Docker containers can help you deploy deep learning models easily on different devices. With the OpenVINO Execution Provider for ONNX Runtime docker container, you can run deep learning models easily on different Intel® hardware that Intel® Distribution of OpenVINO™ Toolkit supports with the added benefit of not having to install any dependencies. Just in case you haven’t heard about OpenVINO Execution Provider for ONNX Runtime before, the OpenVINO Execution Provider for ONNX Runtime enables ONNX models for running inference using ONNX Runtime API’s while using OpenVINO™ toolkit as a backend.
Now that you know about OpenVINO Execution Provider for ONNX RT, you must be wondering how you can get your hands on it and try it out. In our previous blog, you learned about OpenVINO Execution Provider for ONNX Runtime in depth and tested out some of the object detection samples that we created. Over time, Docker Containers have become essential for AI development and we, at Intel, are aware of that. In the past, many of you have gotten access to OpenVINO Execution Provider for ONNX Runtime docker image through Microsoft’s Container Registry. Now, things are going to be a little different. We are happy to announce that the OpenVINO Execution Provider for ONNX Runtime Docker Image is now LIVE on Docker Hub.
You will still get full access to OpenVINO Execution Provider but going forward keep an eye on Docker Hub as newer versions of the Docker Image will be released there with latest and even better features. With just a simple docker pull, you will be able to accelerate inferencing of ONNX models and get that extra performance boost you’re looking for. To learn more about the latest features that OpenVINO Execution Provider has, you can check out the release notes here. If you want to learn more about how the docker container works and how to use it, please keep reading ahead.
How to Install
Prerequisites
Ubuntu/Cent-OS Linux Machine
Installation
Step 1: Downloading the docker image on the host machine docker pull openvino/onnxruntime_ep_ubuntu18
Step 2: Running the container. docker run -it --rm --device-cgroup-rule='c 189:* rmw' -v /dev/bus/usb:/dev/bus/usb openvino/onnxruntime_ep_ubuntu18:latest
Other ways to install OpenVINO Execution Provider for ONNX Runtime
There are also other ways to install the OpenVINO Execution Provider for ONNX Runtime. One such way is to build from source. By building from source, you will also get access to C++, C# and Python API’s. Another way to install OpenVINO Execution Provider for ONNX Runtime is to install the Python wheel package via pip.
GroundingDINO introduces a language-guided query selection module to enhance object detection using input text. This module selects relevant features from image and text inputs and uses them as decoder queries. In this blog, we provide the OpenVINO™ optimization for GroundingDINO on Intel® platforms.
The public GroundingDINO project is referenced from: GroundingDINO
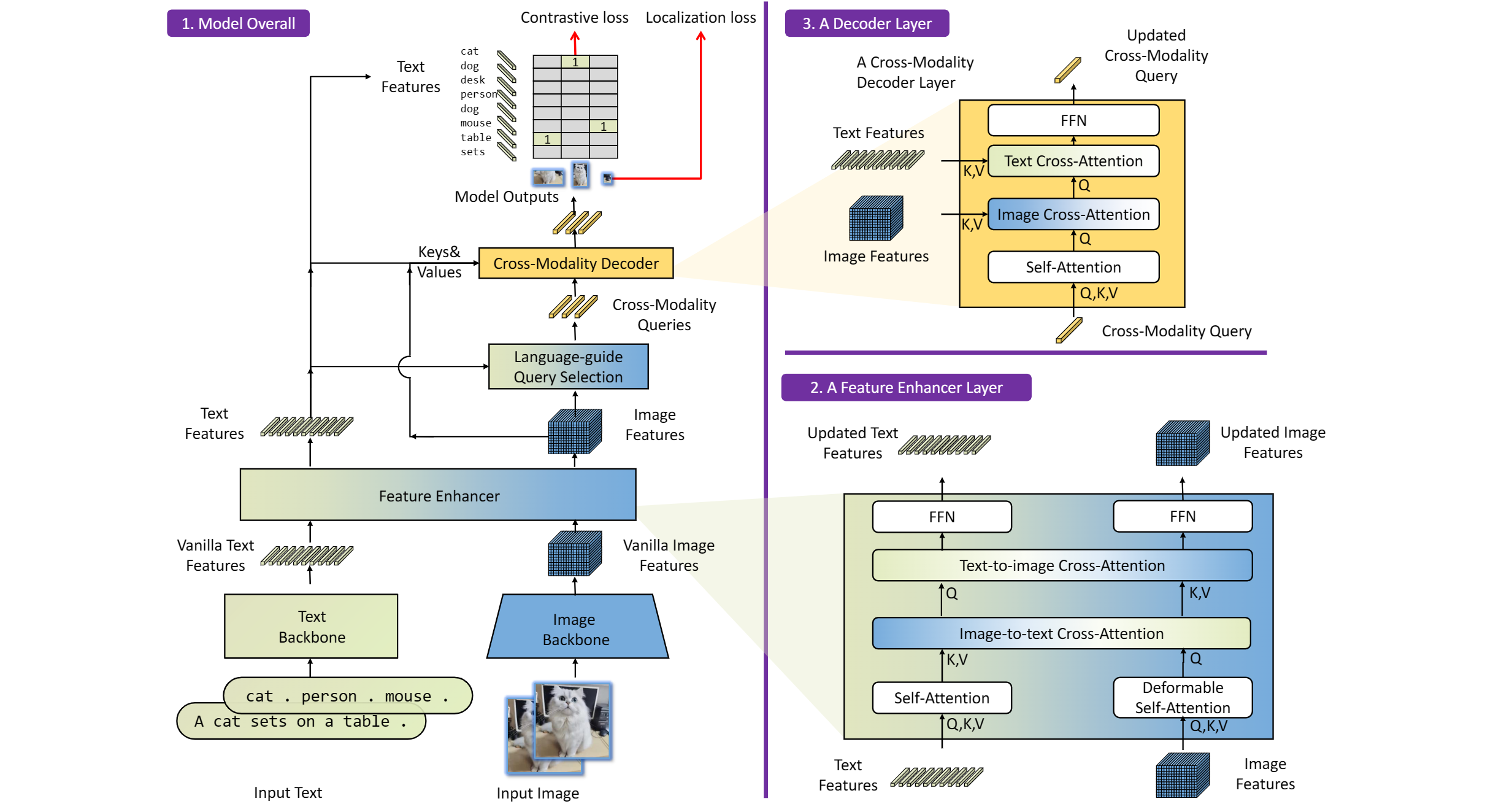
The GroundingDINO refer the model structure in below picture:
Figure 1. The framework of Grounding DINO. We present the overall framework, a feature enhancer layer, and a decoder layer in block 1,block 2, and block 3,respectively.
OpenVINO™ backend on GroundingDINO
In this project, you do not require to download OpenVINO™ and build the library with GroundingDINO project manually. It’s already fully integrated with OpenVINO™ runtime library for downloading, program compiling and linking.
At present, this repository already optimized and validated by OpenVINO™ 2023.1.0.dev20230811 version. Check the operating system which can support OpenVINO™ runtime library directly:
Ubuntu 22.04 long-term support (LTS), 64-bit (Kernel 5.15+)
Ubuntu 20.04 long-term support (LTS), 64-bit (Kernel 5.15+)
Ubuntu 18.04 long-term support (LTS) with limitations, 64-bit (Kernel 5.4+)
Windows* 10
Windows* 11
macOS* 10.15 and above, 64-bit
Red Hat Enterprise Linux* 8, 64-bit
Step 1: Install system dependency and setup environment
Encrypt Your Dataset and Train Your Model with It Directly
Introduction
When we deal with dataset for creating AI models, we need to consider sensitive information managed and stored online in the cloud or on connected devices. Unsecured datasets can be vulnerable to unauthorized access, theft, and misuse, particularly when processed for machine learning workloads. Certain fields, such as industrial or medical sectors, face exceptionally high risks when their data is exposed to these potential threats. For example, if a dataset used to train a detection model for identifying factory process errors is leaked, it can expose sensitive factory process technology. This highlights the importance of safeguarding datasets at every stage, from data storage to model training.
Dataset Management Framework (Datumaro) offers a dataset encryption feature for AI model training. With Datumaro, you can encrypt datasets of any computer vision data format into the DatumaroBinary format. This encrypted dataset can remain encrypted as far as it is needed for decryption. By combining the encrypted dataset with OpenVINO training extensions™, you can use it directly for model training without decryption. Whenever needed, you can use Datumaro once again to decrypt the dataset and convert it back to any major computer vision data format, such as VOC, COCO, or YOLO. Please refer to another posting data_convert for data convert.
Encrypt Your Dataset Using Datumaro
Datumaro provides two ways to encrypt a dataset: CLI and Python API. First, you need to install Datumaro on your system. Please refer to the installation guide here for detailed instructions. Once you have completed the installation of Datumaro, let's first look at the CLI usage. You can encrypt a dataset using the datum convert CLI command as follows:
The necessary user inputs for this command are as follows:
-i <input-dataset-path>: Enter the path to the dataset you want to encrypt in <input-dataset-path>.
-o <output-dataset-path>: Enter the path where the encrypted dataset will be produced in <output-dataset-path>.
NOTE:: (Optional) You can additionally specify the data format of your input dataset by entering the -if <input-dataset-format> argument. In most cases, Datumaro can automatically infer the data format of the input dataset, but it might fail. In such cases, you can use the datum detect --show-rejections <input-dataset-path> command to identify the cause of the failure while inferring the data format.
NOTE:: The --save-media argument is a flag that allows you to convert your media files (e.g., images) as well. If this argument is not provided, the encrypted media will not be included in the output directory and only the encrypted annotations are included in the output directory.
Next, let's take a look at how to encrypt a dataset using the Python API. Please examine the following code snippet:
You import the dataset by specifying the path of the input dataset in the import_from function as path="<input-dataset-path>". Then, to export the dataset, you specify the path of the output dataset in the save_dir="<output-dataset-path>" of the export function. Similarly, you also need to provide the encryption=True and format="datumaro_binary" keyword arguments as in the CLI example. A more detailed end-to-end example for this can be found in a Jupyter notebook. Please refer to this link for more information.
So far, all the examples have used the datumaro_binary (DatumaroBinary) format for the exported dataset. Currently, the dataset encryption feature is only supported for the datumaro_binary format. DatumaroBinary is a Datumaro's own data format that stores annotation data in binary representation. It is much faster and storage efficient compared to string-based datasets such as COCO based on JSON. For more detailed information about DatumaroBinary, please refer to this link.
How Datumaro Encrypts Your Dataset?
Datumaro uses the Fernet symmetric encryption recipe provided by the cryptography library to encrypt the dataset. Fernet is built on top of a number of standard cryptographic primitives such as AES or HMAC, and hence Fernet guarantees that a message encrypted cannot be manipulated or read without the key. Please refer to this link for detailed information.
When encrypting the dataset, Datumaro generates a secret key through Fernet and saves it as a txt file at the following path: <output-dataset-path>/secret_key.txt. The secret key generated at this path is a 50-characters string, which consists of a randomly generated 32-bytes string encoded in base64, with the prefix datum- added.
cat [output-dataset-path]/secret_key.txt
# A secret key will be randomly generated.
datum-IedFogo3TiyVKF2V1-jT2aO-_r3lWHNQoCWvGEyyjKo=
If you have checked the secret key in this file, you must ensure that it is not in the same location with the dataset. If this secret key is uncovered, an attacker would be able to access the contents of the encrypted dataset. Additionally, this secret key is required when training models using OpenVINO training extensions™ with the encrypted dataset or when decrypting it later. Therefore, you should be careful not to lose this secret key.
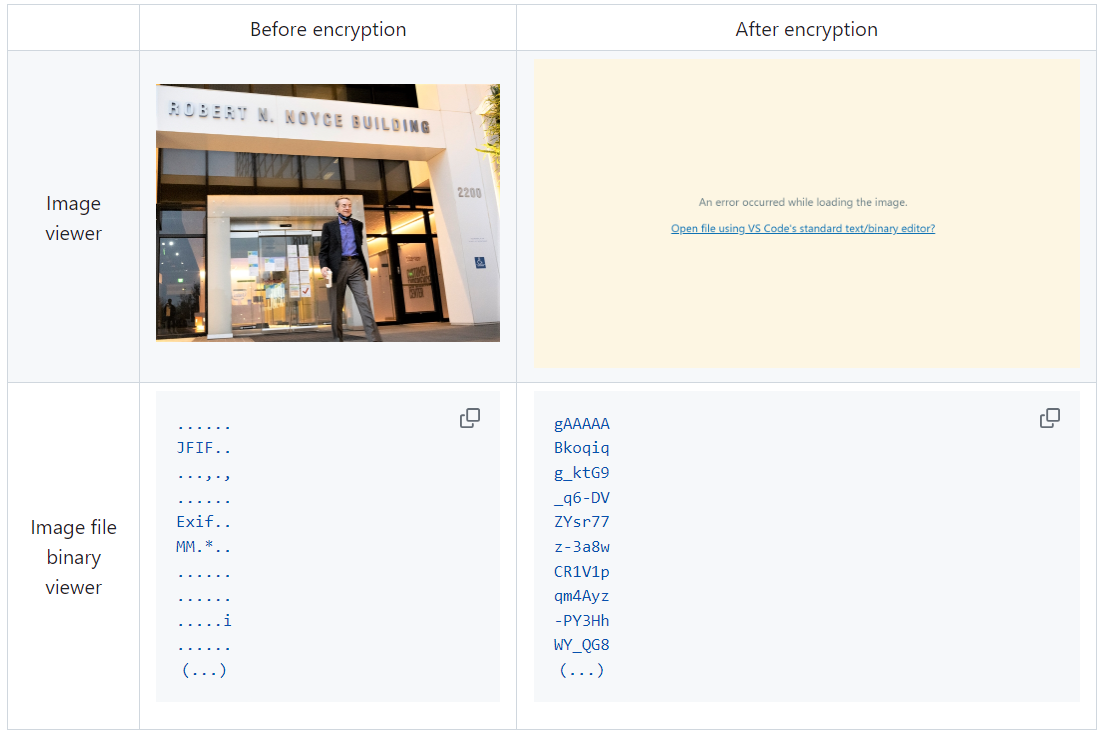
The following table briefly shows how the data is encrypted. The binary representation of the data is encrypted, so that the following image cannot be seen by the image viewer.
Train Your Model with the Encrypted Dataset Using OpenVINO Training Extensions™
OpenVINO training extensions™ is a tool that allows convenient training of computer vision models and accelerated inference on Intel® devices by exporting trained models to OpenVINO Intermediate Representation (IR) through a CLI. Within the OpenVINO ecosystem, Datumaro is integrated with OpenVINO training extensions™ as a dataset interface. Therefore, the encrypted dataset can be directly used for model training through OpenVINO training extensions™. For detailed installation instructions of OpenVINO training extensions™, please refer to the following link.
Next, let's explore how to use the encrypted dataset directly for model training through the CLI command.
The user inputs required for this command are as follows:
--train-data-roots <encrypted-dataset-path> and --val-data-roots <encrypted-dataset-path>: Specify the path to the encrypted dataset by replacing <encrypted-dataset-path>. Since the DatumaroBinary format uses the same root directory for both the training and validation subsets, both arguments should have the same value.
--encryption-key <secret-key>: Provide the secret key corresponding to the encrypted dataset in <secret-key>. This is the 50-character string with the datum- prefix described in the previous section.
NOTE:: <template> is the name of the model template provided by OpenVINO training extensions™. A model template is a recipe for a deep learning model for a specific computer vision task. To explore all the model templates supported by OpenVINO training extensions™, you can use the otx find CLI command or refer to this link.
Decrypt the Encrypted Dataset Using Datumaro
If you want to utilize the encrypted dataset in another AI workload, you need to decrypt the encrypted data. This process reverses the dataset encryption using Datumaro, and encryption-decryption preserves all the information without loss. Similar to the previous section, decryption can be done using the CLI or Python API. Let's first look at decryption using the CLI.
You can use the same datum convert command as before. However, specify the path to the encrypted dataset as the input dataset path (-i <encrypted-dataset-path>), and provide the secret key, which is a 50-character string with the datum- prefix described in the previous section, as the <secret-key> argument for --encryption-key <secret-key>. Additionally, you can choose any data format supported by Datumaro as the output data format. To learn more about the data formats supported by Datumaro, refer to this link.
Next, let's see how decryption can be done using Python API.
Similar to the CLI method, provide the path to the encrypted dataset and the secret key as arguments to the import_from function. For the export function, specify the output dataset path and the output data format.
Conclusion
This post introduced dataset encryption feature provided by Datumaro. It demonstrated how to encrypt a dataset using Datumaro and train a model with the encrypted dataset using OpenVINO training extensions™. Whenever needed you can decrypt it with Datumaro for other AI projects and training frameworks. You can refer to the end-to-end Jupyter notebook example provided on this blog post here for step-by-step guide. The features introduced in this post are available in Datumaro version 1.4.0 or higher and OpenVINO training extensions™ version 1.4.0 or higher.
Datumaro offers a range of useful features for managing datasets besides the dataset encryption feature. You can find examples of other Datumaro features, such as noisy label detection during training with OpenVINO training extensions™, in the Jupyter examples directory. For more information about Datumaro and its capabilities, you can visit the Datumaro documentation page. If you have any questions or requests about using Datumaro, feel free to open an issue here.
Authors: Vinnam Kim, Wonju Lee, Mark Byun, Minje Park
Introduction
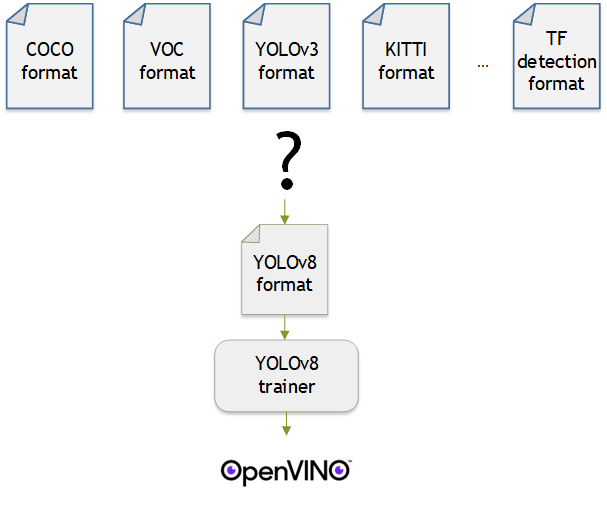
OpenVINO™ provides an easy way to deploy your model with the best inference performance on any Intel hardwares. However, to train your own model for deployment you need to prepare a training framework and dataset. Fortunately, there are many ready-to-use training frameworks and implementations. Then, what about the dataset? A specific training framework requires a specific data format, but there are many data formats in the world. For example, in object detection tasks there are data formats such as YOLO, COCO, and Pascal VOC that are widely used. These formats have different directory structures and annotation file formats as well as different extensions such as txt, json, and, xml, respectively. It's tedious task to convert dataset from one format to another whenever you adopt different training framework.
Let's assume you choose Detectron2, which only supports COCO format datasets. If your dataset is formatted as VOC, you have to convert it into COCO format. Below, we compare the directory structures and annotation file formats of both datasets, VOC and COCO. These datasets have distinct formats and you need to implement codes for format conversion at each time of handling different formats. Of course, this is not technically challenging but this may require tedious code work and debugging for several days. It won't be good to repeat this process if you intend to add more datasets with different formats.
Dataset Management Framework (Datumaro) is a framework that provides Python API and CLI tools to convert, transform, and analyze datasets. Among the many features of Datumaro, we would like to introduce the data format conversion feature on this blog, which is one of the fundamental feature for handling many datasets with different training frameworks. Datumaro supports the import and export of over 40 computer vision data formats (please take a look at supported formats for details!). This means that you can easily change your data format through Datumaro. If your model training framework can only read specific formats, don't worry. Use Datumaro and convert it!
Train YOLOv8 model and export it to OpenVINO™ model
Prepare dataset
Convert dataset with Datumaro
Train with YOLOv8 and export to OpenVINO™ IR
YOLOv8 is a well-known model training framework for object detection and tracking, instance segmentation, image classification, and pose estimation tasks. It provides simple CLI commands to train, test, and export a model to OpenVINO™ Intermediate Representation (IR). However, the data format consumed by YOLOv8 is slightly different from the YOLO format itself. Datumaro named it refers to it as YOLO-Ultralytics format. As you can see here, it requires a special meta file to indicate annotation files for each subset and subset files to list subset image files. It further requires them to be placed in an appropriate directory structure. It can be very tedious to go through these details and implement dataset preprocessing when you want to train a model on your custom dataset.
On this blog, we provide an end-to-end example that covers the complete process of converting your dataset, training a model with the converted dataset, and exporting the trained model to OpenVINO™ IR. We understand that dataset conversion can be a tricky process, especially if you have annotated and built your own dataset. Therefore, we will provide an example of converting the dataset created by the popular CVAT annotation tool. By following our step-by-step guide, you will be able to convert your data format easily and accelerate the inference of your trained model with OpenVINO™.
Prepare dataset
In this section, we introduce the steps to export the project annotated by CVAT for the following workflows. You can skip this section if your dataset is formatted as a different data format and is ready to be imported by Datumaro.
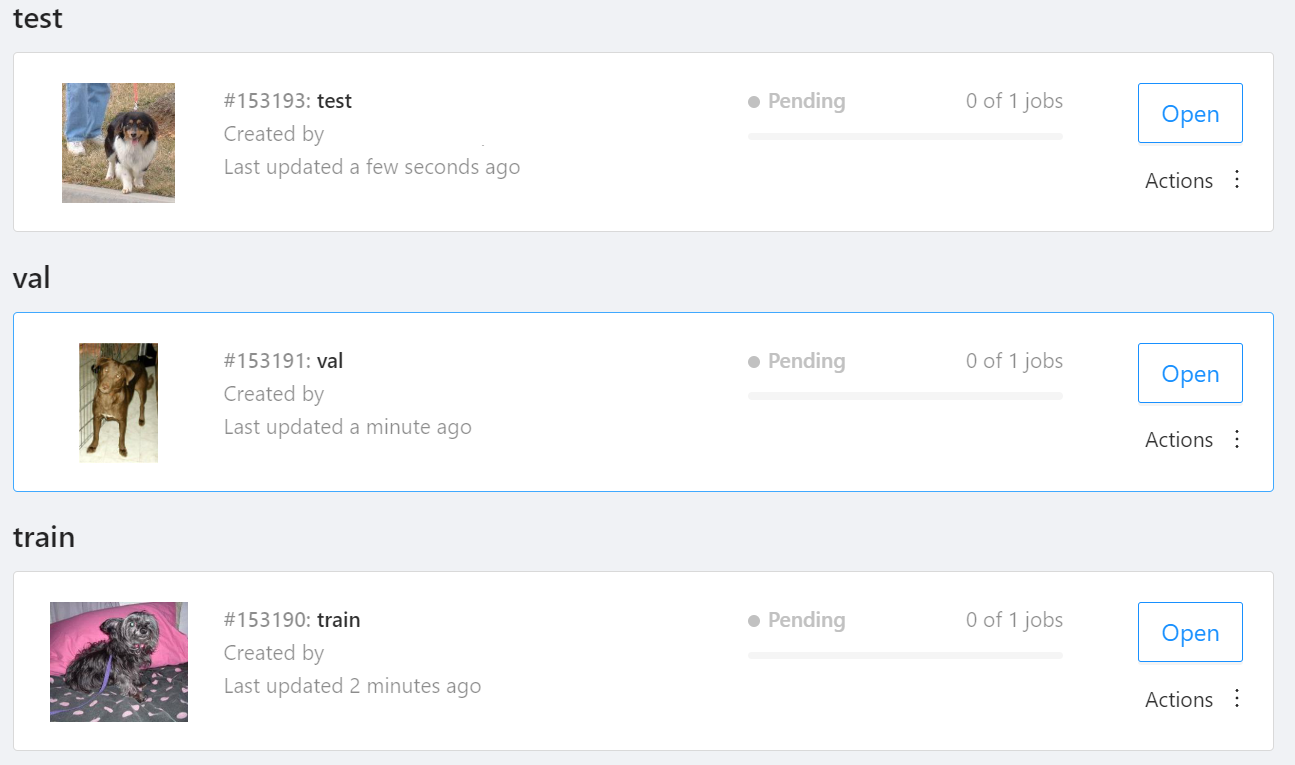
CVAT project for object detection task with train, val, and test subsets
NOTE: We used the cats-and-dogs dataset for this example. You can find the reference for this dataset here.
NOTE: You should have three subsets in your project: "train", "val", and "test" (optional). If your dataset has different subset names, you have to rename them. You can do this by using Datumaro's MapSubsets transform.
We export this project to CVAT for images 1.1 data format. Datumaro can import this data format and export it to YOLO-Ultralytics format which can be consumed by YOLOv8.
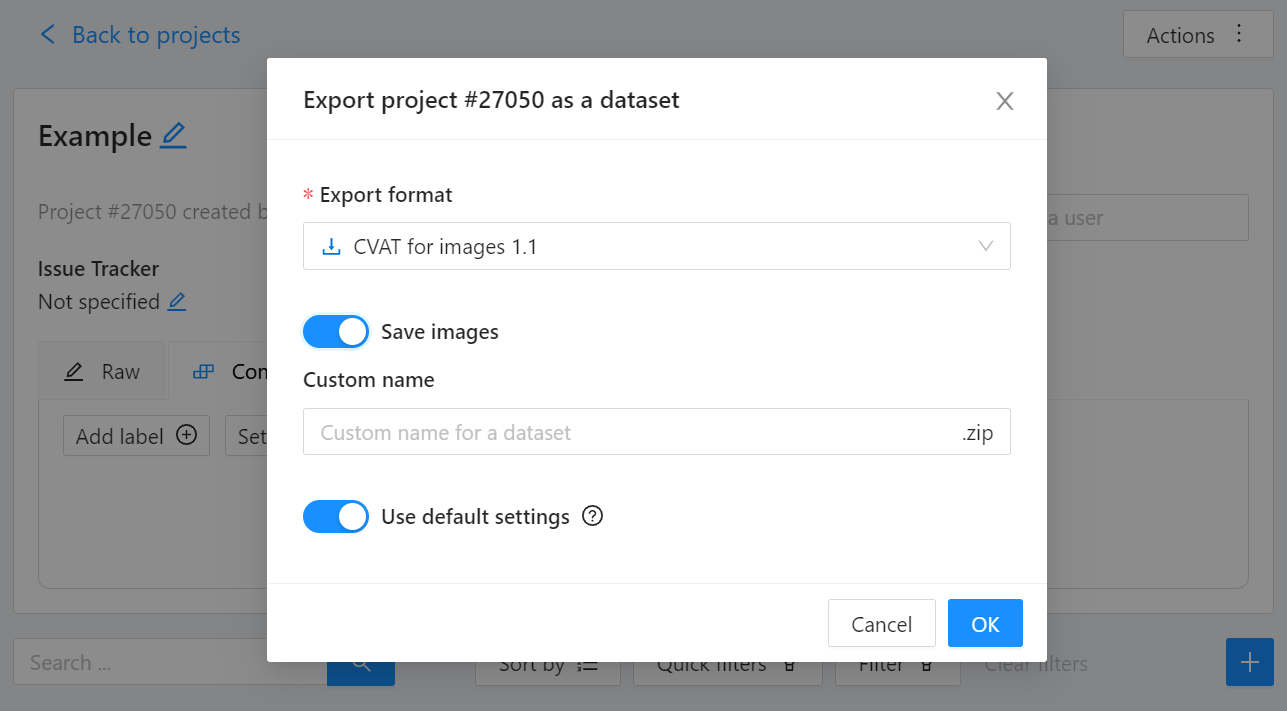
Export CVAT project to CVAT for images 1.1 data format
Export CVAT project to CVAT for images 1.1 data format. After exporting the dataset, extract it to the cvat_dataset directory.
ls yolo_v8_dataset
You can see the following directory structure:
annotations.xml images
Convert your dataset using Datumaro
You can convert the dataset located in cvat_dataset using Datumaro's CLI command as follows. For a detailed explanation of the input arguments, see here.
NOTE: If your dataset is not CVAT for images 1.1 format, you can replace -if cvat with the different input format as -if INPUT_FORMAT. Use datum detect CLI command to figure out what format your dataset is.
After the conversion, you can see that yolo_v8_dataset directory is created.
Train with YOLOv8 Trainer and Export to OpenVINO™ IR
In this section, we will train the YOLOv8 detector with the dataset converted in the previous section. To train a YOLOv8 detector, please execute the following command.
NOTE: We use data=$(realpath yolo_v8_dataset/data.yaml) to convert the relative path yolo_v8_dataset/data.yaml to the absolute path. This is because YOLOv8 needs the absolute path for the custom dataset.
After the training, the following command enables testing on the test dataset.
yolo detect val model=my-project/train/weights/best.pt data=$(realpath yolo_v8_dataset/data.yaml) split=test
Lastly, we will export your YOLOv8 detector to OpenVINO™ IR for inference acceleration on Intel devices.
Using this command, the exported IR is created at this directory path, my-project/train/weights/best_openvino_model.
ls my-project/train/weights/best_openvino_model
best.bin best.xml metadata.yaml
Conclusion
This post provided an example of training a YOLOv8 detector on an arbitrary data format by utilizing the data format conversion feature of Datumaro and exporting the model to OpenVINO™ IR. You can refer to the executable Jupyter notebook example provided on this blog post here for step-by-step guide. Datumaro offers a range of useful features for managing datasets beyond data format conversion. You can find examples of other Datumaro features, such as noisy label detection during training with OpenVINO™ Training Extensions, in the Jupyter examples directory. For more information about Datumaro and its capabilities, you can visit the Datumaro documentation page. If you have any questions or requests about using Datumaro, feel free to open an issue here.


.png)