For OpenVINO™ 2022.1 on CentOS 7.6, we provide the dockerfile based on the docker_ci and usage instructions in this blog.
At present, OpenVINO™ officially only provides a docker image of OpenVINO™ 2021.3 for CentOS 7 on DockerHub. To deploy a docker image with the OpenVINO™ toolkit, OpenVINO™ provides the DockerHub CI named docker_ci. However, docker_ci doesn’t support CentOS 7.
Here are the steps to build the OpenVINO™ 2022.1.0 Docker Image on CentOS 7.6 with Python 3.6. In this instruction, we use Python 3.6 in the docker image as an example. If upgrading the version, the user needs to solve problems with yum and related tools.
Setup of OpenVINO™
0. Build OpenVINO™ 2022.1.0 with CMake 3.18.4 and GCC 8.3.1
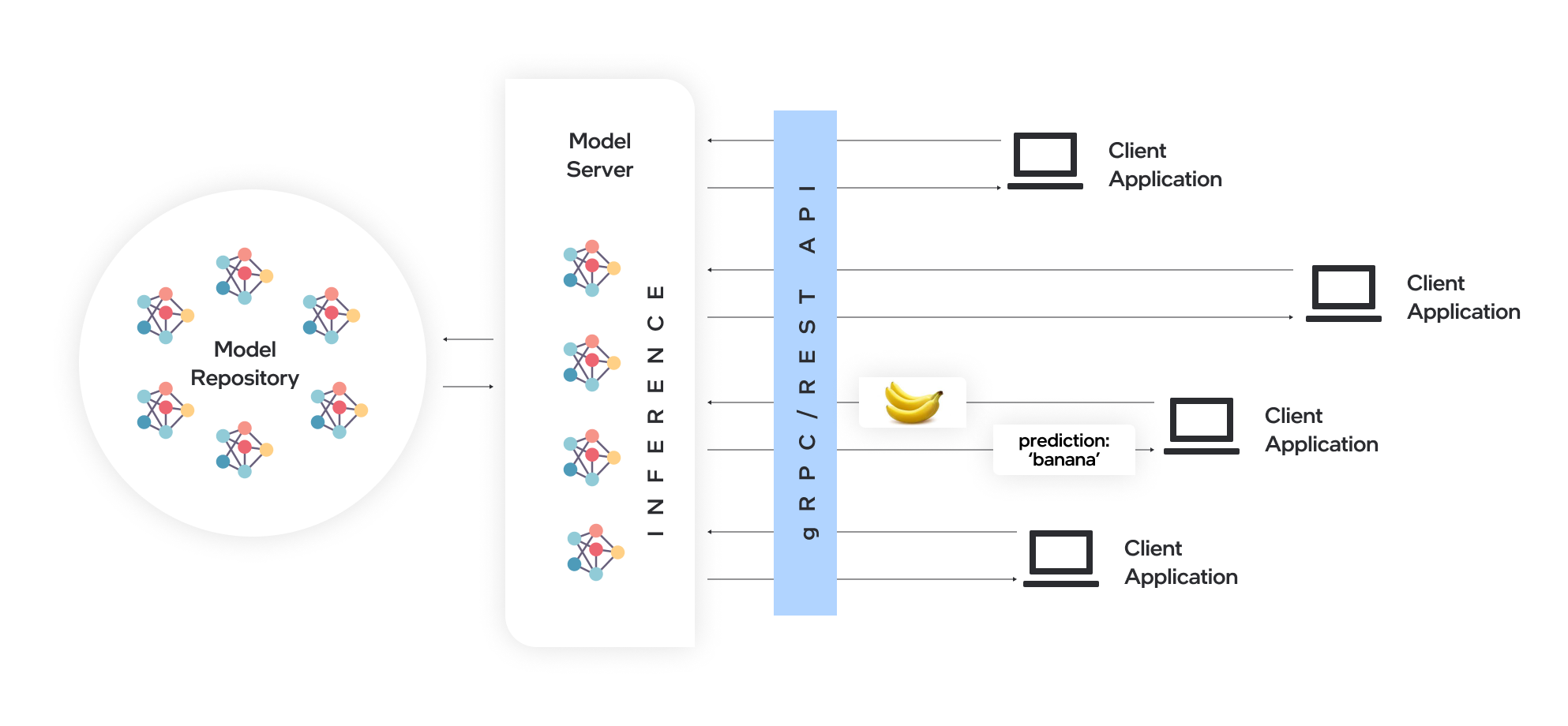
OpenVINO™ Model Server (OVMS) is a high-performance system for serving models. Implemented in C++ for scalability and optimized for deployment on Intel® architectures, the model server uses the same architecture and API as TensorFlow Serving and KServe while applying OpenVINO™ for inference execution. Inference service is provided via gRPC or REST API, making deploying new algorithms and AI experiments easy.
Docker is the recommended way to deploy OpenVINO™ Model Server. Pre-built container images are available on Docker Hub and Red Hat Ecosystem Catalog.
In this blog, we will introduce how to leverage OpenVINO™ Model Server to deploy AI workload across various hardware platforms, including Intel® CPU, Intel® GPU, and Nvidia GPU.
2. OpenVINO™ Model Server Pre-built Docker Image for Intel® CPU
Pull the latest pre-built OVMS docker image hosted in Docker Hub:
docker pull openvino/model_server:latest
Verify OVMS docker image and OpenVINO™ backend version:
docker run -it openvino/model_server:latest --version
Here is an example output of the command line above:
Figure 2. Example output of OVMS and OpenVINO™ backend version
Download a model and create an appropriate directory structure. For example, a person-vehicle-bike-detection model from Intel’s Open Model Zoo:
export MODEL_DIR=$PWD
mkdir -p workspace/person-vehicle-bike-detection-2000/1
cd workspace/person-vehicle-bike-detection-2000/1
wget https://storage.openvinotoolkit.org/repositories/open_model_zoo/2022.3/models_bin/1/person-vehicle-bike-detection-2000/FP32/person-vehicle-bike-detection-2000.xml
wget https://storage.openvinotoolkit.org/repositories/open_model_zoo/2022.3/models_bin/1/person-vehicle-bike-detection-2000/FP32/person-vehicle-bike-detection-2000.bin
cd $MODEL_DIR
where a model directory structure looks like that:
Figure 3. Example of model directory structure for OVMS
After the model repository preparation, let’s start OVMS to host a person-vehicle-bike-detection-2000 model in the Model Server with Intel® CPU as target device.
The parameter “--target_device CPU” specified workload to allocate on Intel® CPU. “--port 30001” set up the gRPC server port as 30001, and “--rest_port 30001” set up the REST server port as 30002. The parameter “--model_path” specified the model directory path in the docker image, while “--model_name” specified which model to host in the model server.
3. Build OpenVINO™ Model Server Benchmark Client
OpenVINO™ Model Server provides a useful tool - Benchmark Client to generate traffic and measure the performance of the model served in OpenVINO™ Model Server. In this blog, you could use Benchmark Client to verify OpenVINO™ model server functionality quickly.
To build the docker image and tag it as benchmark_client as follow:
git clone https://github.com/openvinotoolkit/model_server.git
cd model_server/demos/benchmark/python
docker build . -t benchmark_client
Here is an example to use benchmark_client to generate 8 requests and send them via gRPC API, then receive the severed model performance data:
docker run --network host benchmark_client -a localhost -r 30002 \
-m person-vehicle-bike-detection-2000 -p 30001 -n 8 --report_warmup --print_all
In the output, "window_netto_frame_rate" measures the overall performance of a service - how many frames per second the model server processed. Please note, model serving example above was set up with default parameters, see the performance tuning section for more details.
4. Build OpenVINO™ Model Server from Source Code
Download the model server source code as follows:
git clone https://github.com/openvinotoolkit/model_server.git
cd model_server
OVMS provides a “Makefile” to build the docker image with environment parameters, which you can pass via the command line for the building process.
BASE_OS: base OS docker image used to build OVMS docker image, current supported values are “ubuntu” (by default) and “redhat”.
OV_USE_BINARY: control whether to use a pre-built OpenVINO™ binary package for building OVMS docker image. If "OV_USE_BINARY=1", OVMS use a pre-built OpenVINO™ binary package. If "OV_USE_BINARY=0", OpenVINO™ will be built from source code during OVMS building process.
DLDT_PACKAGE_URL: If "OV_USE_BINRAY=1", "DLDT_PACKAGE_URL" is used to set the URL path to the pre-built OpenVINO™ binary package
GPU: control whether to enable OVMS support for Intel® GPU. By default, “GPU=0” disables OVMS support for Intel® GPU. If "GPU=1", OVMS support for intel® GPU will be enabled.
NVIDIA: control whether to enable OVMS support for Nvidia GPU. By default, "NVIDIA=0" disables OVMS support for Nvidia GPU. If "NVIDIA=1", OVMS support for Nvidia GPU will be enabled, which requires building OpenVINO from the source code.
OV_SOURCE_BRANCH: If "OV_USE_BINARY=0", "OV_SOURCE_BRANCH" is used to set the target branch or commit hash of OpenVINO source code. The default value is “master”
OV_CONTRIB_BRANCH: If "NVIDIA=1", "OV_CONTRIB_BRANCH" is used to set the target branch or commit hash of OpenVINO contrib source code. The default value is “master"
Here is an example of building OVMS with the "releases/2022/3" branch of OpenVINO™ GitHub source code with target device Intel® CPU.
OV_USE_BINARY=0 OV_SOURCE_BRANCH=releases/2022/3 make docker_build
Built docker image will be available in the host as “openvino/model_server:latest”.
5. Build OpenVINO™ Model Server with Intel® GPU Support
Since OpenVINO™ 2022.3 release, OpenVINO™ added full support for Intel’s integrated GPU, Intel’s discrete graphics cards, such as Intel® Data Center GPU Flex Series, and Intel® Arc™ GPU for DL inferencing workloads in the intelligent cloud, edge, and media analytics workloads. OpenVINO™ Model Server 2022.3 also added support for Intel® GPU. The pre-built OpenVINO™ Model Server docker image with GPU driver for Intel® GPU is available in Docker Hub:
docker pull openvino/model_server:latest-gpu
Here is an example of building OVMS with Intel® GPU support based on the OpenVINO™ source code:
GPU=1 OV_USE_BINARY=0 OV_SOURCE_BRANCH=releases/2022/3 make docker_build
The default GPU driver (version 22.8 for RedHat 8.7 or version 22.35 for Ubuntu 20.04) will be installed during the building process. Built docker image will be available in the host as “openvino/model_server:latest-gpu”.
Here is an example to launch the OVMS docker image with Intel® GPU as target device:
The parameter “--target_device GPU” specified workload to allocate on Intel® GPU. The parameter “--device /dev/dri” is used to pass the device context. The parameter “--group-add=$(stat -c"%g" /dev/dri/render\* | head -n 1) -u $(id -u):$(id -g)” is used to ensure the model server process security context account with correct permissions to run inference on Intel® GPU.
Here is an example to verify the severed model performance on Intel® GPU with benchmark_client:
docker run --network host benchmark_client -a localhost -r 30002 \
-m person-vehicle-bike-detection-2000 -p 30001 -n 8 --report_warmup --print_all
6. Build OpenVINO™ Model Server with Nvidia GPU Support
OpenVINO™ Model Server can also support Nvidia GPU cards by using NVIDIA plugin from the GitHub repo openvino_contrib. Here is an example of building OVMS with Nvidia GPU support step by step:
First, pull the Nvidia docker base image with the GPU driver, e.g.,“docker.io/nvidia/cuda:11.8.0-runtime-ubuntu20.04”, please ensure to install same GPU driver version in the local host environment.
Build OVMS docker image with Nvidia GPU support.“NVIDIA=1” enables to build OVMS with Nvidia GPU support, and “OV_USE_BINARY=0” enables building OpenVINO from the source code. Besides, “OV_SOURCE_BRANCH=releases/2022/3” refer to the OpenVINO™ GitHub "releases/2022/3" branch, while “OV_CONTRIB_BRANCH=releases/2022/3” refer to the OpenVINO contrib GitHub "releases/2022/3" branch.
NVIDIA=1 OV_USE_BINARY=0 OV_SOURCE_BRANCH=releases/2022/3 \
OV_CONTRIB_BRANCH=releases/2022/3 make docker_build
Built docker image will be available in the host as “openvino/model_server-cuda:latest”.
Here is an example to launch the OVMS docker image with Nvidia GPU as target device:
The parameter “--target_device NVIDIA” is specified to allocate workload on NVIDIA GPU. The parameter “--gpu all” flag is used to access all GPU resources available in the host system.
Here is an example to verify the severed model performance on Nvidia GPU with benchmark_client:
docker run --network host benchmark_client -a localhost -r 30002 \
-m person-vehicle-bike-detection-2000 -p 30001 -n 8 --report_warmup --print_all
7. Migration from Triton Inference Server to OpenVINO™ Model Server
KServe, as a robust and extensible cloud-native model server for Kubernetes, is widely adopted by model servers including Triton Inference Server. Since the 2022.3 release, OpenVINO™ Model Server added KServer API that supports REST and gRPC calls. Therefore, OVMS with Nvidia GPU support is fully compatible to receive requests from Triton Inference Client and run inference on Nvidia GPU.
Here is an example to pull the Triton Inference Server docker image:
docker run -it --rm --net=host nvcr.io/nvidia/tritonserver:22.10-py3-sdk
Then you could use perf_client tools in the docker image to send generated workload as requests to OVMS via KServe API with gRPC port, then receive measured performance data on Nvidia GPU.
The simple example above shows how smoothly developers can migrate their own AI service workload from Triton Inference Server to OpenVINO™ Model Server without any change from the client.
In this blog is about How to use DL-streamer to build a complete Media-AI pipeline (Including: Video Access, Media Decode, AI Inference, Media Encode and Result Export). And the pipeline will be accelerated by OpenVINO™ and optimize to run on Flex dGPU(Intel® Data Center Flex dGPU)
Requirement
- DL-streamer Intel® Deep Learning Streamer (Intel® DL Streamer)Pipeline Framework is an easy way to construct media analytics pipelines using Intel® Distribution of OpenVINO™ Toolkit. It leverages the open source media framework GStreamer to provide optimized media operations and Deep Learning Inference Engine from OpenVINO™ Toolkit to provide optimized inference.
- OpenVINO OpenVINO™ is an open-source toolkit for optimizing and deploying AI inference which can boost deep learning performance in computer vision, automatic speech recognition, natural language processing and other common task.
- Docker (Optional) Docker is an open-source platform that enables developers to build, deploy, run, update, and manage containers—standardized, executable components that combine application source code with the operating system (OS) libraries and dependencies required to run that code in any environment.
Install DL-Streamer and OpenVINO™ via Docker
Images for Intel® Data Center GPU Flex Series
Images 2023.0.0-ubuntu22-gpu682* are intended for Intel® Data Center GPU Flex Series and include
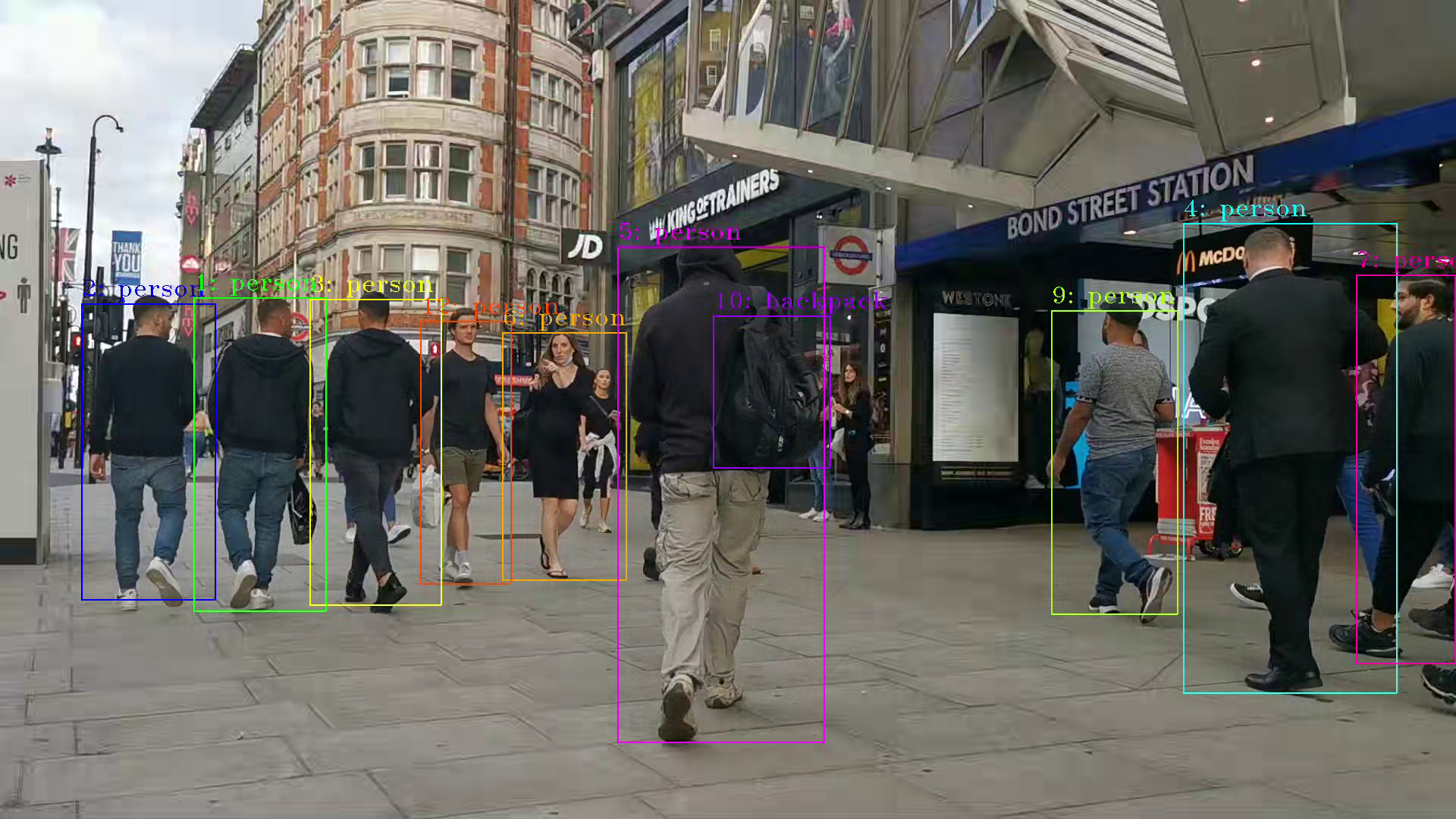
Make sure the pre-requirement had already installed, there is a very basic introduction to using object detection models(yolov5) to build a DL-streamer pipeline.
decodebin: Auto-magically constructs a decoding pipeline using available decoders and demuxers via auto-plugging.
vaapipostproc: Consists in various post processing algorithms to be applied to VA surfaces. For e.g. scaling, deinterlacing (bob, motion-adaptive, motion-compensated), noise reduction or sharpening.
gvadetect: Performs object detection on a full-frame or region of interest (ROI) using object detection models such as YOLO v3-v5, MobileNet-SSD, Faster-RCNN etc. Outputs the ROI for detected objects.
gvatrack: Performs object tracking using zero-term, zero-term-imageless, or short-term-imageless tracking algorithms. Zero-term tracking assigns unique object IDs and requires object detection to run on every frame. Short-term tracking allows to track objects between frames, there by reducing the need to run object detection on each frame. Imageless tracking forms object associations based on the movement and shape of objects, and it does not use image data.
gvafpscounter: Measures frames per second across multiple streams in a single process.
Tuning Tips
Users can refer the different platform using case which were supported by OpenVINO™ and the device profiling API to realize performance tuning of your inference program between CPU, iGPU, dGPU. It will also be helpful to developer finding out the place where has the potential space of performance improvement.
We provide a script to help users easily install and test OpenVINO™ on CentOS 7.6. This script is a practice and supplement to the Building OpenVINO™ on CentOS 7 Guide in the OpenVINO™ wiki. The installation of OpenVINO™ 2022.1.0 and 2022.2.0 has been verified under the following eight configurations of CentOS 7.6 (GCC:7.3.1, 8.3.1 and Python: 3.6,3.7, 3.8, 3.9). The script could also be used for the newer version of OpenVINO with some modifications in the future.
CentOS 7 is an open-source server operating system released by the CentOS project. It was officially released on July 7, 2014. CentOS 7 is an enterprise-level Linux distribution, which is redistributed from the free and open-source code of RedHat, and its stability is trustworthy. The CentOS community and RedHat have announced that CentOS 8 will end on December 31, 2021, and CentOS 7 will end on June 30, 2024. Therefore, CentOS 7 is still the mainstream operating system of most cloud platforms.
However, CentOS 7 default GCC 4.8.5 and CMake 2.8.12 does not meet the OpenVINO software requirement for building on a Linux system. Since OpenVINO™ release 2022.1, the binary and python wheel installation packages will not be provided on CentOS 7. To help users with the verification and integration of the OpenVINO™ new version, Here we provide the installation guide and script.
The environment configuration and dependency library download time are dependent on the network environment and will not be downloaded repeatedly. Compile time depends on the hardware. Every time the script is run, the user needs clean up the previous compilation-related folders (install, build, temp) and recompile.
4.Hints:
Usage: [-g <7 or 8>] [-p <6, 7, 8 or9>] [-c <Cmake Dir>] [-m <evaluation model>] [-b benchmark_app C++ <true or false>]
Contents
The script steps are similar to the Building OpenVINO™ on CentOS 7 Guide. Here are the contents with some comments. For details, please refer to the script and wiki guide.
0. Install system dependencies setup on CentOS 7.6 and install Anaconda
To test more Python version, we use Anaconda instead of Miniconda. Anaconda silent installation is recommended to avoid manually agreeing to the certificate and restarting bash (the script part is as shown below).
1. Download CMake
Download the pre-built CMake 3.18.4 and add environment variables: no need to change the existing CMake version of the system and no need to compile.
2. Install devtoolset and setup environment
Because CentOS7 was released too early, the default GCC version is 4.8.5, which does not support the compilation of OpenVINO™. Using devtoolset can install a higher version of GCC without changing the system GCC version.
The library Wheel is one of Python dependencies. Wheel 0.37.1 is recommended for OpenVINO 2022.1.0 and 2022.2.0. The higher version of Wheel is not suitable.
3. Build OV with CMake
Create a Python environment with conda and check the name of Python library and header folder.
Install the two generated wheels.(runtime and development tool)
5.Model evaluation with benchmark_app and OpenVINO™ CLI usage
Install the specified version of dependencies, forONNX 1.12 not support python3.6.
pip install protobuf==3.16.0 onnx==1.11.0
Quickly download and convert models from OpenVINO™ Toolkit - Open Model Zoo repository.
C++/Python benchmark_app: The C++ version requires additional compilation, with the Python version by default.
In the end, the script will show the OpenVINO™ usage example as below.
##################################################
Congratulation! centos7-install-guide is finished.
###################################################
Here is an OV usage example on centos7:
source /opt/rh/devtoolset-8/enable
export PATH="~/anaconda3/bin:$PATH"
conda activate py37
benchmark_app -m ~/ov_models/public/resnet-50-pytorch/FP32/resnet-50-pytorch.xml -d CPU
###################################################

.png)