.png)
Arindam
Introducing OpenVINO™ integration with TensorFlow*
ArindamViral adoption of technologies is often triggered by leaps in user experience. For example, the iPhone prompted the rapid adoption of smartphones and the “app store.” Or, more recently, the ease of use seen in TensorFlow kickstarted the massive growth of Artificial Intelligence that touches almost every aspect of our daily lives today.
OpenVINO™ toolkit has redefined AI inferencing on Intel powered devices and has attained unprecedented developer adoption. Today hundreds of thousands of developers use OpenVINO™ toolkit to accelerate AI inferencing across almost all imaginable use cases, from emulation of human vision, automatic speech recognition, natural language processing, recommendation systems, and many others. Based on latest generations of artificial neural networks, including Convolutional Neural Networks (CNNs), recurrent and attention-based networks, the toolkit extends computer vision and non-vision workloads across Intel® hardware (Intel® CPU, Intel® Integrated Graphics, Intel® Neural Compute Stick 2, and Intel® Vision Accelerator Design with Intel® Movidius™ VPUs), maximizing performance. It accelerates applications with high-performance, AI, and deep learning inference deployed from edge to cloud.
We are honored to partner with our customers and contribute to their success. We are constantly listening and innovating to meet their evolving needs while also aiming to provide a world class user experience. Therefore, based on customer feedback, and building on OpenVINO™ toolkit’s success, we are introducing the OpenVINO™ integration with TensorFlow*. This integration enables TensorFlow developers to accelerate inferencing of their TensorFlow models in deployment with just 2 additional lines of code.
Benefits for TensorFlow Developers:
OpenVINO™ integration with TensorFlow* delivers OpenVINO™ toolkit inline optimizations and runtime needed for an enhanced level of TensorFlow compatibility. It is designed for developers who would like to experience the benefits of using OpenVINO™ toolkit – help boost performance for their inferencing applications – with minimal code modifications. It accelerates inference across many AI models on a variety of Intel® silicon, such as:
- Intel® CPU
- Intel® Integrated Graphics
- Intel® Movidius™ Vision Processing Units - referred as VPU
- Intel® Vision Accelerator Design with 8 Intel Movidius™ MyriadX VPUs - referred as VAD-M or HDDL
Developers leveraging this integration can expect the following benefits:
- Performance acceleration compared to native TensorFlow (depending on underlying hardware configuration).
- Accuracy – preserve accuracy nearly identical to original model.
- Simplicity – Continue to use TensorFlow APIs for inferencing. No need to refactor code. Just import, enable, and set device.
- Robustness – architected to support a wide range of TensorFlow models and operators across a variety of OS/Python environments.
- Seamless, inline model conversions – no explicit model conversion required.
- Lightweight footprint – minimal incremental memory and disk footprint required.
- Support for broad range of Intel powered devices – CPUs, iGPUs, VPUs (Myriad-X).
[Note: For maximum performance, efficiency, tooling customization, and hardware control, we recommend going beyond this component to adopt native OpenVINO™ APIs and its runtime.]
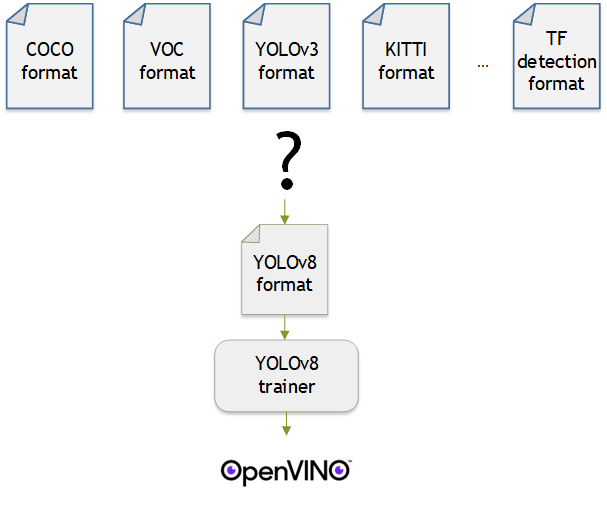
How does it work?
Developers can greatly accelerate the inferencing of their TensorFlow models by adding the following two lines of code to their Python code or Jupyter Notebooks.
import openvino_tensorflow
openvino_tensorflow.set_backend('<backend_name>')
Supported backends include 'CPU', 'GPU', 'MYRIAD', and 'VAD-M'. See Figure 1.
Sample code:
Here is an example of OpenVINO™ integration with TensorFlow* at work:
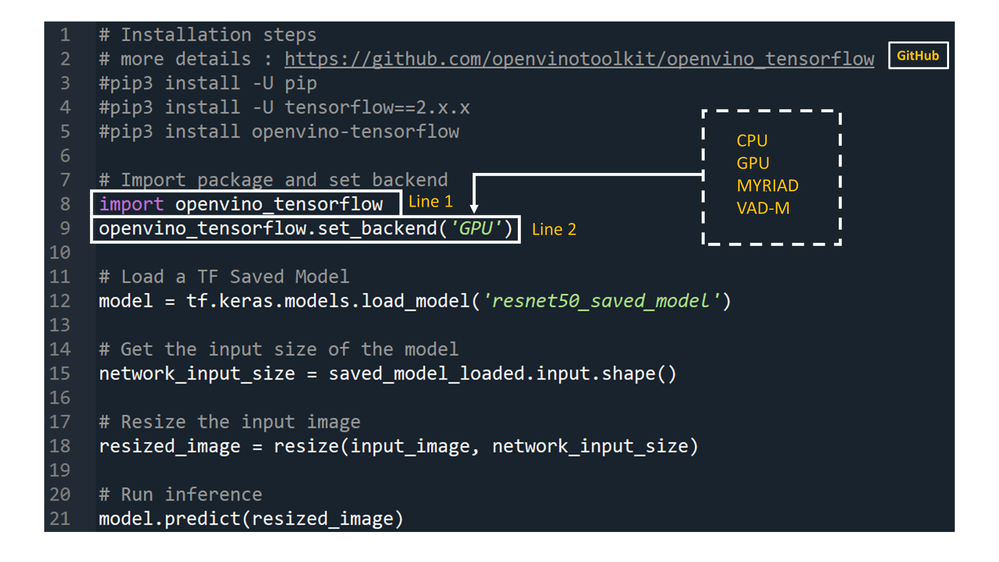
Figure 1
How does it really work under the hood?
OpenVINO™ integration with TensorFlow* provides accelerated TensorFlow performance by efficiently partitioning TensorFlow graphs into multiple subgraphs, which are then dispatched to either the TensorFlow runtime or the OpenVINO™ runtime for optimal accelerated inferencing. The results are finally assembled to provide the final inference results.
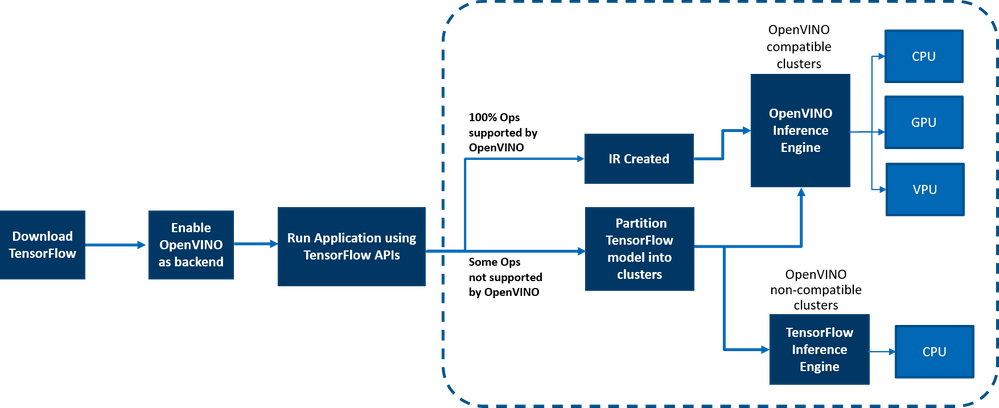
Figure 2: End-to-end overview of the workflow
Here is a detailed architecture diagram.
Deployment at the Edge and the Cloud
OpenVINO™ integration with TensorFlow* works in a variety of environments – from the cloud to the edge – as long as the underlying hardware is an Intel platform. E.g., the add-on works on the following cloud platforms:
- Intel® DevCloud for the Edge
- AWS Deep Learning AMI Ubuntu 18 & Ubuntu 20 on EC2 C5 instances optimized for inferencing
- Azure ML
- Google colab
Any AI based Edge device is supported.
Samples are available in the examples/ directory in the gitrepo.
How is this different from using native OpenVINO™ toolkit:
OpenVINO™ integration with TensorFlow* enables TensorFlow developers to accelerate their TensorFlow model inferencing in a very quick and easy manner – with just 2 lines of code. The OpenVINO™ model optimizer accelerates inference performance, along with a wealth of integrated developer tools and advanced features, but as mentioned earlier, for maximum performance, efficiency, tooling customization, and hardware control, we recommend native OpenVINO™ APIs and its runtime.
Customer adoption
Customers are using OpenVINO™ integration for TensorFlow for a variety of use cases. Here are a few examples
- Extreme Vision: Dedicated AI-only clouds such as Extreme Vision’s CV MART helps enable hundreds of thousands of developers with a rich catalog of services, models, and frameworks to further optimize their AI workloads on a variety of Intel platforms such as CPUs and iGPUs. An easy-to-use developer toolkit to accelerate models, properly integrated with AI frameworks, such as OpenVINO™ integration with TensorFlow*, provides the best of both worlds – an increase in inference speed as well as the ability to reuse already created AI inference code with minimal changes. The Extreme Vision team is testing OpenVINO™ integration with TensorFlow* with the goal of enabling TensorFlow developers on the Extreme Vision platform.
- Genome Analysis Toolkit (GATK) developed by the Broad Institute is one of the world’s most widely used open-source toolkit for variant calling. Terra is a more secure, scalable, open-source platform for biomedical researchers to access data, run analysis tools and collaborate. The cloud-based platform is co-developed by the Broad Institute of MIT and Harvard, Microsoft, and Verily. Terra platform includes GATK tools and pipelines for the research community to run their analytics. CNNScoreVariants is one of the deep learning tools included in GATK which apply a Convolutional Neural Net to filter annotated variants. In a blog, Broad Institute showcase’s how to further accelerate inference performance of CNNScoreVariants using OpenVINO™ integration with TensorFlow*.
Conclusion
Now that you have a better understanding of the benefits, how it works, deployments environments, and how OpenVINO integration with TensorFlow differs from using native OpenVINO APIs, we can’t wait for you to try OpenVINO integration with TensorFlow for yourself and begin experiencing a boost in inference performance of your AI models on all Intel platforms. And as always, we would love to hear your feedback on this integration, please contact us at OpenVINO-tensorflow@intel.com or raise issues in the gitrepo. Thank you!
Resources
Here are resources to help you learn more: