.png)
Dariusz
Trawinski
Serving OpenVINO Models using the KServe API Standard
There are many network API specifications for model serving on the market today. Two of the most popular are TensorFlow Serving (TFS) and KServe. Starting with the 2022.2 release, OpenVINO Model Server supports KServe -- meaning both of these common API standards can be used for serving OpenVINO models. This blog explains how to take advantage of either API.
OpenVINO provides an efficient and high-performance runtime for executing deep learning inference. In many situations, AI applications need to delegate inference execution to a remote device or service over a network. There are many advantages to this approach including the ability to scale.
AI software developers expect the communication interface with a model server to remain stable. In many cases, developers want to perform pre/post-processing on the client side with minimal dependencies. They are reluctant to switch to a different serving implementation if that requires substantial code changes or new dependencies in their applications.
Since the first release in 2018, OpenVINO Model Server has supported the TFS API. And as of 2022, the KServe API is now supported as well.
KServe is a standard designed by several companies across the industry. It has been adopted by model servers like Triton Inference Server and TorchServe. Now the same client can easily switch to use OpenVINO Model Server and leverage the latest optimizations in Intel(R) CPUs and GPUs.
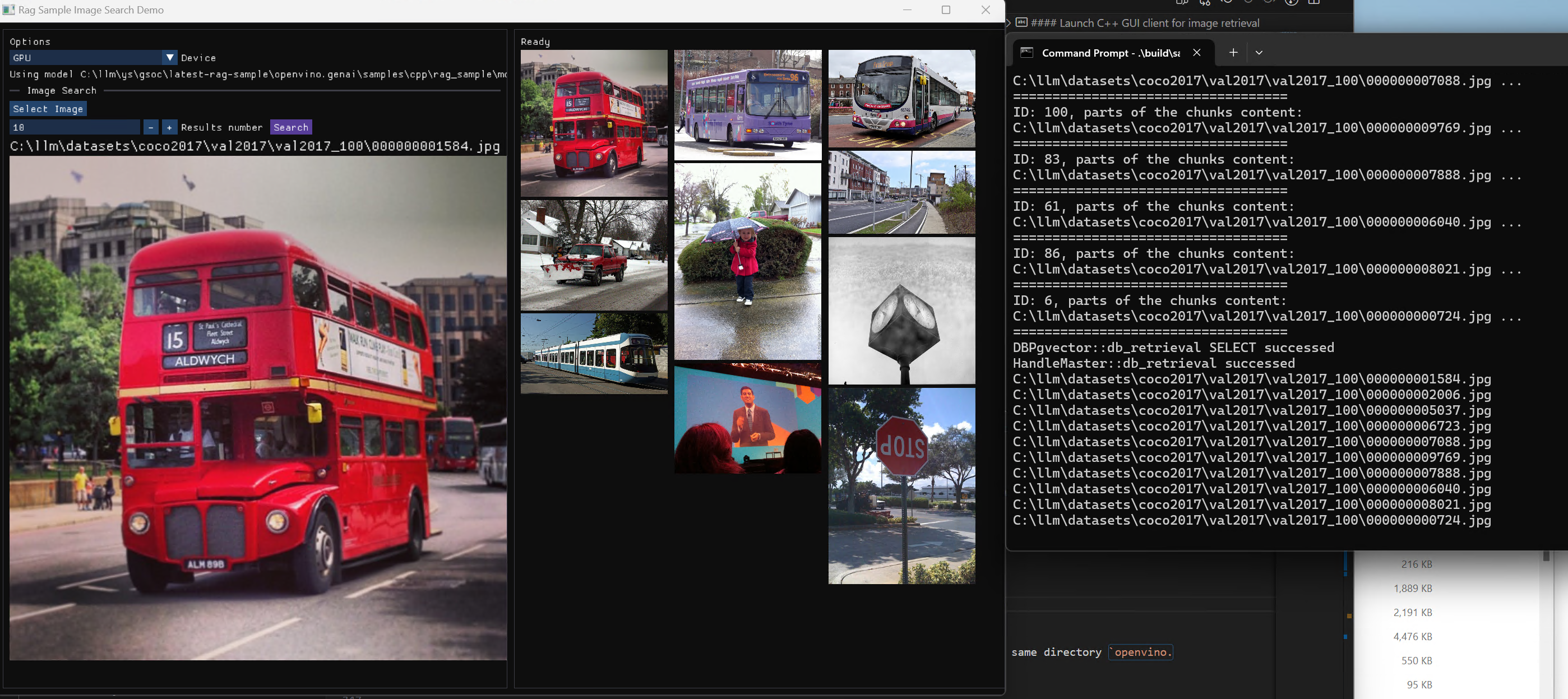
KServe Python Example
Below is a simple example how to use KServe using the Python-based tritonclient.
Create Model Repository
Start OpenVINO Model Server with a ResNet-50 Model:
Install Python Client Library
Get the Model Metadata
Get a Sample Image

Run Inference via gRPC Interface with a NumPy File as Input Data
Run Inference via REST Interface with a JPEG File as Input Data
Run Inference via REST Interface with a JPEG File as Input Data using cURL
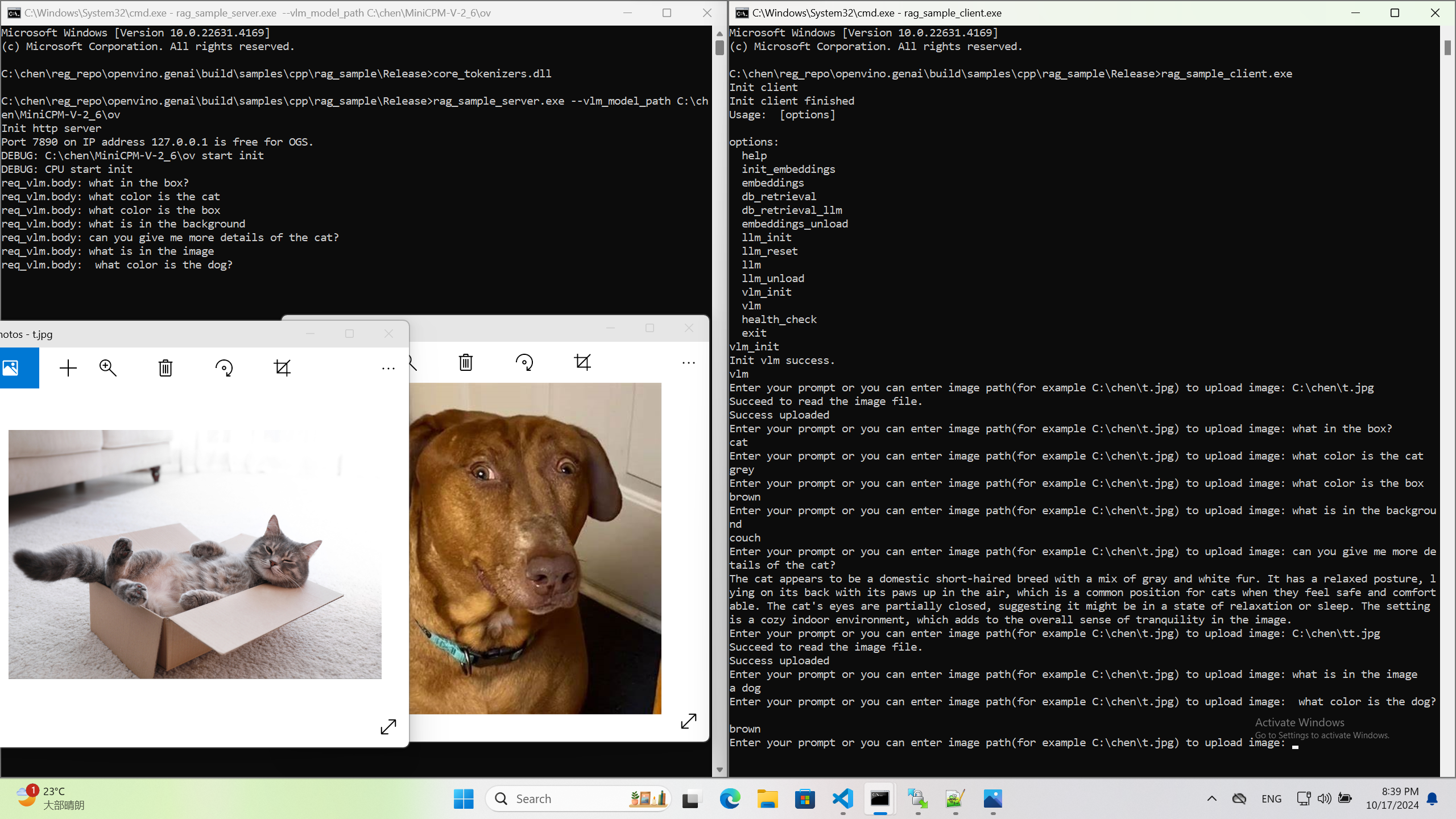
KServe C++ Example
The inference execution is also made easy in C++ based client applications. The examples below show client application execution based on the Triton C++ client library.
Build the Samples:
Get the Model Metadata
The compiled application grpc_model_metadata can make a call to gRPC endpoint and query for a server model metadata.
Run Inference via gRPC with a JPEG Encoded File as the Input Data
The sample application grpc_infer_resnet is sending the inference requests for a set of images listed inresnet_input_images.txt including their expected classification number in the ImageNet dataset.
In addition to the KServe API, the TFS API can still be used by client applications. This gives you the option to use a range of client libraries like tensorflow-serving-api or the much lighter and simplified ovmsclient.
To help you get started, we provide samples in Python, C++, Java and Go:
In conclusion, it is now easier to connect and AI applications to OpenVINO Model Server. In existing applications, you can even use the same code to take advantage of the benefits of OpenVINO.