
.png)
Su
Yang
SDPA Enabling for Custom Model
Authors: Su Yang, Xiake Sun, Fiona Zhao
Introduction
To enable the SDPA fusion on GPU, we firstly need to convert model IR with SDPA Op.
Create new class SdpaAttention in the modeling_ custom_model.py using torch.scaled_dot_product_attention. This Pytorch Op could be matched and converted into OpenVINO SDPA Op.
Refer to Phi3SdpaAttention, this module is inherited from Phi3Attention as the weights of the module stay untouched. The only changes are on the forward pass to adapt to SDPA API.
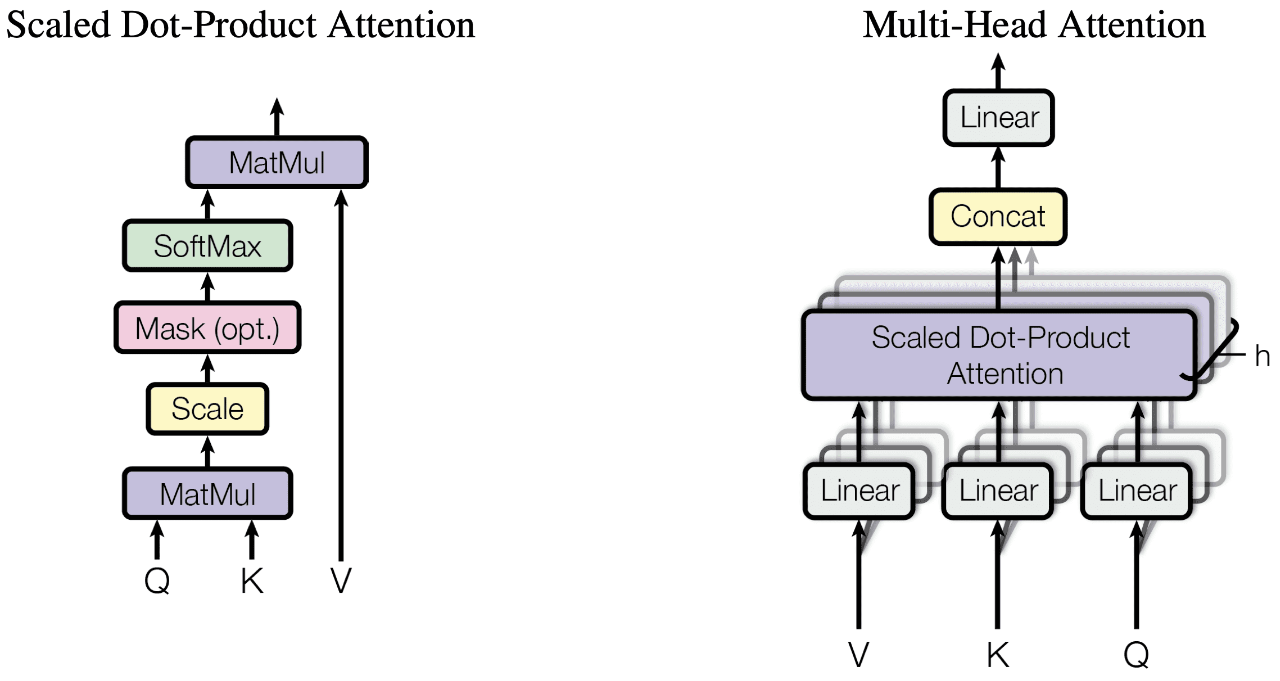
torch.scaled_dot_product_attention
From the equivalent implementation, the target is to replace the related Pytorch Ops(like softmax, matmul and dropout) with torch.nn.functional.scaled_dot_product_attention.
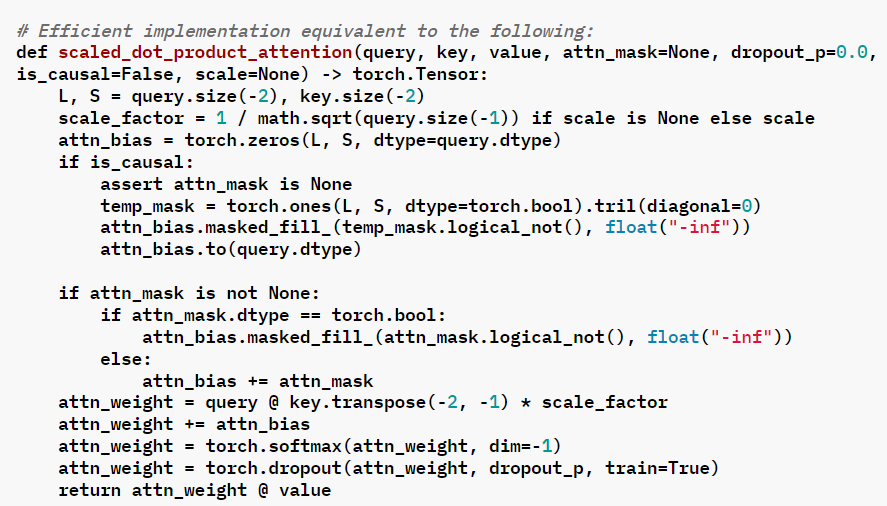
For some custom model, the equivalent code in is as follow:
The corresponding implementation of scaled_dot_product_attention:
SDPA’s Scaling factor with different head_size
For the Pytorch model with different head_size, this scaled_dot_product_attention need to be modified with the scaling factor.
The SDPA Operator has already implemented. The SDPA fusion on GPU supports for head size =128 at OV24.2 release.
The OV24.3 release relax SDPA head size limitations for LLMs from 128 only to a range of 64 to 256, thanks to Sergey’s PR.
Usage
Replace the original modeling_custom_model.py with the new script (with SdpaAttention) in the Pytorch model folder.
Notice:
- After converting model again, check the SDPA layers (“aten::scaled_dot_product_attention”) in the OV IR .xml file.
- Double check the OpenVINO executable graph for the SDPA enabling.
- Don’t forget to check the accuracy of the Pytorch model inference, after any modification with modeling_custom_model.py.
Conclusion
In this blog, we introduce how to use torch.scaled_dot_product_attention to enable the SDPA for custom model.
Performance improvement with SDPA on MTL iGPU is depended on the model structure. SDPA enabling for the custom model is the base for further optimization like Page Attention.


