
.png)
Anna
Likholat
Extend OpenVINO™ to run PyTorch models with custom operations
Authors: Anna Likholat, Nico Galoppo
The OpenVINO™ Frontend Extension API lets you register new custom operations to support models with operations that OpenVINO™ does not support out-of-the-box. This article explains how to export the custom operation to ONNX, add support for it in OpenVINO™, and infer it with the OpenVINO™ Runtime.
The full implementation of the examples in this article can be found on GitHub in the openvino_contrib.
Export a PyTorch model to ONNX
Let's imagine that we have a PyTorch model which includes a new complex multiplication operation created by user (this operation was taken from DIRECT):
We'd like to export the model to ONNX and preserve complex multiplication operations as single fused nodes in the ONNX model graph, so that we can replace those nodes with custom OpenVINO operations down the line. If we were to export MyModel which directly calls the function above from its forward method, then onnx.export() would inline the PyTorch operations into the graph. This can be observed in the figure of the exported ONNX model below.
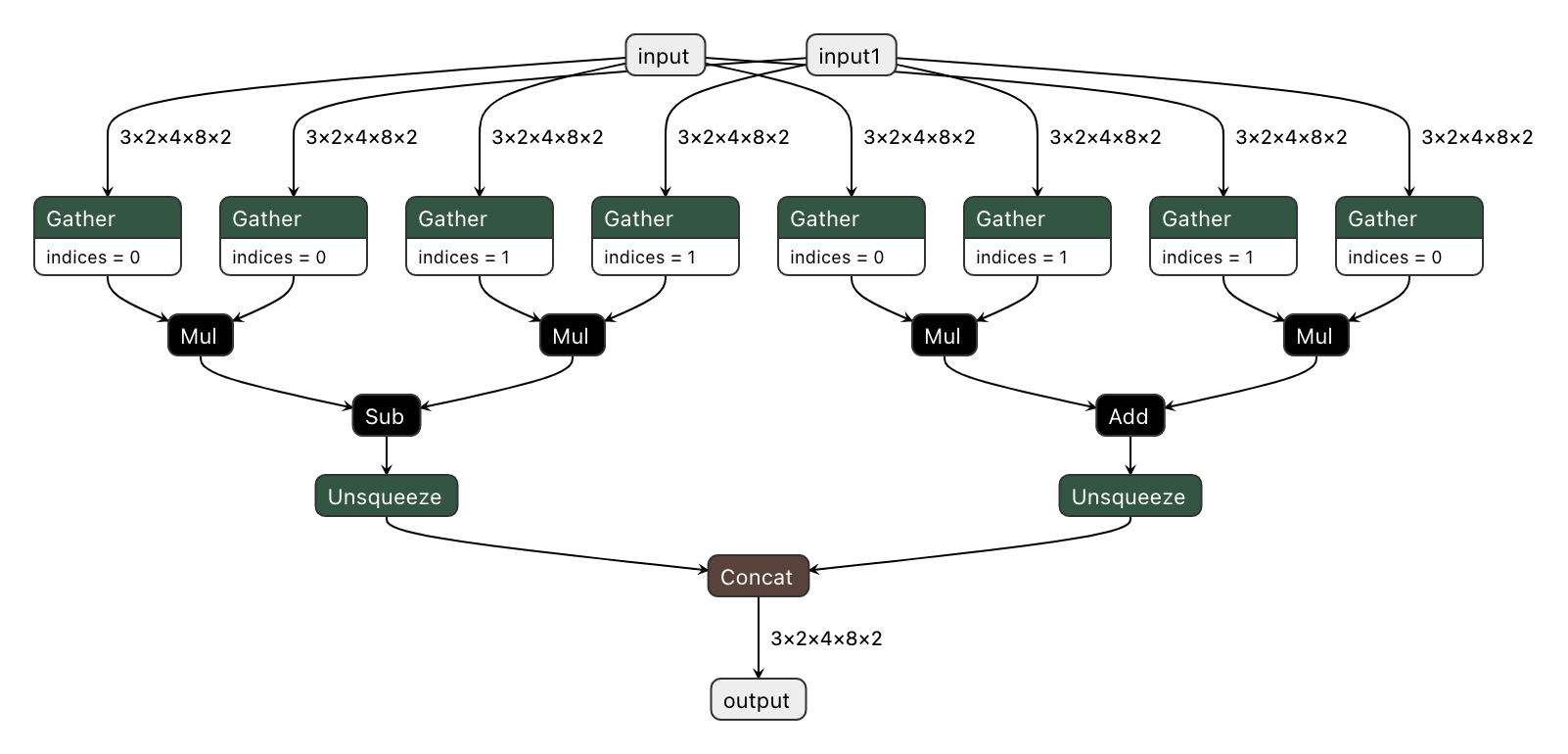
To prevent inlining of native PyTorch functions during ONNX export, we can wrap the function in a sub-class of torch.autograd.Function and define a static symbolic method. This method should return ONNX operators that represent the function's behavior in ONNX. For example:
You can find the full implementation of the wrapper class here: complex_mul.py
So now we're able to export the model with custom operation nodes to ONNX representation. You can reproduce this step with the export_model.py script:
The resulting ONNX model graph now has a single ComplexMultiplication node, as illustrated below:
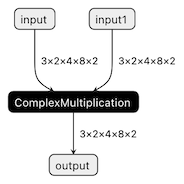
Enable custom operation for OpenVINO with Extensibility Mechanism
Now we can proceed with adding support for the ComplexMultiplication operation in OpenVINO. We will create an extension library with the custom operation for OpenVINO. As described in the Custom OpenVINO Operations docs, we start by deriving a custom operation class from the ov::op::Op base class, as in complex_mul.hpp.
1. Implement Operation Constructors
Implement the default constructor and constructors that optionally take the operation inputs and attributes as parameters. (code)
2. Override methods
2.1 validate_and_infer_types() method
Validates operation attributes and calculates output shapes using attributes of the operation: complex_mul.cpp.
2.2 clone_with_new_inputs() method
Creates a copy of the operation with new inputs: complex_mul.cpp.
2.3 has_evaluate() method
Defines the contstraints for evaluation of this operation: complex_mul.cpp.
2.4 evaluate() method
Implementation of the custom operation: complex_mul.cpp
3. Create an entry point
Create an entry point for the extension library with the OPENVINO_CREATE_EXTENSIONS() macro, the declaration of an extension class might look like the following:
This is implemented for the ComplexMultiplication operation in ov_extension.cpp.
4. Configure the build
Configure the build of your extension library using CMake. Here you can find the template of such script:
Also see an example of the finished CMake script for module with custom extensions here: CMakeLists.txt.
5. Build the extension library
Next we build the extension library using CMake. As a result, you'll get a dynamic library - on Linux it will be called libuser_ov_extensions.so, after the TARGET_NAME defined in the CMakeLists.txt above.
Deploy and run the custom model
You can deploy and run the exported ONNX model with custom operations directly with the OpenVINO Python API. Before we load the model, we load the extension library into the OpenVINO Runtime using the add_extension() method.
Now you're ready to load the ONNX model, and infer with it. You could load the model from the ONNX file directly using the read_model() method:
Alternatively, you can convert to an OpenVINO IR model first using Model Optimizer, while pointing at the extension library:
Note that in this case, you still need to load the extension library with the add_extension() method prior to loading the IR into your Python application.
The complete sequence of exporting, inferring, and testing the OpenVINO output against the PyTorch output can be found in the custom_ops test code.
See Also


