
.png)
Xiake
Sun
Large Language Model Graph Customization with OpenVINO™ Transformations API
Authors: Xiake Sun, Wenyi Zou, Fiona Zhao
Introduction
A Large Language Model (LLM) is a type of artificial intelligence algorithm that uses deep learning techniques and massively large data sets to understand, summarize, generate and predict new content.
OpenVINO™ optimizes the deployment of LLMs, enhancing their performance and integration into various applications. We already provide general guide to use LLMs with OpenVINO™, from model loading and conversion to advanced use cases.
In this blog, we will introduce some useful method to customize Large Language model’s graph with OpenVINO™ transformation API.
OpenVINO™ Runtime has three main transformation types:
- Modelpass: straightforward way to work with ov::Model directly
- Matcherpass: pattern-based transformation approach
- Graphrewrite pass: container for matcher passes needed for efficient execution.
In this blog, we mainly use ov::pass::MatcherPassto customize model subgraph via pattern-based transformation.
Here are common steps to implement graph customization using ov::pass::MatcherPass.
- Create a pattern
- Implement a callback
- Register the pattern and Matcher
- Execute MatcherPass
In this blog, we will use an open-source LLMs Qwen1.5-7B-Chat-GPTQ-Int4 from Alibaba Cloud with guide for model conversion and graph customization methods.
Qwen Pytorch to OpenVINO™ Model conversion
Here we can use openvino.genai repo to convert Qwen1.5 GPTQ INT4 Pytroch model to OpenVINO™model.
Converted model can be find in path “Qwen1.5-7B-Chat-GPTQ-Int4-OV/pytorch/dldt/GPTQ_INT4-FP16/".
Insert custom layer to OpenVINO™ model
Vocabularysize in the context of LLMs refers to the total number of unique words, or tokens, that the model can recognize and use. The larger the vocabulary size,the more nuanced and detailed the model’s understanding of language can be,however, it also requires more computational and memory resources for deployment. E.g. Qwen’s vocabulary size(151936) is almost 5x that Llama2 (32000), therefore additional optimization is required for efficient deployment.
We found that the following pattern existed in the Qwen model in Figure 2:
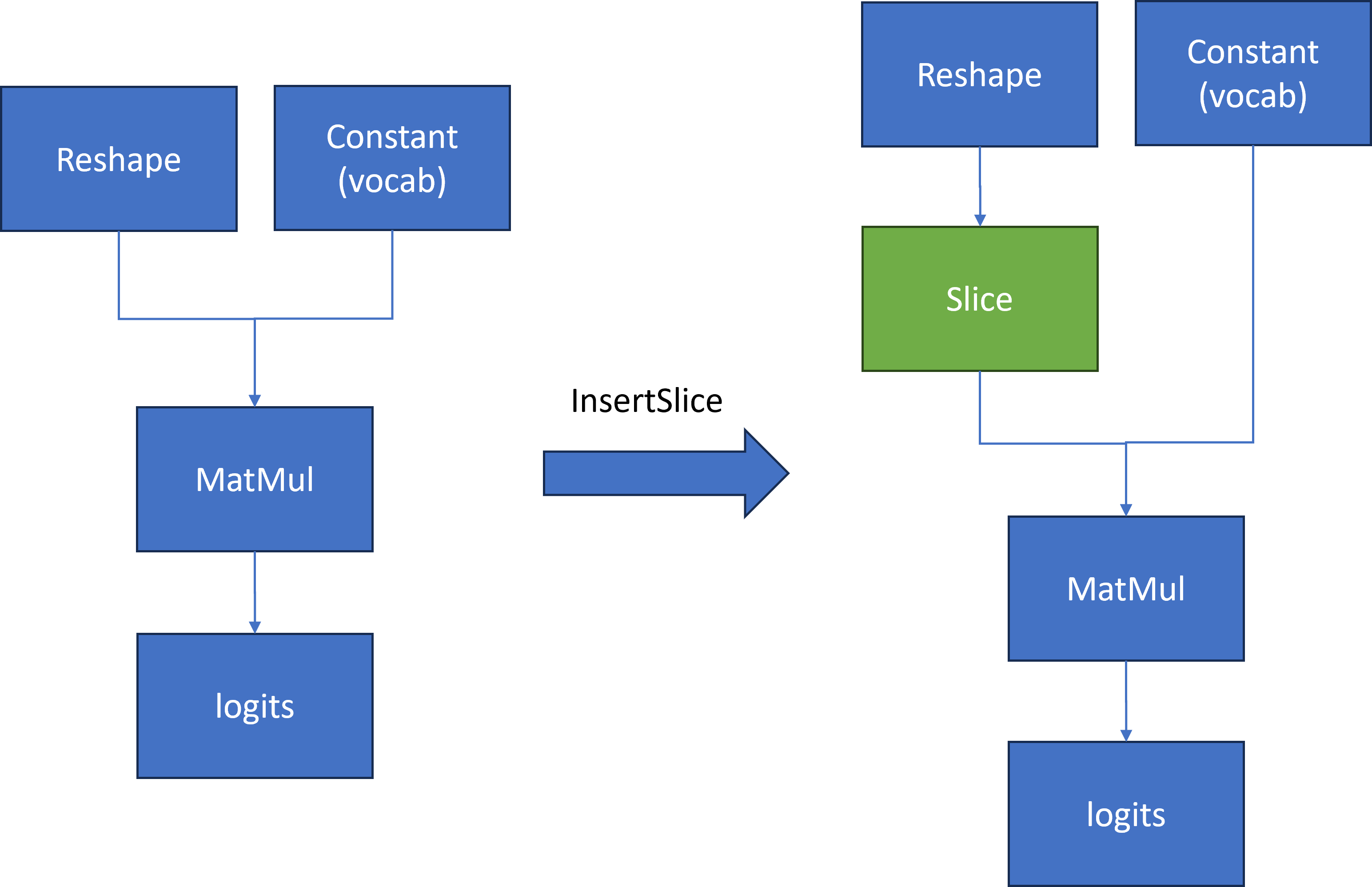
To compute the first token generation for the input prompt with shape [1, seq_length], we need to calculate a MatMul operation based on two inputs.
- First input is a reshape node output with shape[1, seq_length, 4096]
- Second input is a constant value that contains the model’s vocabulary with shape [4096,151936]
Then Matmul calculates two inputs [1, seq_length, 4096] * [4096,151936] to output large logits [1, seq_length,151936]. However, for the next token prediction, we only need the last element [1,4096] in 1st dimension from logits for sampling.
The main idea is to insert a slice operation between Reshape and Matmul nodes to extract only the last element in 2nd dimension of reshape node output as the first input with shape [1,4096] for computation. Therefore, Matmul computation can be reduced from [1, seq_len, 4096] * [1, 4096, 151936] = [1, seq_len, 151936] to [1, 1, 4096] *[4096, 151936] = [1, 1, 151936], which can reduce first token latency and memory consumption.
Here is a sample code to implement the workflow defined in Figure2 to reduce Qwen's last Matmul computation and memory usage:
We defined a OpenVINO™ transformation "InsertSlice" to find the logits (Results) node via ov::pass::MatchPass, then search along root->parent->grandparent node to find the Reshape node. Afterward, we insert a Slice node between the Reshape and Matmul nodes to extract the last element of seq_length with shape [1,1,4096]. In the end, we apply "InsertSlice" transformation to original OpenVINO™ model and save modified model on disk for deployment.
Modify model weights of specified layer in OpenVINO™ model
In case you want to update certain model layer weights after model training or fine-tuning/compression.
E.g. if you have an INT4 weight-compressed model using another model compression method, e.g. AWQ, you may want to transfer model weights optimized with the quantization method.
The most general method will be to convert the original model to OpenVINO™ model if the model direct conversion works. However, if first option is not works out of box, an alternative option is to replace the model weights from OpenVINO™ models with external fine-tuning model weights.
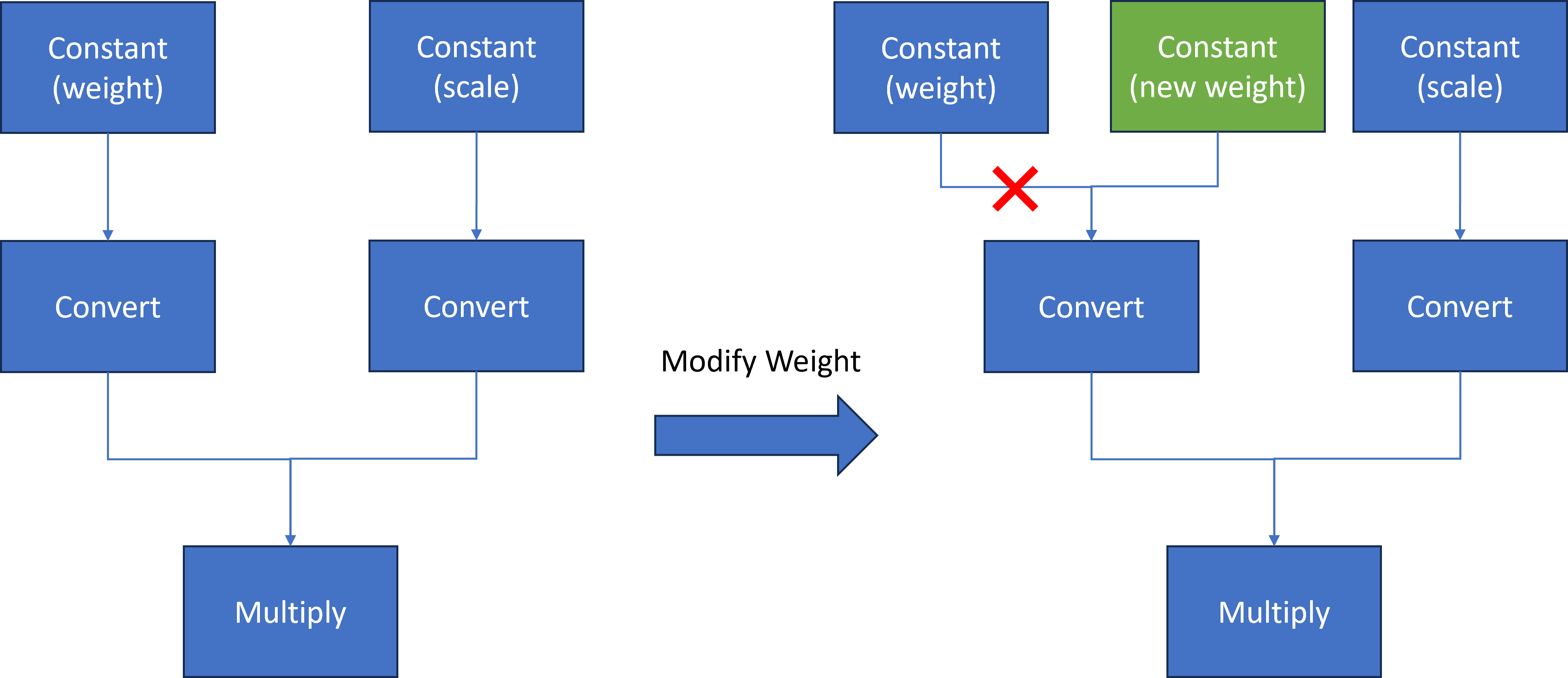
Here we introduce a common method to modify layer weights of Qwen model via OpenVINO™ transformation API.
As Figure 3 shows, the goal is to replace model weights and scale of the original Constant node with external fine-tuned weights and scale data.
At first, we use ov::pass::MatchPass method to find the Convert node after the target node. Then we create a new constant node with external weight saved as a numpy array. Please note, GPTQ int4 model weight is saved asuint4 (U4) binary format, while numpy can only represent data with numpy.uint8. Therefore, we use a help function to pack 2 uint4 binary data as 1 uint8 binary data. Then we replace the Convert input port from the original Constant node to the new Constant node. Since the old constant node has no consumers and is neither the Result nor the Sink operation whose shared pointer counter is zero, the operation will be destructed and not be accessible anymore.
Here is a sample code to implement the workflow defined in Figure3 to replace Qwen Constant node via the new Constant node with external data:
We defined a OpenVINO™ transformation "InsertWeights" to find the target constant node via ov::pass::MatchPass, then we create a new Constat node with external numpy data and pack it as uint4 OpenVINO™ Tensor to replace original constant node in graph. In the end, we apply "InsertWeights" transformation to original OpenVINO™ model and save modified model on disk for deployment.
Conclusion
In this blog, we introduce how to apply graph customization based on OpenVINO™ model with OpenVINO™ transformation API. Furthermore, we show two examples of inserting layers & modifying layer weights based on Qwen LLM model with simple Python code.
Reference
IntegrateOpenVINO™ with Your Application – Model Representation































