.png)
Alexander
Kozlov
Q4'23: Technology Update – Low Precision and Model Optimization
Authors
Alexander Kozlov, Nikita Savelyev, Nikolay Lyalyushkin, Vui Seng Chua, Pablo Munoz, Alexander Suslov, Andrey Anufriev, Liubov Talamanova, Yury Gorbachev, Nilesh Jain, Maxim Proshin
Summary
This quarter we observe that most of the work is still dedicated to the Large Language Model optimization. Researchers try to break through W4A8 quantization setup for LLMs achieving the accuracy results that allows considering such optimized models for deployment scenario. Some teams work on lower-precision settings such as 2-bit weight quantization or even binary weight compression. Interestingly, some teams propose to stick to a higher bit-width (FP6) and data-free optimization approach to avoid overfitting to calibration data. We also see an increasing interest in applying various types of weight sparsity in LLMs. And, of course, we should note the tremendous improvement in the inference time of Diffusion models caused by the decrease in the overall number of iterations in the diffusion process. This allows running variations of Stable Diffusion on mobile devices in the below 1 second.
Papers with notable results
Quantization
- AWEQ: Post-Training Quantization with Activation-Weight Equalization for Large Language Models by Jilin University (https://arxiv.org/pdf/2311.01305.pdf). Authors apply a known recipe for DL models quantization to LLM models. It contains weight equalization and bias correction methods stacked together. The difference is in how they estimate parameters and where to apply both methods. The method shows good results for W8A8 and W4A8 settings and outperforms GPTQ method on LLAMA and OPT models.
- AFPQ: Asymmetric Floating Point Quantization for LLMs by China Universities and Microsoft Research Asia (https://arxiv.org/pdf/2311.01792.pdf).Authors propose accurate asymmetric schema for the floating-point quantization. Instead of using typical asymmetric schema with scale and zero point, they use just2 scales: one is for positive values and another - for negative ones. It gives better accuracy NF4/NF3 quantization on different LLAMA models with no memory overhead. Code is available: https://github.com/zhangsichengsjtu/AFPQ.

- Enhancing Computation Efficiency in Large Language Models through Weight and Activation Quantization by Hanyang University, SAPEON Korea Inc., Seoul National University (https://arxiv.org/pdf/2311.05161.pdf). Authors present two techniques: activation-quantization-aware scaling (a trade-off between SQ and AWQ) and sequence-length-aware calibration (adaptation of OPTQ to various sequence lengths) to enhance PTQ by considering the combined effects on weights and activations and aligning calibration sequence lengths to target tasks. They also introduce dINT, a hybrid data format combining integer and denormal representations, to address the underflow issue in W4A8 quantization, where small values are rounded to zero. The combined approach allows for achieving superior results compared to baselines. However, dINT has a limitation of efficient implementation on a general-purpose HW, such as CPU and GPU.
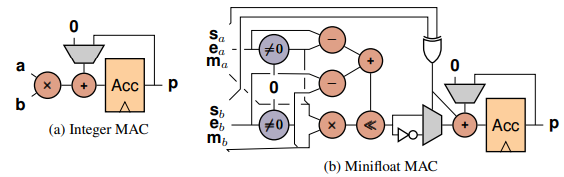
- POST-TRAINING QUANTIZATIONWITH LOW-PRECISION MINIFLOATS AND INTEGERS ON FPGAS by AMD Research, National University of Singapore, and Tampere University (https://arxiv.org/pdf/2311.12359.pdf). Authors compare integer and mini float quantization techniques, encompassing a combination of state-of-the-art PTQ methods, such as weight equalization, bias correction, SmoothQuant, learned rounding, and GPTQ. They explore the accuracy-hardware tradeoffs, providing analysis for three models -ResNet-18, MobileNetV2, and ViT-B32 - based on a custom FPGA implementation. Experiments indicate that mini float quantization typically outperforms integer quantization for bit-widths of four or more, both for weights and activations. However, when compared against FPGA hardware cost model, integer quantization often retains its Pareto optimality due to its smaller hardware footprint at a given precision.
- I&S-ViT: An Inclusive& Stable Method for Pushing the Limit of Post-Training ViTs Quantization by Xiamen University, Tencent, and Peng Cheng Laboratory (https://arxiv.org/pdf/2311.10126.pdf). The paper introduces a method that regulates the PTQ of ViTs in an inclusive and stable fashion. It first identifies two issues in the PTQ of ViTs: (1)Quantization inefficiency in the prevalent log2 quantizer for post-Softmax activations; (2) Rugged and magnified loss landscape in coarse-grained quantization granularity for post-LayerNorm activations. Then, the method addresses these issues by introducing: (1) A novel shift-uniform-log2 quantizer(SULQ) that incorporates a shift mechanism followed by uniform quantization to achieve both an inclusive domain representation and accurate distribution approximation; (2) A three-stage smooth optimization strategy that amalgamates the strengths of channel-wise and layer-wise quantization to enable stable learning. The method achieves comparable results in the W4A4 and W3A3 quantization settings.
- Quantizable Transformers: Removing Outliers by Helping Attention Heads Do Nothing by Qualcomm AI Research (https://arxiv.org/pdf/2306.12929.pdf). This work aims to remove outliers by construction (pretraining) so that transformer can be quantized easily without the need of finer quantization granularity (e.g. per channel, per group). The authors root-caused that outliers in trained transformers are essentially the artifact of attention head attenuating uninformative tokens and outliers emerged in the formulation/backpropagation of softmax, residual connections and layer normalization to sustain the effect of these tokens. Two independent solutions are proposed - (1) Clipped softmax that allows exact zeros and ones in softmax to avoid growing outliers during training. (2) Gated attention which is a tiny neural network (linear+sigmoid) added to the vanilla attention to decouple the needs of large attention output for disregarding the uninformative tokens. Pretraining with the proposed formulation on BERT, OPT and ViT has been shown to converge similarly if not better than baseline recipe. Most notably, the ease of per-tensor int8 static quantization to both weight and activation in post-training fashion has been empirically verified. Code is coming soon at https://github.com/qualcomm-ai-research/outlier-free-transformers
- A Speed Odyssey for Deployable Quantization of LLMs by Meituan (https://arxiv.org/pdf/2311.09550.pdf).Authors propose a solution for deployable W4A8 quantization that comprises a tailored quantization configuration and a novel Fast GEMM kernel for 4-bitinteger matrix multiplication that reduces the cost, and it achieves 2.23× and1.45× speed boosting over the TensorRT-LLM FP16 and INT8 implementation respectively. The W4A8 recipe is proven mostly on par with the state-of-the-art W8A8 quantization method SmoothQuant on a variety of common language benchmarks for the state-of-the-art LLMs.
- TFMQ-DM: Temporal Feature Maintenance Quantization for Diffusion Models by SenseTime and universities of US, China and Australia (https://arxiv.org/pdf/2311.16503.pdf). Authors investigate the problems in quantization of diffusion models and claim that these models heavily depend on the time-step t to achieve satisfactory multi-round denoising when t is encoded to a temporal feature by a few modules totally irrespective of the sampling data. They propose a Temporal Feature Maintenance Quantization framework building upon a Temporal Information Block which is just related to the time-step t and unrelated to the sampling data. Powered by this block design, authors propose temporal information aware reconstruction and finite set calibration to align the full-precision temporal features in a limited time. The method achieves accurate results even in W4A8quantization setting.
- QUIK: TOWARDS END-TO-END4-BIT INFERENCE ON GENERATIVE LARGE LANGUAGE MODELS by ETH Zurich, Institute of Science and Technology Austria, Xidian University, KAUST, Neural Magic (https://arxiv.org/pdf/2310.09259v2.pdf). The paper addresses the problem where both weights and activations should be quantized. Authors show that the majority of inference computations for large generative models such as LLaMA, OPT, and Falcon can be performed with both weights and activations being cast to 4 bits, in a way that leads to practical speedups, while at the same time maintaining good accuracy. They achieve this via a hybrid quantization strategy called QUIK, which compresses most of the weights and activations to 4-bit, while keeping some outlier weights and activations in higher precision which leads to practical end-to-end throughput improvements of up to 3.4x relative to FP16 execution. Code is available at: https://github.com/IST-DASLab/QUIK.
- Post-training Quantization with Progressive Calibration and Activation Relaxing for Text-to-Image Diffusion Models by Tsinghua University (https://arxiv.org/pdf/2311.06322.pdf). Authors propose a post-training quantization method for text-to-image diffusion models, which consists of a progressive calibration strategy that considers the accumulated quantization error across timesteps, and an activation relaxing strategy that improves the performance with a small cost. They also propose a new QDiffBench benchmark, which utilizes data in the same domain for a more accurate evaluation of the generation accuracy.

- Enabling Fast 2-bit LLM on GPUs: Memory Alignment, Sparse Outlier, and Asynchronous Dequantization by Shanghai Jiao Tong University and Tsinghua University (https://arxiv.org/pdf/2311.16442.pdf).The paper proposes range-aware quantization with memory alignment. It points out that the range of weights by groups varies. Thus, only 25% of the weights are quantized using 4-bit with memory alignment. Such a method reduces the accuracy loss for 2-bit Llama2-7b quantization from 8.7% to 2.9%. Authors show as well that only a small fraction of outliers exist in weights quantized using2-bit. These quantize these sparse outliers with < 3% increased average weight bit and improve the accuracy by >0.5%. They also accelerate GPU kernels by introducing asynchronous dequantization achieving 3.92× improvement on a kernel level.
- ZeroQuant(4+2): Redefining LLMs Quantization with a New FP6-Centric Strategy for Diverse Generative Tasks by DeepSpeed (https://arxiv.org/pdf/2312.08583.pdf).Authors show that popular data-aware LLM compression methods such as GPTQ can overfit to calibrated datasets especially on moderate-size LLMs (<=1B). They also illustrate that FP6, employing a basic round-to-nearest (RTN) algorithm and a per-channel quantization approach, consistently achieves accuracy on par with full-precision models. They propose an unpacking (mapping) scheme for FP8 so that it can be efficiently used with FP16 inference.
Pruning/Sparsity
- Sparse Fine-tuning for Inference Acceleration of Large Language Models by IST Austria, Skoltech & Yandex, and Neural Magic (https://arxiv.org/pdf/2310.06927.pdf). The paper analyses the challenges of LLMs pruning, namely loss spikes leading to divergence, poor recovery from fine-tuning, and overfitting. To overcome these issues, authors incorporate standard cross-entropy, output knowledge distillation, and a type of per-token ℓ2 knowledge distillation on top of SparseGPT method. They show that the resulting sparse models can be executed with inference speedups on CPU and GPU, especially when stacking with INT8quantization. The code is available: https://github.com/IST-DASLab/SparseFinetuning.
- ReLU Strikes Back: Exploiting Activation Sparsity in LLMs by Apple. (https://arxiv.org/pdf/2310.04564.pdf). This work advocates to reinstate ReLU as main activation function in LLMs due to its intriguing property – high post-ReLU activation sparsity can be translated to computational efficiency with sparse runtime. To overcome training from scratch and for LLMs employing GeLU/SiLU, the paper proposes “Relufication”, a two-stage uptraining by first replacing non-ReLU activations in pre-trained LLMs with ReLU, and then appending ReLU to normalization layers in second stage for more sparsity. With increase of activation sparsity, the authors also observe high overlapping activated neurons during decoding (termed aggregated sparsity) and suggest weight reuse to alleviate memory transfer. The authors show application of aggregated sparsity in speculative decoding and demonstrate 27% speedup of OPT-6.7B at a minor degradation of perplexity.
- Deja Vu: Contextual Sparsity for Efficient LLMs at Inference Time by Rice University, Zhe Jiang University, Stanford University, University of California, ETH Zurich, Adobe Research, MetaAI, Carnegie Mellon University (https://proceedings.mlr.press/v202/liu23am/liu23am.pdf). Authors propose a contextual dynamic sparsity method for LLMs. Contrary to a usual sparsity approach where a model is pruned once and then inferenced on every input sample in the same pruned state, here authors compute the set of pruned operations on the run resulting in a more flexible pruning scheme. Foreach transformer layer this is achieved by predicting set of MHA heads and MLP matrix columns to exclude based on previous layers activations. Prediction is performed by small separately trained perceptron networks. To remove the performance bottleneck produced by the need to inference of perceptron networks authors propose to make sparsity predictions for (i+1)-th transformer layer based on activations from (i-1)-th layer, resulting in parallel computation of i-th layer and sparsity sets for (i+1)-th layer. This is viable due to shown similarity between activations of neighboring layers in LLMs. For OPT-175Bmodel the approach achieves over 6x performance improvement compared to Hugging Face implementation and over 2x improvement compared to state-of-the-art FasterTransformer model.
- SparseByteNN: A Novel Mobile Inference Acceleration Framework Based on Fine-Grained Group Sparsity by ByteDance (https://arxiv.org/pdf/2310.19509.pdf). The paper introduces SparseByteNN, consisting of three components: a)compression algorithm component, which provides out-of-the-box pruning capabilities for pre-trained models b) model conversion tool, which converts the model IR of the training framework into Model IR of sparse engine c) sparse inference engine, which provides efficient inference implementation compatible with CPUs for fine-grained kernel group sparsity. Experimental results on Qualcomm 855 show that for 30% sparse MobileNet-v1, SparseByteNN achieves 1.27×speedup over the dense version. The code will be available at: https://github.com/lswzjuer/SparseByteNN.
Neural Architecture Search
- LoNAS: Elastic Low-Rank Adapters for Efficient Large Language Models by Anonymous (https://openreview.net/pdf?id=pzB-1OCS6gd). Researchers demonstrate a novel integration of low-rank (LoRA)adapters with Neural Architecture Search. LoNAS efficiently fine-tunes and compress large language models (LLMs). A weight-sharing super-network is generated using the frozen weights of the input model, and the attached elastic low-rank adapters. The reduction in trainable parameters results in less the memory requirements to train the super-network, enabling the manipulation of LLMs in resource-constrained devices, without sacrificing the performance of the resulting compressed models. LoNAS’ high-performing compressed models result in faster inference times, cost savings during the model’s lifetime, and an increase in the range of devices in which large language models can be deployed. Experiments’ results on six reasoning datasets demonstrate the benefits of LoNAS.
- Bridging the Gap between Foundation Models and Heterogenous Federated Learning by Iowa State U. and Intel Labs (https://arxiv.org/abs/2310.00247). This paper explores the application of Neural Architecture Search (NAS) in combination with Federated Learning (FL). The proposed framework, Resource-aware Federated Foundation Models (RaFFM) introduces model compression and salient parameter prioritization in the context of Federated Learning, allowing for the collaborative training of large foundation models using heterogeneous devices. Compared to traditional FL methods, RaFFM yields better resource utilization, without sacrificing in model performance.
- Rankitect: Ranking Architecture Search Battling World-class Engineers at Meta Scale by Meta Platforms (https://arxiv.org/pdf/2311.08430.pdf). Researchers at Meta demonstrate the real-world applications of Neural Architecture Search (NAS). They apply NAS to production models, e.g., Click Through Rate (CTR) model, on a system that serves billions of users. The baseline models explored in this work have already been optimized by world-class engineers. The proposed NAS framework, Rankitect, improves over existing models by exploring search spaces with no inductive bias from the baseline models, and discovers new models from scratch that outperform those hand-crafted by human experts. Rankitect also keeps human engineers in-the-loop by allowing the manual design of search spaces, which results in even more efficient models.
- QuadraNet: Improving High-Order Neural Interaction Efficiency with Hardware-Aware Quadratic Neural Networks by George Mason University, University of Maryland, University at Buffalo, Peking University (https://arxiv.org/pdf/2311.17956.pdf). This paper presents QuadraNet, a new neural network design methodology based on efficient quadratic neurons that captures high-order neural interactions similar to Transformer-based models. The design of this alternative to Transformer-based models is hardware-aware through the application of Neural Architecture Search(NAS). Experiments with QuadraNets show improvements of 1.5x in throughput without any reduction in accuracy compared to their Transformer-based counterparts.
Other
- Divergent Token Metrics: Measuring degradation to prune away LLM components – and optimize quantization by Aleph Alpha, Hessian.AI and German Universities. (https://arxiv.org/pdf/2311.01544.pdf). The work highlights that the commonly used perplexity (PPL) metric in compression research does not reflect the degradation of compressed model and cannot distinguish subtleties (see figure below). The authors propose a family of divergent token metrics (DTM), namely First Token Divergence, i.e., when the first diverging token happens w.r.t baseline generated text, as well as Share of Divergent Tokens denoting the total number of divergent tokens. In a series of experiments pertaining to layer-wise quantization or pruning, DTM-based ranking consistently outperforms PPL-based ranking methods.

- SIMPLIFYING TRANSFORMERBLOCKS by ETH Zurich (https://arxiv.org/pdf/2311.01906.pdf). The paper introduces a set of Transformer block pruning techniques that makes them more lightweight from the number of parameters and computations standpoint. This set includes: removing skip connection both in the Attention sub-block and Feed-Forward sub-block, removing value and projection parameters, removing normalization layers, and model depth scaling. Authors also show how to recover the accuracy after model perturbation using fine-tuning. The proposed method produces the decoder and decoder Transformer models that perform on part with their baselines: 15% faster training throughput, and using 15% fewer parameters.
- MobileDiffusion: Subsecond Text-to-Image Generation on Mobile Devices by Google (https://arxiv.org/pdf/2311.16567.pdf).The paper presents a comprehensive guide for crafting highly efficient text-to-image diffusion models. Authors applied the following tricks to highly optimize UNet model in the Diffusion pipeline: more transformers in the middle of Unet (at lower resolution), retaining cross-attention layers while discarding only the self-attention layers at high resolutions, sharing key-value projections, replacing gelu with swish, fine-tune softmax into relu, trim feed-forward layers, use separable convolution, prune redundant residual blocks, reduce sampling iterations, knowledge distillation. The resulting model is able to generate 512×512 images in sub-second on mobile devices: 0.2 second on iPhone 15 Pro.

- Online Speculative Decoding by UC Berkeley, UCSD, Sisu Data, SJTU (https://arxiv.org/pdf/2310.07177.pdf). Practical speedup of speculative decoding is often impeded by the capability gap between draft and target model which can be 10-20X gap in parameters, leading to high rejection of draft predictions and fallback to more forward passes of target model. This work proposes online fine-tuning of draft model by distillation with the readily available rejected predictions. The proposed solution incorporates a replay buffer tracking logits of draft and target model, and distillation backpropagation is executed at a regular interval. Experimental results demonstrate not only significant improvement in acceptance rate, translating up to a theoretical 3X of latency reduction, but also adaptability against distribution shift in input queries.
- Token Fusion: Bridging the Gap between Token Pruning and Token Merging by Michigan State University Samsung Research America (https://arxiv.org/pdf/2312.01026.pdf).The paper introduces a method (ToFu) that combines token pruning and token merging. ToFu dynamically adapts to each layer’s properties, ensuring optimal performance based on the model’s functional linearity with respect to the interpolation in its input. Authors exploit MLERP merging technique, an enhancement over traditional average merging, inspired by the SLERP method. This approach merges tokens while preserving their norm distribution. Evaluation shows that ToFu outperforms ToMe in terms of accuracy while showing the similar performance gain at inference.
Deep Learning Software
- Medusa: Simple Framework for Accelerating LLM Generation with Multiple Decoding Heads by Together.AI. Contemporary speculative decoding solutions (Leviathan et al., Chen et al.) require multiple models (target and draft models) which often involves intricate optimization& selection of draft models to attain practical acceleration. For simplicity, Together.AI unveils a user-friendly framework, Medusa, built a top of a research work in 2018, "Block wise Parallel Decoding", with multiple enhancements. Medusa simplifies the creation of draft models without separate models by extending base model with multiple decoding heads. By keeping the base model frozen, the Medusa heads are trained in a parameter-efficient way and all on a single GPU. Medusa also features a tree-based attention mechanism for parallel evaluation of the proposed candidates, and a truncated sampling for efficient creative generation. Results and framework can be found at https://github.com/FasterDecoding/Medusa.
- HyperAttention: Long-context Attention in Near-Linear Time by Yale University and Google https://github.com/insuhan/hyper-attn. Authors propose algorithm that consists of (1) finding heavy entries inattention matrix and (2) column subsampling. For (1), authors use the sorted locality sensitive hashing (sortLSH) based on the Hamming distance. Applying sortLSH makes heavy entries in the attention matrix (sorting rows/columns) located in near diagonal hence authors do block-diagonal approximation which can be done fast. The method supports casual masking. Code is available here: https://github.com/insuhan/hyper-attn.
- Flash-Decoding for long-context inference by Stanford University. Flash Attention v1 & v2 are designed and optimized primarily for training case and exhibit low utilization of compute units when applied for LLM generation, especially for long context. As identified cause is rooted in low- batch size (query tokens) in relative to context length, Flash Decoding extends flash attention by adding 2nd-level tiling over the keys/values to improve compute utilization while retaining memory efficiency of flash attention. On A100, the micro-benchmark for multi-head attention with flash decoding kernel achieves almost constant run-time as the sequence length scales to up to 64k, translating up to 8X speedup of CodeLLaMa-34b over vanilla flash attention at very long sequences. Implementation is available at official flash attention repo & xformers.
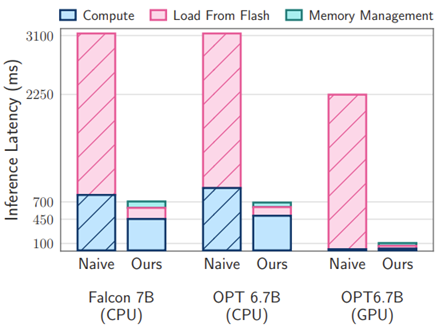
- LLM in a flash: Efficient Large Language Model Inference with Limited Memory by Apple (https://arxiv.org/pdf/2312.11514.pdf).The paper tackles the challenge of efficiently running LLMs that exceed the available DRAM capacity by storing the model parameters on flash memory but bringing them on demand to DRAM. The method involves constructing an inference cost model that harmonizes with the flash memory behavior, guiding to optimize in two critical areas: reducing the volume of data transferred from flash and reading data in larger, more contiguous chunks. Within this flash memory-informed framework, authors introduce two principal techniques. First, “windowing” strategically reduces data transfer by reusing previously activated neurons, and second, “row-column bundling”, tailored to the sequential data access strengths of flash memory, increases the size of data chunks read from flash memory. These methods collectively enable running models up to twice the size of the available DRAM, with a 4-5x and 20-25x increase in inference speed compared to naive loading approaches in CPU and GPU, respectively.