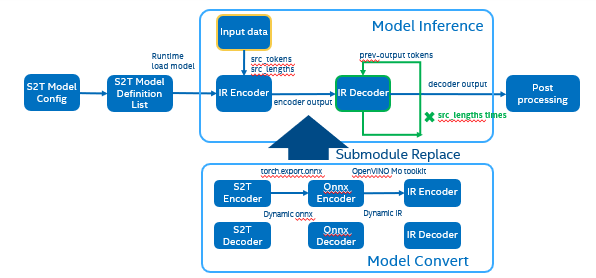
To optimize Fairseq framework model there’re 4 challenges need to be solved: - Fairseq define submodules for various function, include variable in model layer define. - Model structure is dynamically loaded in runtime and can’t export a whole torch model graph. - Encoder and Decoder part models’ input shapes are dynamic, depending on input data size. - Decoder part loop times depends by input sequence lengths.
OpenVINO™ optimize Fairseq workflow
So that we should use some optimization tricks to solve these problems, to make sure the pipeline optimized by OpenVINO™. - Divide model into Encoder and Decoder two parts, and separately export to onnx model, - Because of the model structure define by input seq_len, should export dynamic shape onnx model. - Convert onnx to IR model by OpenVINO™ MO toolkit. - Replace the Fairseq S2T task pipeline Encoder and Decoder into IR model. - Loading Inference Engine to run pipeline the pipeline on OpenVINO™.
Figure 3. OpenVINO™ optimize Fairseq S2T model workflow
Requirement
- Fairseq is a sequence modeling toolkit that allows researchers and developers to train custom models for translation, summarization, language modeling and other text generation tasks - OpenVINO™ is an open-source toolkit for optimizing and deploying AI inference which can boost deep learning performance in computer vision, automatic speech recognition, natural language processing and other common task. - Python version >=3.8 - PyTorch version >=1.10.0 Reference: GitHub: Fairseq-OpenVINO
Step 2. Download audio file and pre-train model file
In this blog we refer the “S2T Example: STon CoVoST” as sample, Preparation dataset and pre-train model can follow the Fairseq original step. Also, you can use “torch audio” to convert audio file to build customer dataset.
import torchaudio
# load tensor from file
waveform, sample_rate = torchaudio.load('foo.arm')
# save tensor to file
torchaudio.save('foo_save.wav', waveform, sample_rate)
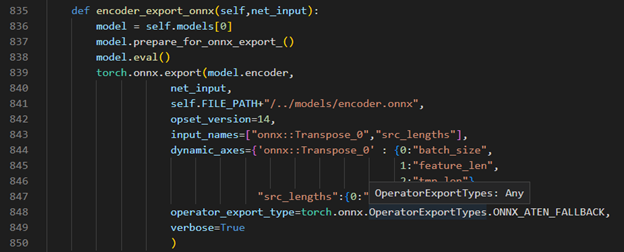
Step 3. Modify code to export onnx
Torch model export to onnx, We should adjust the contents in fairseq/sequence_generator.py +781 line "self.save_onnx = True" , +782 line "self.openvino_engine = False" The encoder.onnx and decoder.onnx will save in models
Figure 4. Encoder part model export to dynamic onnx
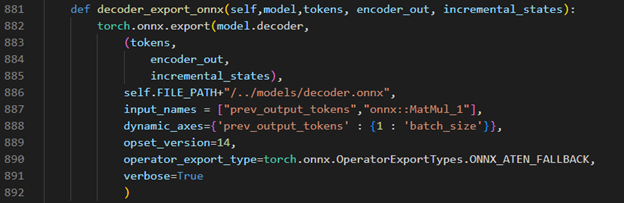
Decoder part model export to dynamic onnx
Figure 5. Decoder part model export to dynamic onnx
Step 4. Convert Model to IR
Convert encoder.onnx and decoder.onnx to encoder.xml and decoder.xml
# Convert encoder onnx to IR
mo -m encoder.onnx --input "onnx::Transpose_0[-1,-1,-1],src_lengths[-1]"
# Convert decoder onnx to IR
mo -m decoder.onnx --input "prev_output_tokens[-1,-1],onnx::MatMul_1[-1,-1,-1]"
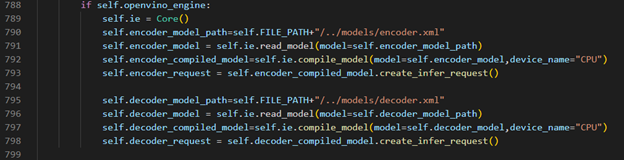
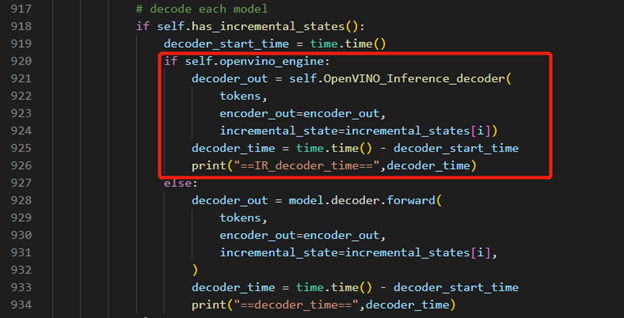
OpenVINO™ Inference S2T pipeline We should adjust the contents in fairseq/sequence_generator.py +781 line "self.save_onnx = False" , +782 line "self.openvino_engine =True" Use the converted the model to run OpenVINO™ Inference S2T pipeline.
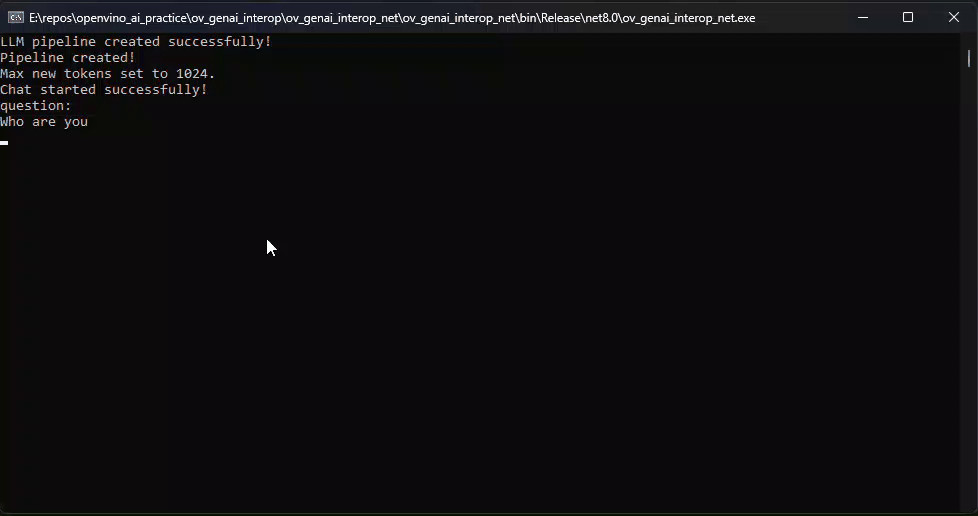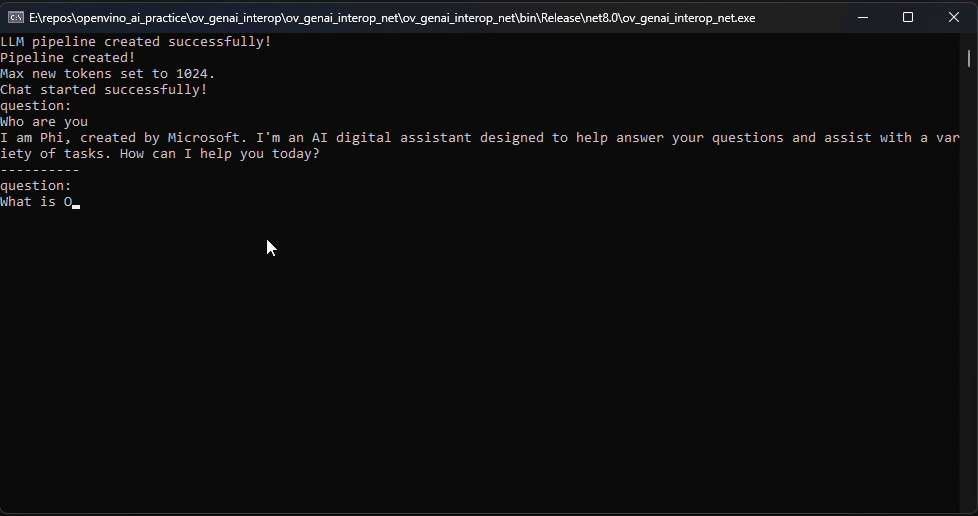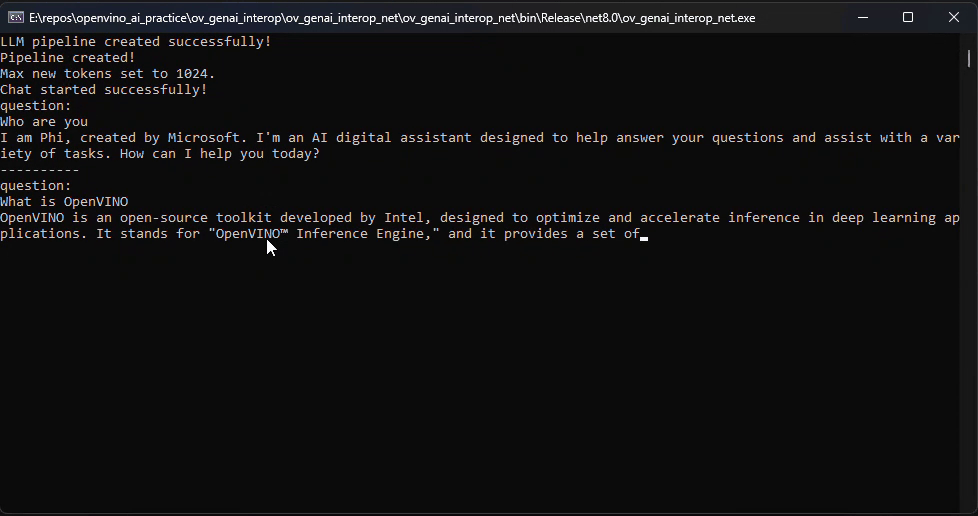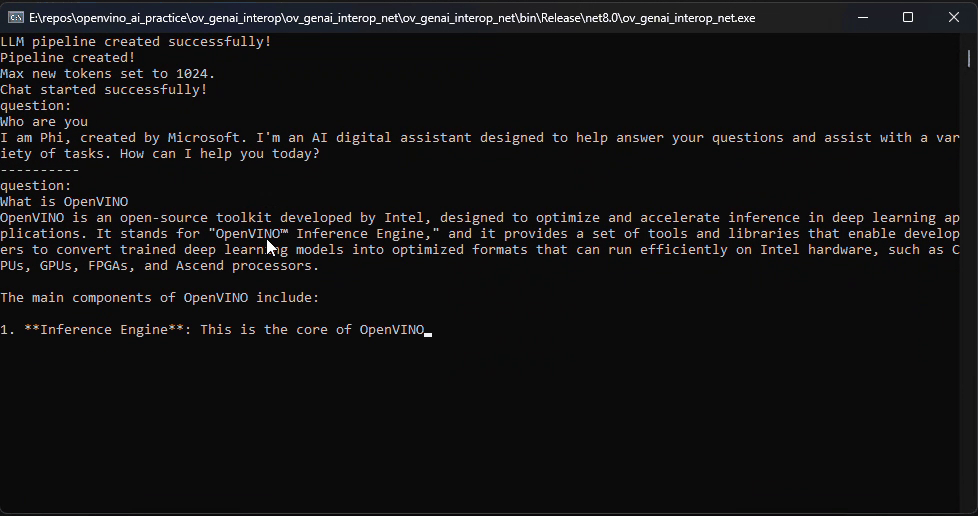
Starting with OpenVINO.GenAI 2025.1, the C API has been introduced, primarily to enhance interoperability with other programming languages, enabling developers to more effectively utilize OpenVINO-based generative AI across diverse coding environments.
Compared to C++, C's ABI is more stable, often serving as an interface layer or bridge language for cross-language interoperability and integration. This allows developers to leverage the performance benefits of C++ in the backend while using other high-level languages for easier implementation and integration.
As a milestone, we have currently delivered only the LLMPipeline and its associated C API interface. If you have other requirements or encounter any issues during usage, please submit an issue to OpenVINO.GenAI
Currently, we have implemented a Go application Ollama using the C API (Please refer to https://blog.openvino.ai/blog-posts/ollama-integrated-with-openvino-accelerating-deepseek-inference), which includes more comprehensive features such as performance benchmarking for developers reference.
Now, let's dive into the design logic of the C API, using a .NET C# example as a case study, based on the Windows platform with .NET 8.0.
Live Demo
Before we dive into the details, let's take a look at the final C# version of the ChatSample, which supports multi-turn conversations. Below is a live demo
How to Build a Chat Sample by C#
P/Invoke: Wrapping Unmanaged Code in .NET
First, the official GenAI C API can be found in this folder https://github.com/openvinotoolkit/openvino.genai/tree/master/src/c/include/openvino/genai/c . We also provide several pure C samples https://github.com/openvinotoolkit/openvino.genai/tree/master/samples/c/text_generation . Now, we will build our own C# Chat Sample based on the chat_sample_c. This sample can facilitate multi-turn conversations with the LLM.
C# can access structures, functions and callbacks in the unmanaged library openvino_genai_c.dll through P/Invoke. This example demonstrates how to invoke unmanaged functions from managed code.
The dynamic library openvino_genai_c.dll is imported, which relies on openvino_genai.dll. CallingConvention = CallingConvention.Cdecl here corresponds to the default calling convention _cdecl in C, which defines the argument-passing order, stack-maintenance responsibility, and name-decoration convention. For more details, refer to Argument Passing and Naming Conventions.
Additionally, the return value ov_status_e reuses an enum type from openvino_c.dll to indicate the execution status of the function. We need to implement a corresponding enum type in C#, such as
Next, we will implement our C# LLMPipeline, which inherits the IDisposable interface. This means that its instances require cleanup after use to release the unmanaged resources they occupy. In practice, object allocation and deallocation for native pointers are handled through the C interface provided by OpenVINO.GenAI. The OpenVINO.GenAI library takes full responsibility for memory management, which ensures memory safety and eliminates the risk of manual memory errors.
publicclassLlmPipeline : IDisposable
{
private IntPtr _nativePtr;
publicLlmPipeline(string modelPath, string device){
var status = NativeMethods.ov_genai_llm_pipeline_create(modelPath, device, out _nativePtr);
if (_nativePtr == IntPtr.Zero || status != ov_status_e.OK)
{
Console.WriteLine($"Error: {status} when creating LLM pipeline.");
thrownew Exception("Failed to create LLM pipeline.");
}
Console.WriteLine("LLM pipeline created successfully!");
}
publicvoidDispose(){
if (_nativePtr != IntPtr.Zero)
{
NativeMethods.ov_genai_llm_pipeline_free(_nativePtr);
_nativePtr = IntPtr.Zero;
}
GC.SuppressFinalize(this);
}
// Other Methods}
Callback Implementation
Next, let's implement the most complex method of the LLMPipeline, the GenerateStream method. This method encapsulates the LLM inference process. Let's take a look at the original C code. The result can be retrieved either via ov_genai_decoded_results or streamer_callback. ov_genai_decoded_results provides the inference result all at once, while streamer_callback allows for streaming inference results. ov_genai_decoded_results or streamer_callback must be non-NULL; neither can be NULL at the same time. For more information please refer to the comments https://github.com/openvinotoolkit/openvino.genai/blob/master/src/c/include/openvino/genai/c/llm_pipeline.h
// code snippets from //https://github.com/openvinotoolkit/openvino.genai/blob/master/src/c/include/openvino/genai/c/llm_// pipeline.h typedefenum { OV_GENAI_STREAMMING_STATUS_RUNNING = 0, // Continue to run inference OV_GENAI_STREAMMING_STATUS_STOP =
1, // Stop generation, keep history as is, KV cache includes last request and generated tokens OV_GENAI_STREAMMING_STATUS_CANCEL = 2// Stop generate, drop last prompt and all generated tokens from history, KV// cache includes history but last step} ov_genai_streamming_status_e;
// ...typedefstruct { ov_genai_streamming_status_e(
OPENVINO_C_API_CALLBACK* callback_func)(constchar* str, void* args); //!< Pointer to the callback functionvoid* args; //!< Pointer to the arguments passed to the callback function} streamer_callback;
// ...OPENVINO_GENAI_C_EXPORTS ov_status_e ov_genai_llm_pipeline_generate(ov_genai_llm_pipeline* pipe,
constchar* inputs,
const ov_genai_generation_config* config,
const streamer_callback* streamer,
ov_genai_decoded_results** results);
The streamer_callback structure includes not only the callback function itself, but also an additional void* args for enhanced flexibility. This design allows developers to pass custom context or state information to the callback.
For example, in C++ it's common to pass a this pointer through args, enabling the callback function to access class members or methods when invoked.
// args is a this pointervoidcallback_func(constchar* str, void* args){
MyClass* self = static_cast<MyClass*>(args);
self->DoSomething();
}
This C# code defines a class StreamerCallback that helps connect a C callback function with a C# method. It wraps a C function pointer MyCallbackDelegate and a void* args into a struct.
- ToNativePTR method constructs the streamer_callback structure, allocates a block of memory, and copies the structure's data into it, allowing it to be passed to a native C function.
- GCHandle is used to safely pin the C# object so that it can be passed as a native pointer to unmanaged C code.
- CallbackWrapper method is the actual function that C code will call.
[UnmanagedFunctionPointer(CallingConvention.Cdecl)]
public delegate ov_genai_streamming_status_e MyCallbackDelegate(IntPtr str, IntPtr args);
[StructLayout(LayoutKind.Sequential)]
publicstructstreamer_callback{public MyCallbackDelegate callback_func;
public IntPtr args;
}
publicclassStreamerCallback : IDisposable
{
public Action<string> OnStream;
public MyCallbackDelegate Delegate;
private GCHandle _selfHandle;
publicStreamerCallback(Action<string> onStream){
OnStream = onStream;
Delegate = new MyCallbackDelegate(CallbackWrapper);
_selfHandle = GCHandle.Alloc(this);
}
public IntPtr ToNativePtr(){
var native = new streamer_callback
{
callback_func = Delegate,
args = GCHandle.ToIntPtr(_selfHandle)
};
IntPtr ptr = Marshal.AllocHGlobal(Marshal.SizeOf<streamer_callback>());
Marshal.StructureToPtr(native, ptr, false);
return ptr;
}
publicvoidDispose(){
if (_selfHandle.IsAllocated)
_selfHandle.Free();
}
private ov_genai_streamming_status_e CallbackWrapper(IntPtr str, IntPtr args){
string content = Marshal.PtrToStringAnsi(str) ?? string.Empty;
if (args != IntPtr.Zero)
{
var handle = GCHandle.FromIntPtr(args);
if (handle.Target is StreamerCallback self)
{
self.OnStream?.Invoke(content);
}
}
return ov_genai_streamming_status_e.OV_GENAI_STREAMMING_STATUS_RUNNING;
}
}
Then We implemented the GenerateStream method in class LLMPipeline.
publicvoidGenerateStream(string input, GenerationConfig config, StreamerCallback? callback = null){
IntPtr configPtr = config.GetNativePointer();
IntPtr decodedPtr;// placeholder IntPtr streamerPtr = IntPtr.Zero;
if (callback != null)
{
streamerPtr = callback.ToNativePtr();
}
var status = NativeMethods.ov_genai_llm_pipeline_generate(
_nativePtr,
input,
configPtr,
streamerPtr,
out decodedPtr
);
if (streamerPtr != IntPtr.Zero)
Marshal.FreeHGlobal(streamerPtr);
callback?.Dispose();
if (status != ov_status_e.OK)
{
Console.WriteLine($"Error: {status} during generation.");
thrownew Exception("Failed to generate results.");
}
return;
}
We use the following code to invoke our callback and GenerateStream.
pipeline.StartChat(); // Start chat with keeping history in kv cache.Console.WriteLine("question:");
while (true)
{
string? input = Console.ReadLine();
if (string.IsNullOrWhiteSpace(input)) break;
using var streamerCallback = new StreamerCallback((string chunk) =>
{
Console.Write(chunk);
});
pipeline.GenerateStream(input, generationConfig, streamerCallback);
input = null;
Console.WriteLine("\n----------\nquestion:");
}
pipeline.FinishChat(); // Finish chat and clear history in kv cache.
About Deployment
We can directly download the OpenVINO official release of the LLM's IR from Hugging Face using this link.
The OpenVINO.GenAI 2025.1 package can be downloaded via this link.
The C# project directly depends on openvino_genai_c.dll, which in turn has transitive dependencies on other toolkit-related DLLs, including Intel TBB libraries.
To ensure proper runtime behavior, all the DLLs delivered with OpenVINO.GenAI — including openvino_genai_c.dll and its dependencies — are bundled and treated as part of the C# project’s runtime dependencies.
We use the following cmd commands to download the genai package and copy all the required dependent DLLs to the directory containing the *.csproj file.
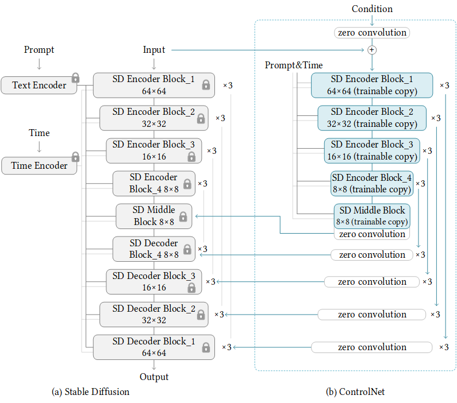
Stable Diffusion is a generative artificial intelligence model that produces unique images from text and image prompts. ControlNet is a neural network that controls image generation in Stable Diffusion by adding extra conditions. The specific structure of Stable Diffusion + ControlNet is shown below:
In many cases, ControlNet is used in conjunction with other models or frameworks, such as OpenPose, Canny, Line Art, Depth, etc. An example of Stable Diffusion + ControlNet + OpenPose:
OpenPose identifies the key points of the human body from the left image to get the pose image, and then inputs the Pose image to ControlNet and Stable Diffusion to get the right image. In this way, ControlNet can control the generation of Stable Diffusion.
In this blog, we focus on enabling the stable diffusion pipeline with ControlNet in Optimum-intel. Some details can be found in this open PR.
How to enable StableDiffusionControlNet pipeline in Optimum-Intel
The important code is in optimum/intel/openvino/modelling_diffusion.py and optimum/exporters/openvino/model_configs.py. There is the diffusion pipeline related code in file modelling_diffusion.py, you can find several Class: OVStableDiffusionPipelineBase, OVStableDiffusionPipeline, OVStableDiffusionXLPipelineBase, OVStableDiffusionXLPipeline, and so on. What we need to do is mimic these base classes to add the OVStableDiffusionControlNetPipelineBase, StableDiffusionContrlNetPipelineMixin, and OVStableDiffusionControlNetPipeline. A few of the important parts are as follows:
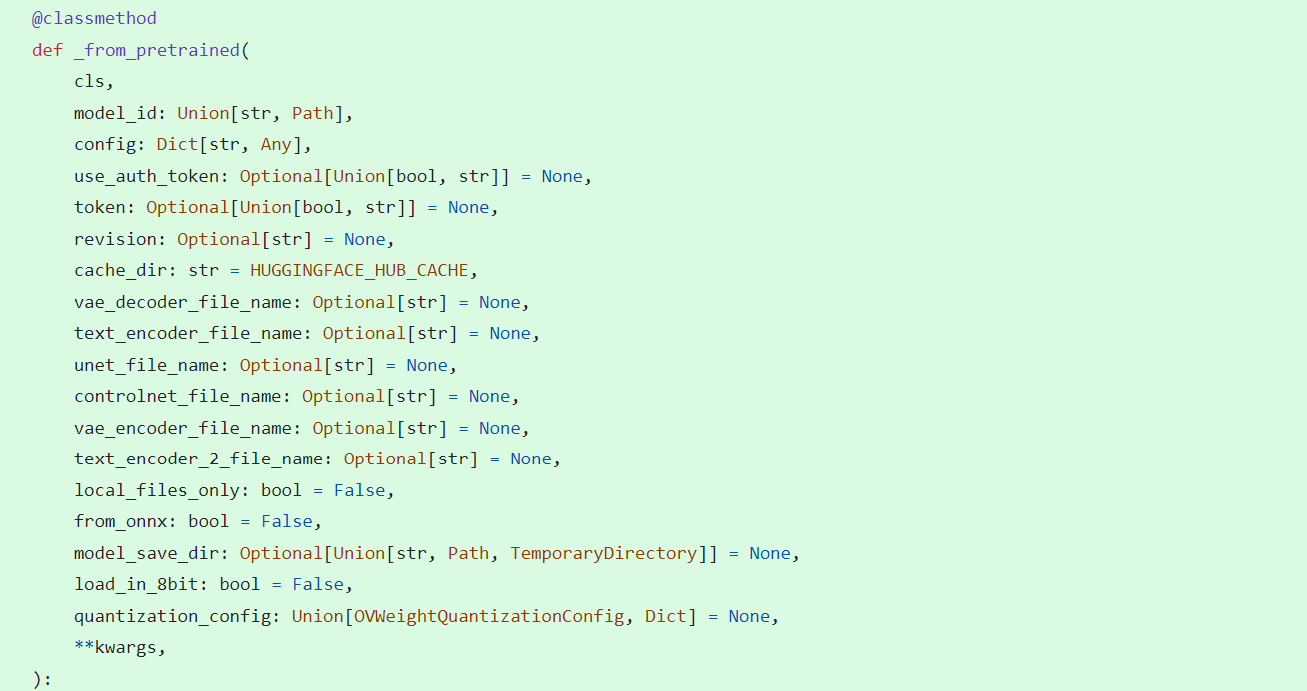
_from_pretrained function in class OVStableDiffusionControlNetPipelineBase: initial whole pipeline from local or download.
_from_transformers function in class OVStableDiffusionControlNetPipelineBase: convert torch model to OpenVINO IR model.
_reshape_unet_controlnet and _reshape_controlnet in class OVStableDiffusionControlNetPipelineBase: reshape dynamic OpenVINO IR model to static in order to decrease cost.
__call__ function in class StableDiffusionContrlNetPipelineMixin: do the inference in the pipeline.
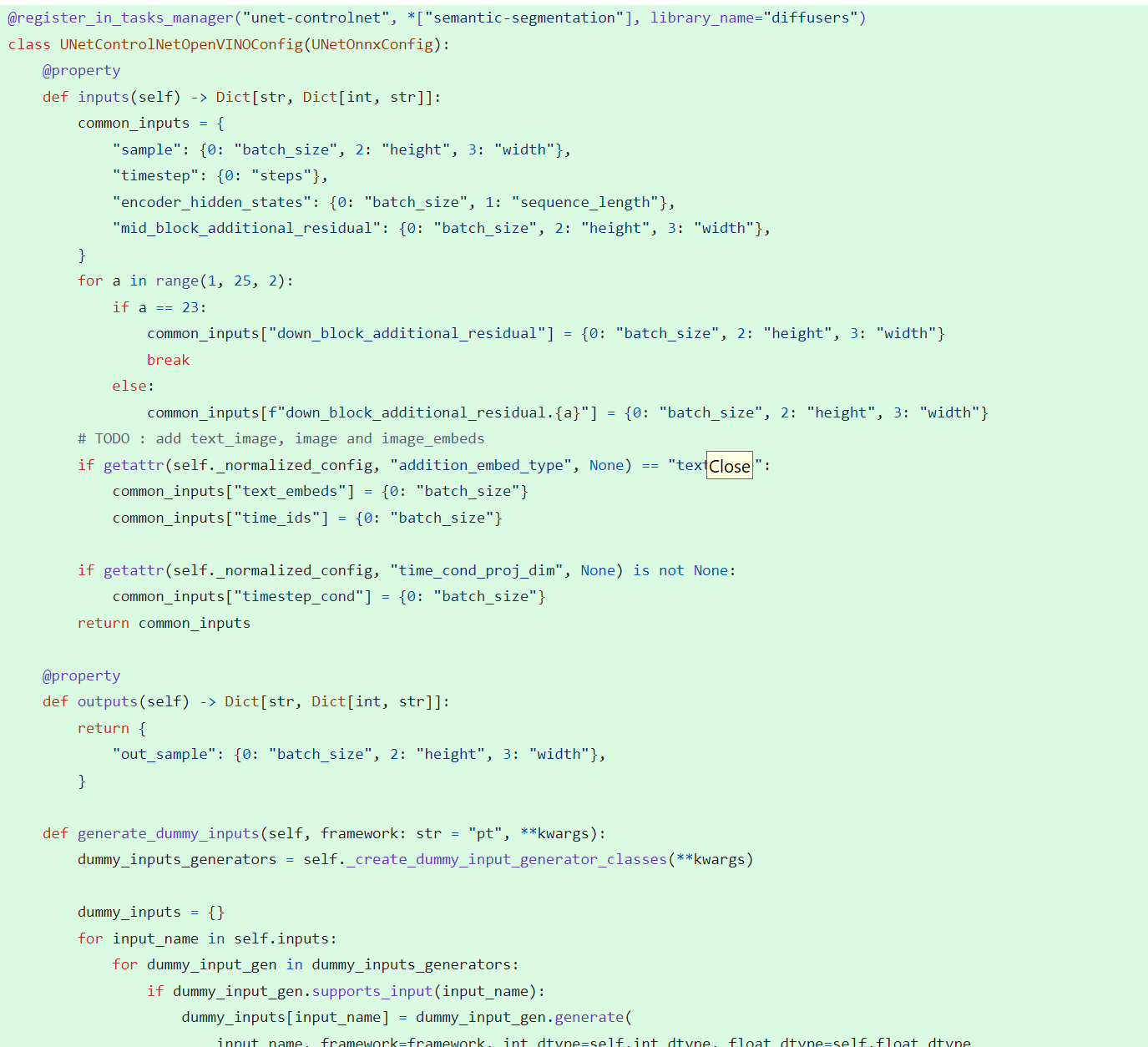
In model_configs.py, we define UNetControlNetOpenVINOConfig by inheriting UNetOnnxConfig, which includes UNetControlNet inputs and outputs.
By now we have completed the rough code, after which some very detailed code additions are needed, so I won't go into that here.
How to use StableDiffusionControlNet pipeline via Optimum-Intel
The next step is how to use the code, examples of which can be found in this repository.
Installation and update of environments and dependencies from source. Make sure your python version is greater that 3.10 and your optimum-intel and optimum version is up to date accounding to the requirements.txt.
At first, we should convert pytorch model to openvino IR with dynamic shape. Now import related packages.
from optimum.intel import OVStableDiffusionControlNetPipeline
import os
from diffusers import UniPCMultistepScheduler
Set pytroch models of stable diffusion 1.5 and controlnet path if you have them in local, else you can run pipeline from download.
SD15_PYTORCH_MODEL_DIR="stable-diffusion-v1-5"CONTROLNET_PYTORCH_MODEL_DIR="control_v11p_sd15_openpose"if os.path.exists(SD15_PYTORCH_MODEL_DIR) and os.path.exists(CONTROLNET_PYTORCH_MODEL_DIR):
scheduler = UniPCMultistepScheduler.from_config("scheduler_config.json")
ov_pipe = OVStableDiffusionControlNetPipeline.from_pretrained(SD15_PYTORCH_MODEL_DIR, controlnet_model_id=CONTROLNET_PYTORCH_MODEL_DIR, compile=False, export=True, scheduler=scheduler,device="GPU.1")
ov_pipe.save_pretrained(save_directory="./ov_models_dynamic")
print("Dynamic model is saved in ./ov_models_dynamic")
else:
scheduler = UniPCMultistepScheduler.from_config("scheduler_config.json")
ov_pipe = OVStableDiffusionControlNetPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", controlnet_model_id="lllyasviel/control_v11p_sd15_openpose", compile=False, export=True, scheduler=scheduler, device="GPU.1")
ov_pipe.save_pretrained(save_directory="./ov_models_dynamic")
print("Dynamic model is saved in ./ov_models_dynamic")
Now you will have openvino IR models file under **ov_models_dynamic ** folder.
from optimum.intel import OVStableDiffusionControlNetPipeline
from controlnet_aux import OpenposeDetector
from pathlib import Path
import numpy as np
import os
from PIL import Image
from diffusers import UniPCMultistepScheduler
import requests
import torch
We recommand to use static shape model to decrease GPU memory cost. Set your STATIC_SHAPE and DEVICE_NAME.
Load image for ControlNet, or you can use your own image, or generate image with OpenPose OpenVINO model, notice that OpenPose model is not supported by OVStableDiffusionControlNetPipeline yet, so you need to convert it to openvino model first manually. Here we use directly the result from OpenPose:
InternVL2.0 is a series of multimodal large language models available in various sizes. The InternVL2-4B model comprises InternViT-300M-448px, an MLP projector, and Phi-3-mini-128k-instruct. It delivers competitive performance comparable to proprietary commercial models across a range of capabilities, including document and chart comprehension, infographics question answering, scene text understanding and OCR tasks, scientific and mathematical problem solving, as well as cultural understanding and integrated multimodal functionalities.
The image features a close-up view of a red panda resting on a wooden platform. The panda is characterized by its distinctive red fur, white face, and ears. The background shows a natural setting with green foliage and a wooden structure.
Here are the parameters with descriptions:
python test_ov_internvl2.py --help
usage: Export InternVL2 Model to IR [-h] [-m MODEL_ID] -ov OV_IR_DIR [-d DEVICE] [-pic PICTURE] [-p PROMPT] [-max MAX_NEW_TOKENS] [-llm_int4_com] [-vision_int8] [-llm_int8_quant] [-convert_model_only]
options:
-h, --help show this help message and exit
-m MODEL_ID, --model_id MODEL_ID model_id or directory for loading
-ov OV_IR_DIR, --ov_ir_dir OV_IR_DIR output directory for saving model
-d DEVICE, --device DEVICE inference device
-pic PICTURE, --picture PICTURE picture file
-p PROMPT, --prompt PROMPT prompt
-max MAX_NEW_TOKENS, --max_new_tokens MAX_NEW_TOKENS max_new_tokens
-llm_int4_com, --llm_int4_compress llm int4 weight scompress
-vision_int8, --vision_int8_quant vision int8 weights quantize
-llm_int8_quant, --llm_int8_quant llm int8 weights dynamic quantize
-convert_model_only, --convert_model_only convert model to ov only, do not do inference test
Supported optimizations
1. Vision model INT8 quantization and SDPA optimization enabled
2. LLM model INT4 compression
3. LLM model INT8 dynamic quantization
4. LLM model with SDPA optimization enabled
Summary
This blog introduces how to use the OpenVINO™ python API to run the pipeline of the Internvl2-4B model, and uses a variety of acceleration methods to improve the inference speed.

.png)