
.png)
Fiona
Zhao
Enable chatGLM by creating OpenVINO™ stateful model and runtime pipeline
Authors: Zhen Zhao(Fiona), Cheng Luo, Tingqian Li, Wenyi Zou
Introduction
Since the Large Language Models (LLMs) become the hot topic, a lot Chinese language models have been developed and actively deployed in optimization platforms. chatGLM is one of the popular Chinese LLMs which are widely been evaluated. However, ChatGLM model is not yet a native model in Transformers, which means there remains support gap in official optimum. In this blog, we provide a quick workaround to re-construct the model structure by OpenVINO™ opset contains custom optimized nodes for chatGLM specifically and these nodes has been highly optimized by AMX intrinsic and MHA fusion.
*Please note, this blog only introduces a workaround of optimization method by creating OpenVINO™ stateful model for chatGLM. This workaround has limitation of platform, which requires to use Intel® 4th Xeon Sapphire Rapids with AMX optimization. We do not promise the maintenance of this workaround.
Source link: https://github.com/luo-cheng2021/openvino/tree/luocheng/chatglm_custom/tools/gpt
To support more LLMs, including llama, chatglm2, gpt-neox/dolly, gpt-j and falcon. You can refer this link which not limited on SPR platform, also can compute from Core to Xeon:
Source link: https://github.com/luo-cheng2021/ov.cpu.llm.experimental
ChatGLM model brief
If we check with original model source of chatGLM, we can find that the ChatGLM is not compatible with Optimum ModelForCasualML, it defines the new class ChatGLMForConditionalGeneration. This model has 3 main modules (embedding, GLMBlock layers and lm_logits) during the pipeline loop, the structure is like below:
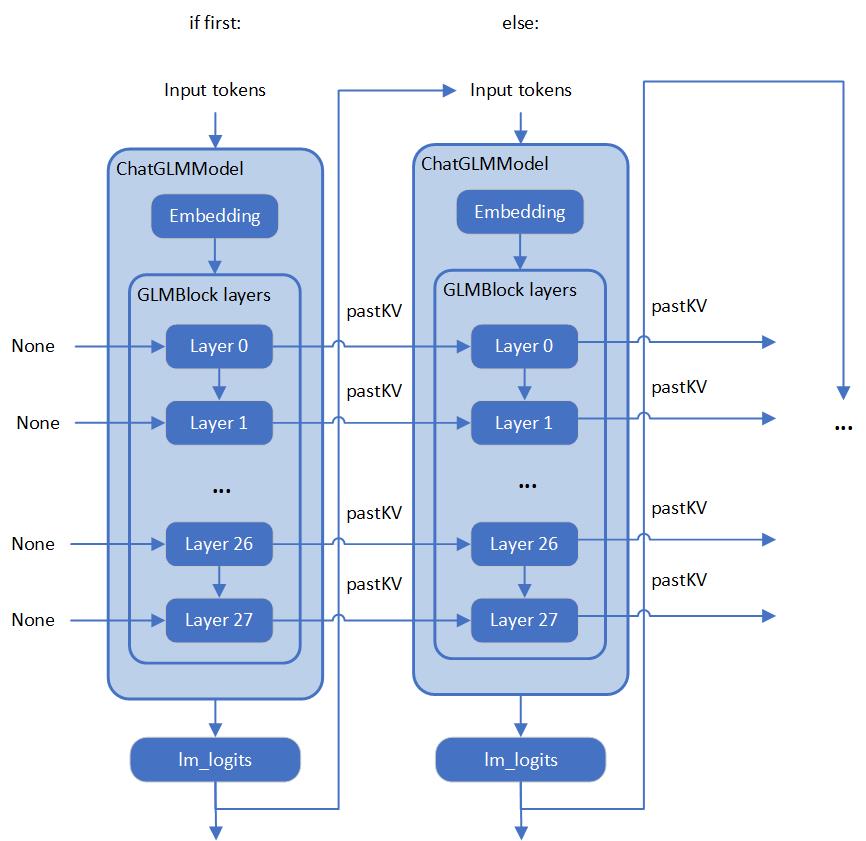
As you can see, the whole pipeline actually require model with two different graphs, the first-time inference with input prompt tokens do not require KV cache as inputs for GLMBlock layers. Since the second iteration, the previous results of QKV Attention should become the inputs of current round model inference. Along with the length of generated token increased, there will remain a lot of large sized memory copies between model inputs and outputs during pipeline inference. We can use ChatGLM6b default model configurations as an example, the memory copies between input and output arrays are like below pseudocode:
Therefore, two topics is the most important:
- How we can optimize model inference pipeline to eliminate memory copy between model inputs and outputs
- How we can put optimization efforts on GLMBlock module by reinvent execution graph
Extremely optimization by OpenVINO™ stateful model
Firstly, we need to analyze the structure of GLMBlock layer, and try to encapsulate a class to invoke OpenVINO™ opset with below workflow. Then serialize the graph to IR model(.xml, .bin).

To build an OpenVINO™ stateful model, you can refer to this document to learn.
https://docs.openvino.ai/2022.3/openvino_docs_OV_UG_network_state_intro.html
OpenVINO™ also provide model creation sample to show how to build a model by opset.
https://github.com/openvinotoolkit/openvino/blob/master/samples/cpp/model_creation_sample/main.cpp
It is clear to show that the emphasized optimization block is the custom op of Attention for chatGLM. The main idea is to build up a global context to store and update pastKV results internally, and then use intrinsic optimization for Rotary Embedding and Multi-Head Attentions. In this blog, we provide an optimized the attention structure of chatGLM with AMX intrinsic operators.
At the same time, we use int8 to compress the weights of the Fully Connected layer, you are not required to compress the model by Post Training Quantization (PTQ) or process with framework for Quantization Aware Training(QAT).
Create OpenVINO™ stateful model for chatGLM
Please prepare your hardware and software environment like below and follow the steps to optimize the chatGLM:
Hardware requirements
Intel® 4th Xeon platform(codename Sapphire Rapids) and above
Software Validation Environment
Ubuntu 22.04.1 LTS
python 3.10.11 for OpenVINO™ Runtime Python API
GCC 11.3.0 to build OpenVINO™ Runtime
cmake 3.26.4
Building OpenVINO™ Source
- Install system dependency and setup environment
- Create and enable python virtual environment
- Install python dependency
- Build OpenVINO™ with GCC 11.3.0
- Clone OpenVINO™ and update submodule
- Install python dependency for building python wheels
- Create build directory
- Build OpenVINO™ with CMake
- Install built python wheel for OpenVINO™ runtime and openvino-dev tools
- Check system gcc version and conda runtime gcc version. If the system gcc version is higher than conda gcc version like below, you should update conda gcc version for OpenVINO runtime. (Optional)
- convert pytorch model to OpenVINO™ IR
Use OpenVINO Runtime API to build Inference pipeline for chatGLM
We provide a demo by using transformers and OpenVINO™ runtime API to build the inference pipeline. In test_chatglm.py, we create a new class which inherit from transformers.PreTrainedModel. And we update the forward function by build up model inference pipeline with OpenVINO™ runtime Python API. Other member functions are migrated from ChatGLMForConditionalGeneration from modeling_chatglm.py, so that, we can make sure the input preparation work, set_random_seed, tokenizer/detokenizer and left pipelined operation can be totally same as original model source.
To enable the int8 weights compress, you just need a simple environment variable USE_INT8_WEIGHT=1. That is because during the model generation, we use int8 to compress the weights of the Fully Connected layer, and then it can use int8 weights to inference on runtime, you are not required to compress the model by framework or quantization tools.
Please follow below steps to test the chatGLM with OpenVINO™ runtime pipeline:
- Run bf16 model
- Run int8 model
Weights compression reduces memory bandwidth utilization to improve inference speed
We use VTune for performance comparison analysis of model weights bf16 and int8. Comparative analysis of memory bandwidth and CPI rate (Table 1). When model weight is compressed to int8, it can reduce memory bandwidth utilization and CPI rate.
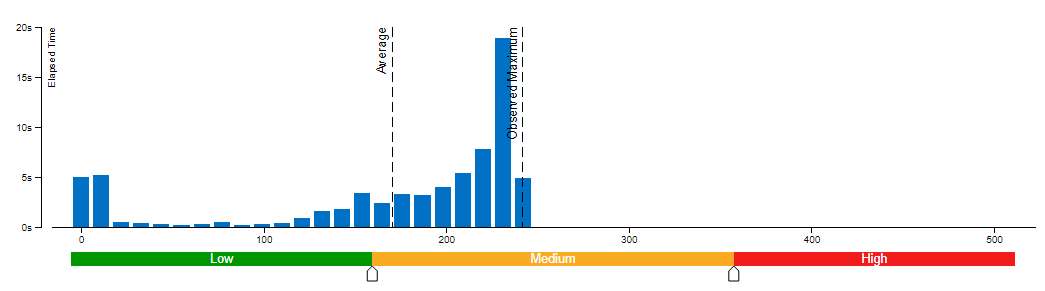
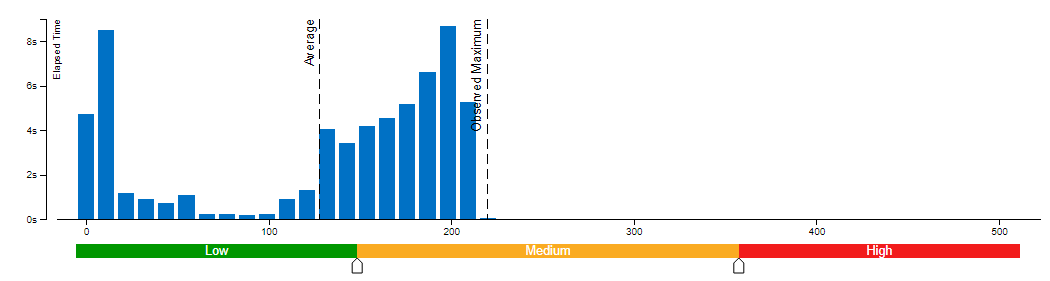

Clockticks per Instructions Retired(CPI) event ratio, also known as Cycles per Instructions, is one of the basic performance metrics for the hardware event-based sampling collection, also known as Performance Monitoring Counter (PMC) analysis in the sampling mode. This ratio is calculated by dividing the number of unhalted processor cycles(Clockticks) by the number of instructions retired. On each processor the exact events used to count clockticks and instructions retired may be different, but VTune Profiler knows the correct ones to use.
A CPI < 1 is typical for instruction bound code, while a CPI > 1 may show up for a stall cycle bound application, also likely memory bound.
Conclusion
Along with the upgrading of OpenVINO™ main branch, the optimization work in this workaround will be generalized and integrated into official release. It will be helpful to scale more LLMs model usage. Please refer OpenVINO™ official release and Optimum-intel OpenVINO™ backend to get official and efficient support for LLMs.































