.png)
Tong
Qiu
Optimizing MeloTTS for AIPC Deployment with OpenVINO: A Lightweight Text-to-Speech Solution
Authors : Qiu Tong, Zhao Hongbo
MeloTTS released by MyShell.ai, is a high-quality, multilingual Text-to-Speech (TTS) library that supports English, Chinese (mixed English), and various other languages. The strengths of the model lie in its lightweight design, which is well-suited for applications on AIPC systems, coupled with its impressive performance. In this article, I will guide you through the process of converting the model to be compatible with OpenVINO toolkits, enabling it to run on various devices such as CPUs, GPUs and NPUs. Additionally, I will provide a concise overview of the model's inference procedure.
Overview of Model Inference Procedure and Pipeline
For each language type, the pipeline requires only two models (two inference procedures). For instance, English language generation necessitates just the 'bert-base-uncased' model and its corresponding MeloTTS-English. Similarly, for Chinese language generation (which includes mixed English), the pipeline needs only the 'bert-base-multilingual-uncased' and MeloTTS-Chinese. This greatly streamlines the pipeline compared to other TTS frameworks, and the compact size of the models makes them suitable for deployment on edge devices.
MeloTTS is based on Variational Inference with adversarial learning for end-to-end Text-to-Speech (VITS). The inference process is illustrated in the figure. It encompasses a text encoder, a stochastic duration predictor, a decoder.
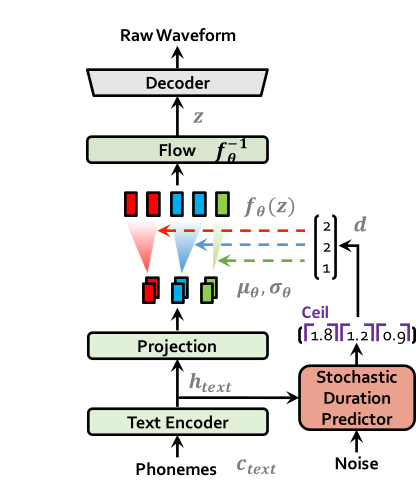
The text encoder accepts phones, tones and a hidden layer from a BERT model as input. It then produces the text encoder's output along with its mean value and a logarithmic variance. To align the input texts with the target speech, the outputs from the encoders are processed using a stochastic duration predictor, which generates an alignment matrix. This matrix is then used to expand the mean value and a logarithmic variance (assuming a Gaussian distribution) to obtain the results for the latent variables .Subsequently, the inverse flow transformation is applied to obtain the distribution of final latent variable z, which represents the spectrogram. In the decoder, by upsampling the spectrogram, the final audio waveform is obtained.
def ov_infer(self, phones=None, phones_length=None, speaker_id=None, tones=None, lang_ids=None, bert=None, ja_bert=None, sdp_ratio=0.2, noise_scale=0.6, noise_scale_w=0.8, speed=1.0):
The inference entry is the function. In practical inference, phone refers to the distinct speech sounds, while tone refers to the vocal pitch contour. For Chinese, a phone corresponds to pinyin, and a tone corresponds to one of the four tones. In English, phones are the consonants and vowels, and tones relate to stress patterns. Here, noise_scale and noise_scale_w do not refer to actual noise. Both noise_scale_w and noise_scale are components within the Stochastic Duration Predictor, used to introduce randomness in order to enhance the expressiveness of the model.
Note that MeloTTS does not include a voice cloning component, unlike the majority of other TTS models, which makes it more lightweight. If voice cloning is required, please refer to OpenVoice.
Enable Model for OpenVINO
As previously mentioned, the pipeline requires just two models for each language. Taking English as an example, we must first convert both 'bert-base-uncased' and 'MeloTTS-English' into the OpenVINO IR format.
example_input={
"x": x_tst,
"x_lengths": x_tst_lengths,
"sid": speakers,
"tone": tones,
"language": lang_ids,
"bert": bert,
"ja_bert": ja_bert,
"noise_scale": noise_scale,
"length_scale": length_scale,
"noise_scale_w": noise_scale_w,
"sdp_ratio": sdp_ratio,
}
ov_model = ov.convert_model(
self.model,
example_input=example_input,
)
get_input_names = lambda: ["phones", "phones_length", "speakers",
"tones", "lang_ids", "bert", "ja_bert",
"noise_scale", "length_scale", "noise_scale_w", "sdp_ratio"]
for input, input_name in zip(ov_model.inputs, get_input_names()):
input.get_tensor().set_names({input_name})
outputs_name = ['audio']
for output, output_name in zip(ov_model.outputs, outputs_name):
output.get_tensor().set_names({output_name})
"""
reshape model
Set the batch size of all input tensors to 1
"""
shapes = {}
for input_layer in ov_model.inputs:
shapes[input_layer] = input_layer.partial_shape
shapes[input_layer][0] = 1
ov_model.reshape(shapes)
ov.save_model(ov_model, Path(ov_model_path))
For instance, we convert the MeloTTS-English model from the pytorch format directly by utilizing the openvino.convert_model API along with pseudo input data.
Note that the input and output layers (it is optional) are renamed to facilitate subsequent development. Furthermore, the batch dimension for all inputs is fixed at 1, as multiple batches are not required here (this is also optional).
We further quantized both the BERT and TTS models to int8 using pseudo data. We observed that our method of quantizing the TTS model introduces a slight distortion to the current sound. To suppress this, we implemented DeepFilterNet, which is also very lightweight.
More about model conversion and int8 quantization please refer to MeloTTS-OV .
Run BERT part on NPU
To enhance performance and reduce CPU offloading, we can shift the execution of the BERT model to the NPU on Meteor Lake.
To adapt the model for the NPU, we've converted the model to accept static shape inputs a and pad each input during inference.
def reshape_for_npu(model, bert_static_shape = 32):
# change dynamic shape to static shape
shapes = dict()
for input_layer in model.inputs:
shapes[input_layer] = bert_static_shape
model.reshape(shapes)
ov.save_model(model, Path(ov_model_save_path))
print(f"save static model in {Path(ov_model_save_path)}")
def main():
core = Core()
model = core.read_model(ov_model_path)
reshape_for_npu(model, bert_static_shape=bert_static_shape)
Simple Demo
Here are the audio files generated by the int8 quantized model from OpenVINO.
https://github.com/zhaohb/MeloTTS-OV/tree/speech-enhancement-and-npu/demo