
.png)
Xiake
Sun
Efficient Inference and Quantization of CGD for Image Retrieval with OpenVINO™ and NNCF
Author:Xiake Sun, Wenyi Zou, Churkin Andrey
Introduction
With the advent of e-commerce and online websites, image retrieval applications have been increasing all along around our daily life. Top e-commerce platform such as Amazon and Alibaba have been heavily utilizing image retrieval to put forward what they think is the most suitable product based on what we have seen just now.
Image retrieval is the process of finding an image from a collection or database from the traits of a query image. The traits are usually visual similarities between the images. The top retrieved images can provide hypotheses about which parts of the scene are likely visible in the query image.
Since images in their original form don’t reflect these traits in their pixel-based data, we need to transform this pixel data into a latent space where the representation of the image will reflect the traits. Naver Corporation proposed Combination of Multiple Global Descriptors (CGD) for Image Retrieval task. The CGD framework exploits multiple global descriptors to get an ensemble effect when it can be trained in an end-to-end manner. Quantitative and qualitative analysis results show that exploiting multiple global descriptors led to higher performance over the single global descriptor.
Neural Network CompressionFramework (NNCF) provides a suite of post-training and training-time algorithms for neural network inference optimization in OpenVINO™ with minimal accuracy drop. NNCF is designed to work with models from PyTorch, TensorFlow, ONNX, and OpenVINO™. In this blog, we use NNCF Post-Training Quantization (PTQ) to quantize CGD model, which can further boost inference while keeping acceptable accuracy without fine-tuning.
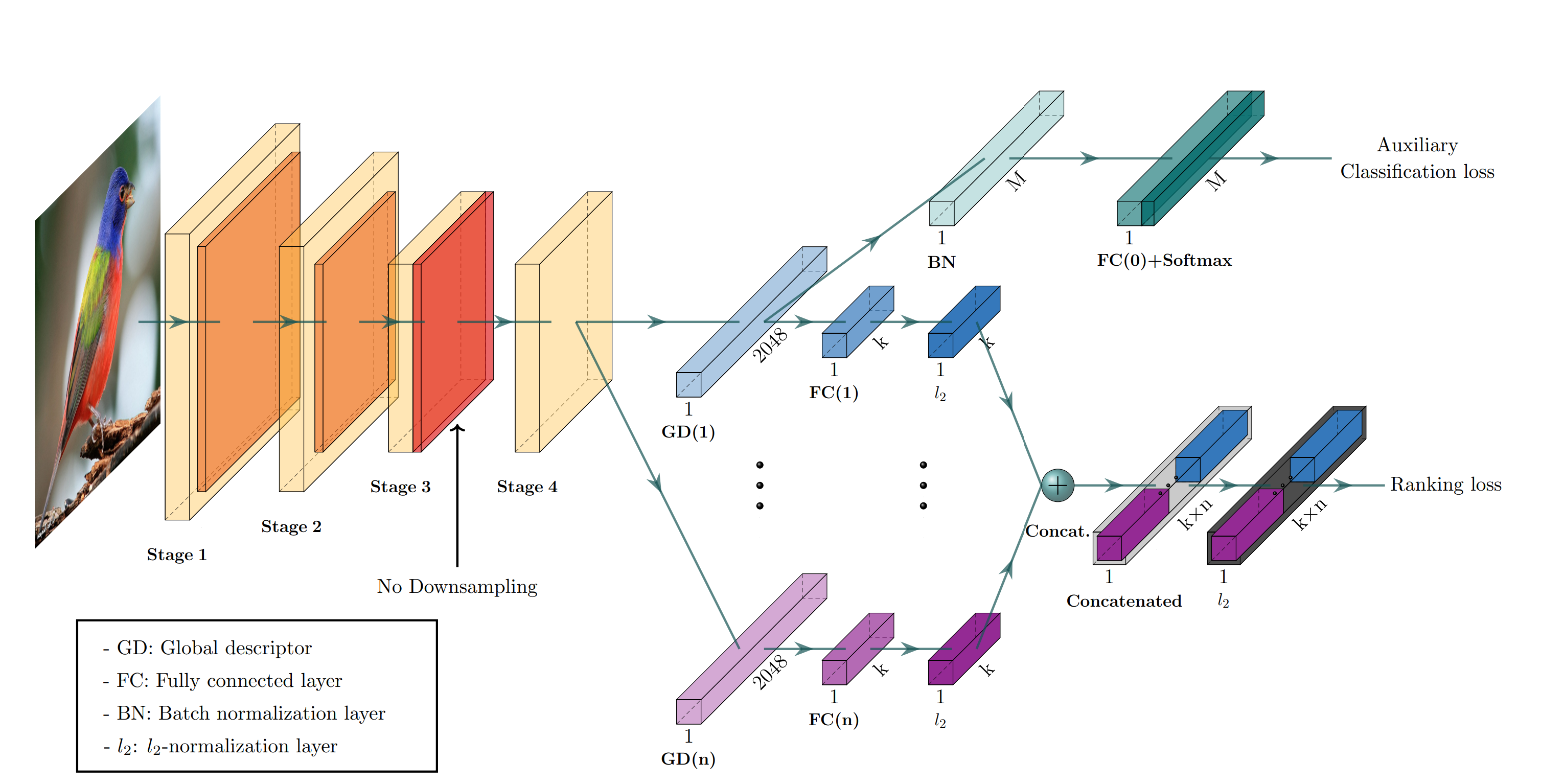
Figure1. shows the CGD framework. The framework is described with ResNet-50 backbone where Stage 3 down sampling is removed. From the last feature map, each of n global descriptor branches outputs a k-dimensional embedding vector, which is concatenated into the combined descriptor for ranking loss. Exclusively the first global descriptor is used for auxiliary classification loss where M denotes the number of classes.
CGD framework utilizes the following global descriptors with different focuses:
- Sum pooling of convolutions (SPoC): activates larger regions on the image representation.
- Generalized mean pooling (GeM): generalizes max and average pooling with a pooling parameter.
- Maximum activation of convolutions (MAC): activates more focused regions.
In this blog, we choose CGD ResNet50(SG) model with ResNet50 backbone that combines SPoC and GeM type of global descriptors. Figure 2 shows some retrieval results of CGD Pytorch model based on Standard Online Products (SOP) dataset. The left most query image serves as input to retrieve the 8 most similar image from the database, where the green bounding box means that the predicted class match the query image class, while the red bounding box means a mismatch of image class. Therefore, the retrieved image can be further filtered out with class information.

CGD Model Enabling and Quantization with OpenVINO™ and NNCF
To leverage efficient inference with OpenVINO™ runtime on the intel platform, we proposed the following workflow in Figure 3 for CGD model enabling and quantization with OpenVINO™ and NNCF PTQ, which is implemented in a single Python script run_quantize.py.

CGD model uses ResNet50 backbone extracted latent feature to create multiple global descriptors, then the global descriptors will be normalized and concatenated as output.
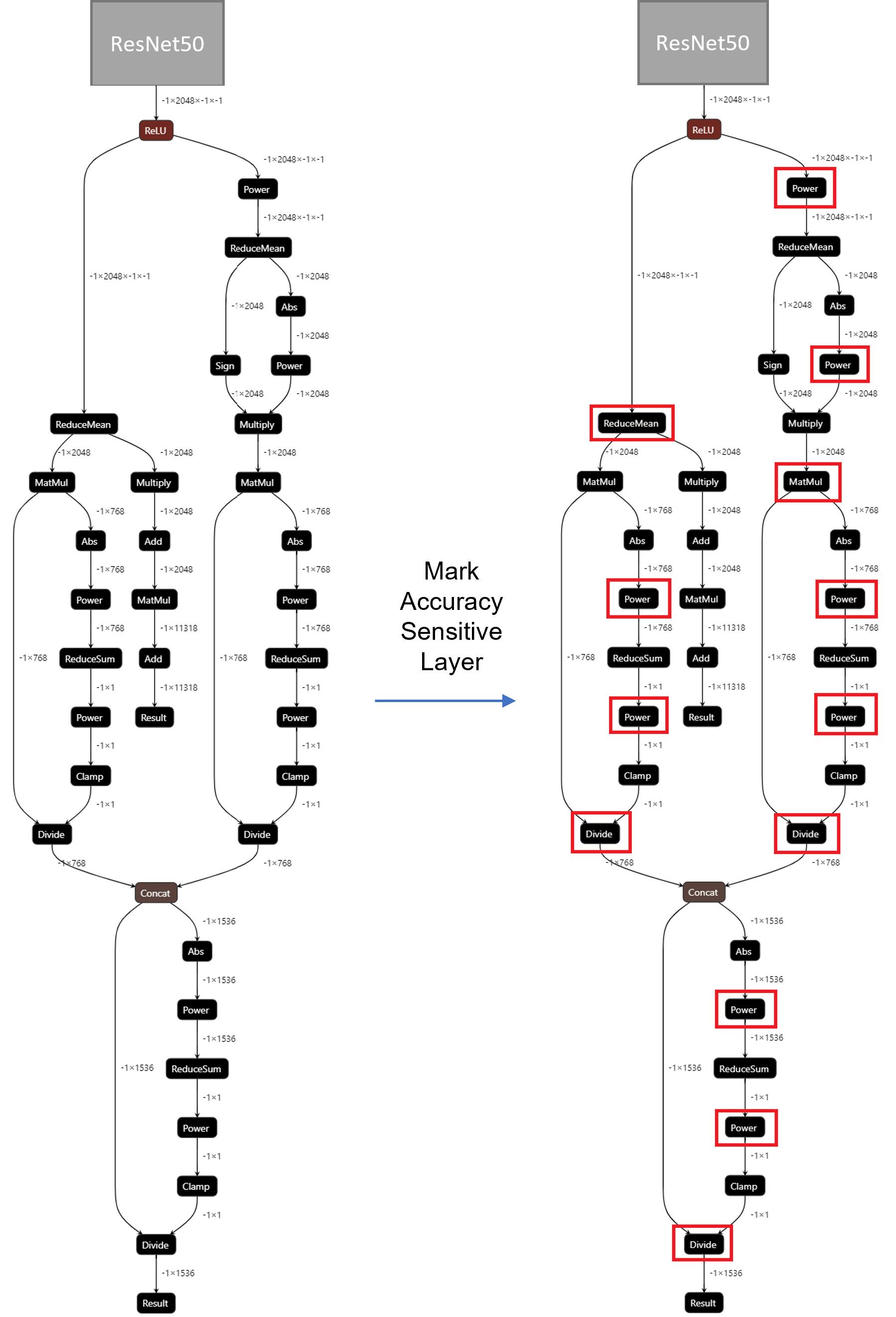
For INT8 quantization, we found some useful tricks to mitigate accuracy issue caused by accuracy sensitive layers, e.g., YOLOv8 OpenVINO Notebook proposes to keep several accuracy sensitive layers in post-processing subgraph as FP32 precision to better preserve accuracy after NNCF PTQ.
For INT8 quantization of CGD model, the left part of Figure 4 shows the subgraph of CGD for global descriptor combination and normalization. Original torch.nn.functional.normalize is accuracy sensitive, which are converted to OpenVINO™ operators (e.g. Power, Divide). Quantization of these operators from FP32 to INT8 weights can lead to accuracy degradation. Here we marked all accuracy-sensitive layers in the right part of Figure 4.
Furthermore, we can use ignored_scopes in NNCF configuration to skip these layers for INT8 quantization to remain FP32 precision as follows:
CGD OpenVINO™ Demo
Here we can run a CGD demo with CGD_OpenVINO_Demo as follows:
Setup Environment
Prepare dataset based on Standard Online Products (SOP)
Download pre-trained Pytorch CGD ResNet50(SG) model trained on SOP dataset to the results directory.
Verify Pytorch FP32 Model Image Retrieval Results
Run NNCF PTQ for default quantization with ignore scopes
Generated FP32 ONNX model and FP32/INT8 OpenVINO™ model will be saved in the “models” directory. Besides, we also store evaluation results of OpenVINO™ FP32/INT8 model as a Database in the “results” directory respectively. The database can be directly used for image retrieval via input query image.
Verify OpenVINO™ FP32 Model Image Retrieval Results
Verify OpenVINO™ INT8 Model Image Retrieval Results
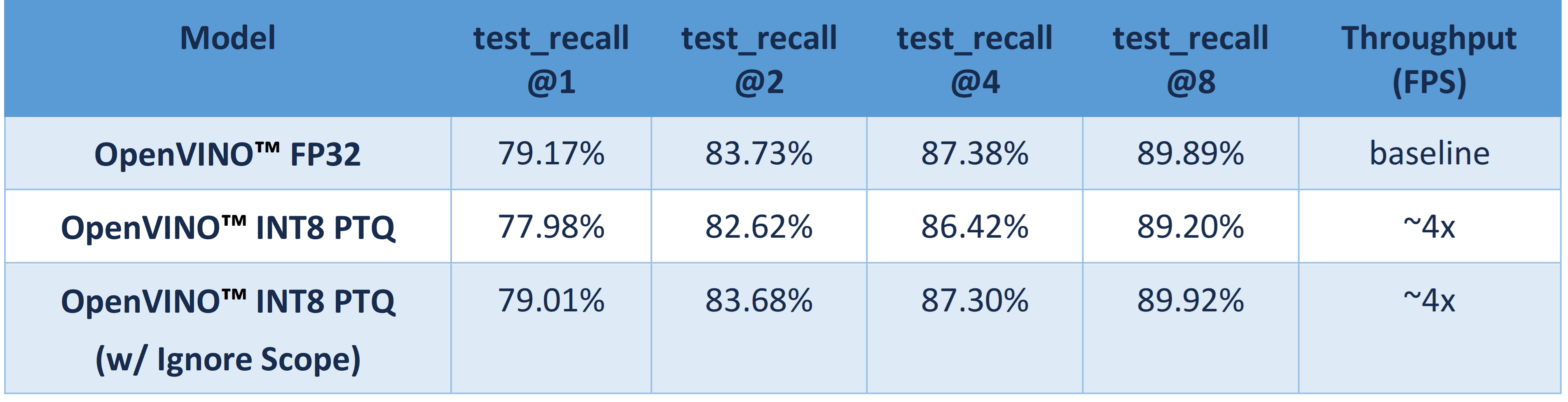
Table 1 shows CGD OpenVINO™ FP32 and INT8 accuracy verification and performance evaluation results with OpenVINO™ 2023.0 on Intel® Xeon® Platinum 8358 Processor.
From an accuracy perspective, test_recall@1/2/4/8 measures if the top n image retrieval results match with the query image. OpenVINO™ INT8 PTQ quantizes all FP32 layers to INT8, which leads to ~1.2% accuracy degradation compared with OpenVINO™ FP32 Model. OpenVINO™ INT8 PTQ (w/ IgnoreScope) skips quantization of accuracy sensitive layers via ignore scopes, which controls the accuracy difference between OpenVINO™ INT8 model and OpenVINO™FP32 model within 0.16%.
Compared with OpenVINO™ FP32 model, both OpenVINO™ INT8 PTQ and OpenVINO™ INT8 PTQ (w/ Ignore Scopes) can reach ~4x performance boost. Results show that keeping serval layers as FP32 precision has minimal impact on OpenVINO™ INT8 model.

Figure 5 shows the CGD Image Retrieval Results of Pytorch FP32, OpenVINO™ FP32/INT8 models with the same query image. The Pytorch and OpenVINO™ FP32 retrieved images are the same. Although the 7th image of OpenVINO™ INT8 model results is not matched with FP32 model's results, it can be further filtered out with predicted class information.
Conclusion
In this blog, we introduced how to enable and quantize the CGD model with OpenVINO™ runtime and NNCF:
- Proposed INT8 quantization NNCF PTQ with ignore scopes to reach ~4x performance boost while keeping minimal accuracy degradation (<0.16%) compared to FP32 model.
- Provided a demo repository for CGD model enabling, quantization, accuracy verification, and deployment with OpenVINO™ and NNCF.































