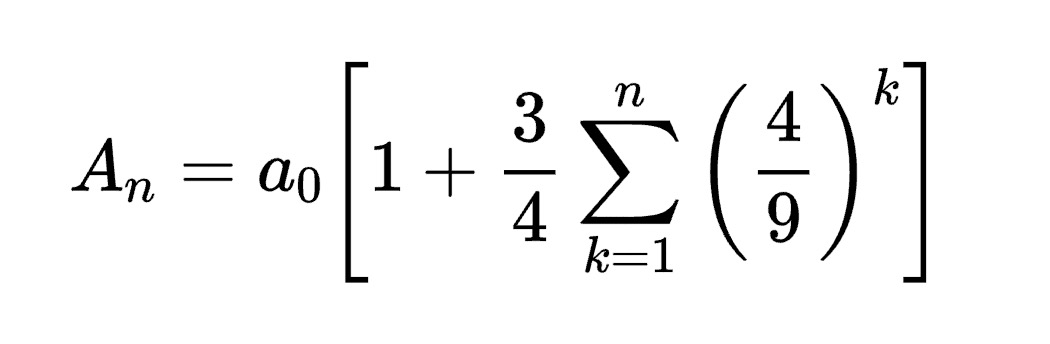Authors: Tianmeng Chen, Xiake Sun, Fiona Zhao, Su Yang
Introduction
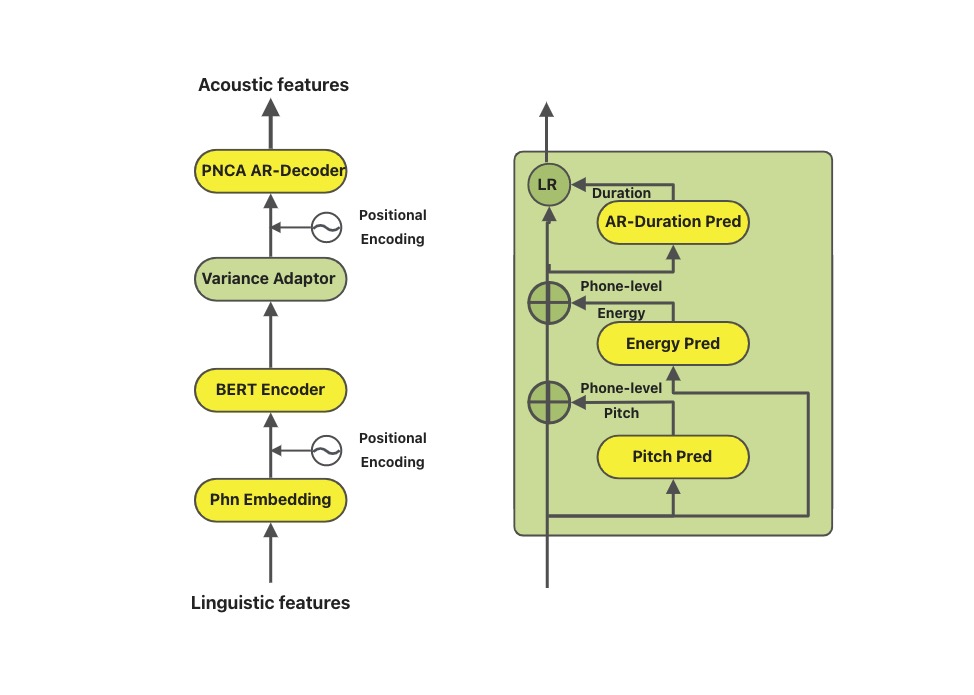
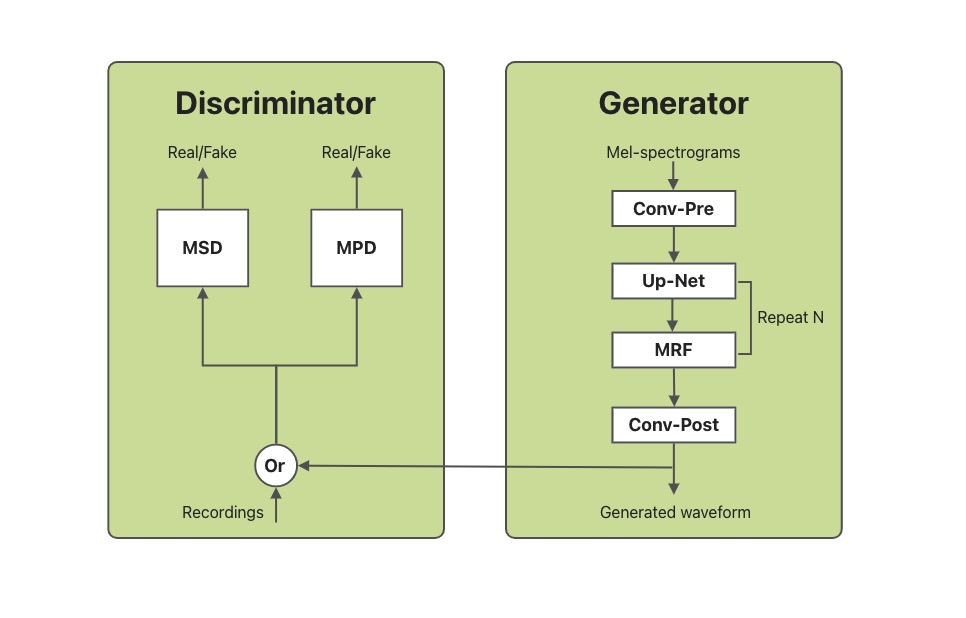
Personalized Speech Synthesis is the process of using some recording devices around you to record certain voice clips of a particular person, and then letting Text-To-Speech (TTS) technology synthesize the voice, manner of speaking, and emotion of a particular person. SAMBERT-HifiGAN is a complete personalized TTS solution designed by Alibaba Damo Institute, which includes the first part of SAMBERT's acoustic model and the second part of the HifiGAN vocoder.
Structure of SAMBERT
Structure of HifiGAN
In this blog, we will introduce how to utilize OpenVINOTM Python API to enable the SAMBERT-HifiGAN pipeline. All the project code can be found here.
KAN-TTS by Ali provides a tutorial for training SAMBERT-HifiGAN. A pipeline for personalized speech synthesis based on PyTorch is provided on modelscope, what we will do here is toreplace the PyTorch based part of it with OpenVINOTM. It is worth noting that due to some of the operators in the model, there are some modules that cannot be replaced with OpenVINOTM Python API.
Pre-requisite
Since we need to make changes on the pipeline based on PyTorch backend, the first thing we need to do is to download the KAN-TTS source code and successfully run through the pipeline to get the inputs and outputs of the model as well as the state of the middle layer. Of course we also need the OpenVINOTM environment.
Get the KAN-TTS source code and create anacondaenvironment.
git clone -b develop https://github.com/alibaba-damo-academy/KAN-TTS.git
cd KAN-TTS
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
conda env create -f environment.yaml
conda activate maas
Then we install openvino in same environment. Ifyou want specific version of OpenVINOTM, you can install it byyourself through Install OpenVINO™.
pip install openvino
Follow the KAN-TTS practice tutorial of official with readme in ModelScope.
After you finish the pipelining of KAN-TTS, you can get the res folder and ckpt filesspeech_personal_sambert-hifigan_nsf_tts_zh-cn_pretrain_16k .
Get the OpenVINOTM backend projectsource code and copy the res folder to project folder.
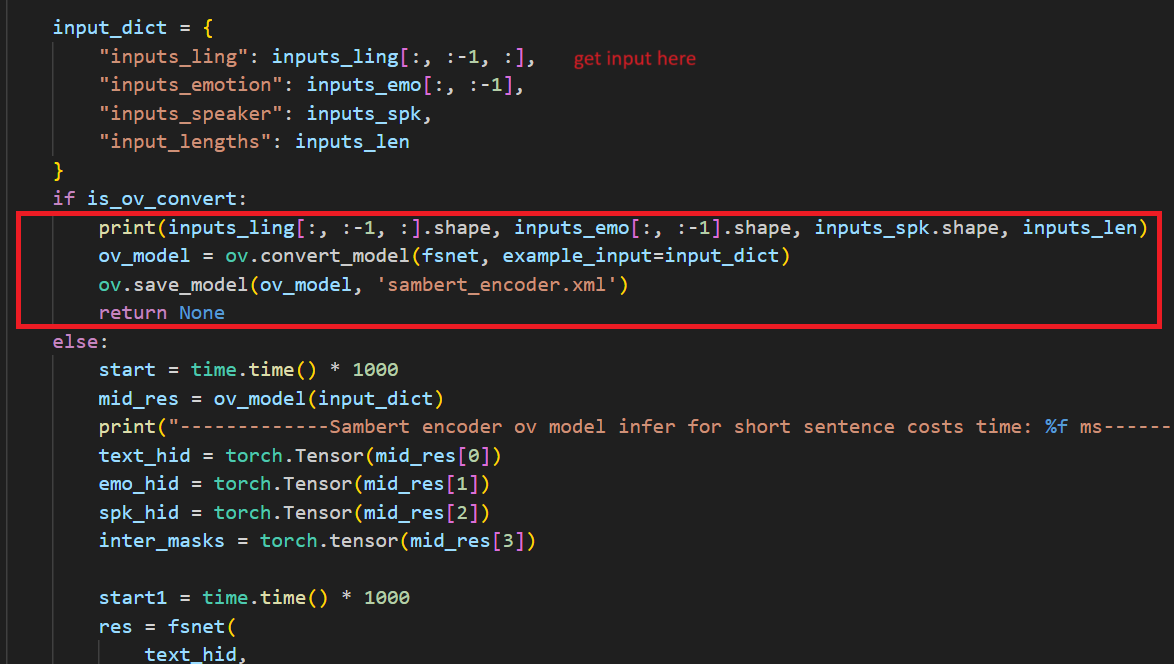
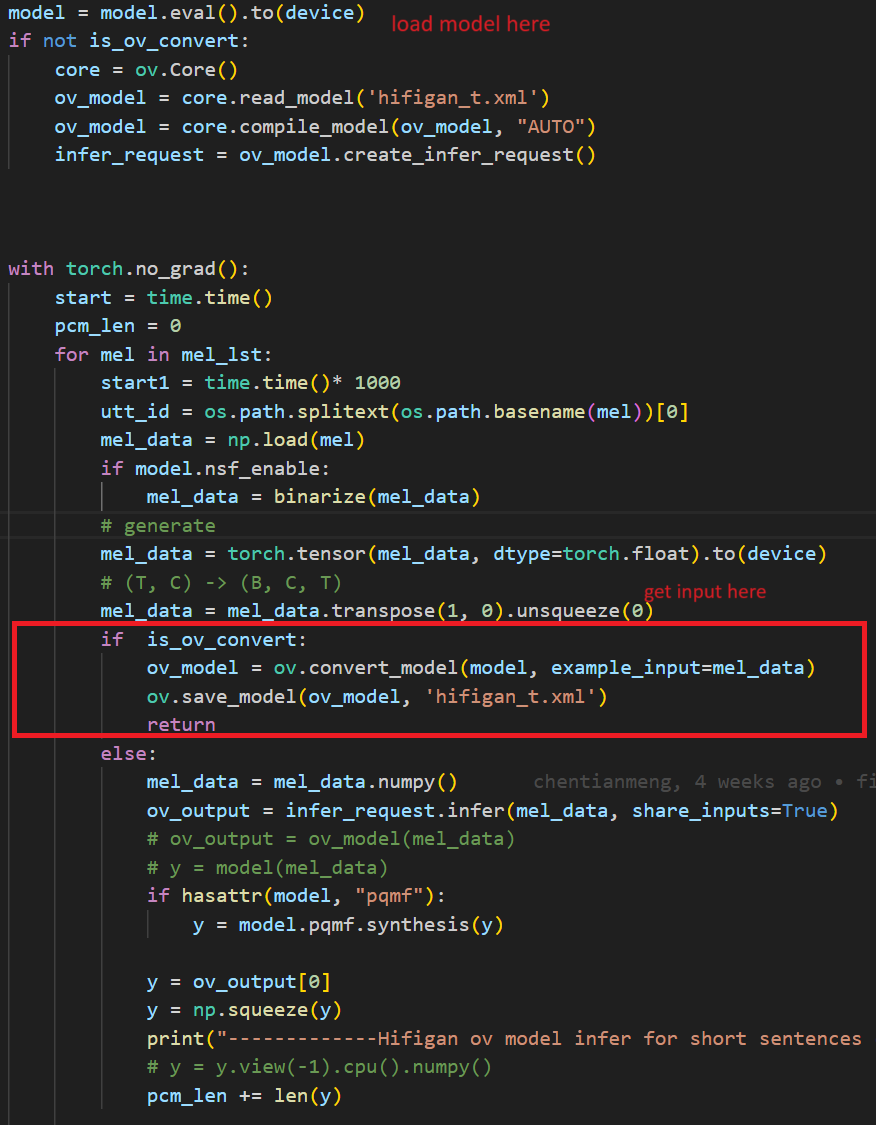
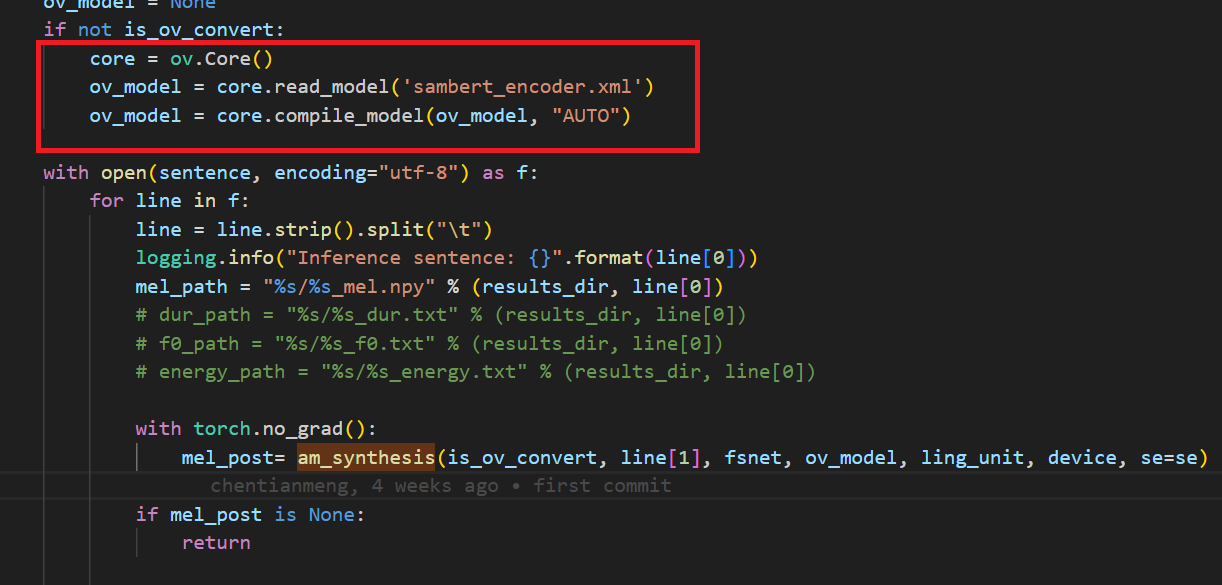
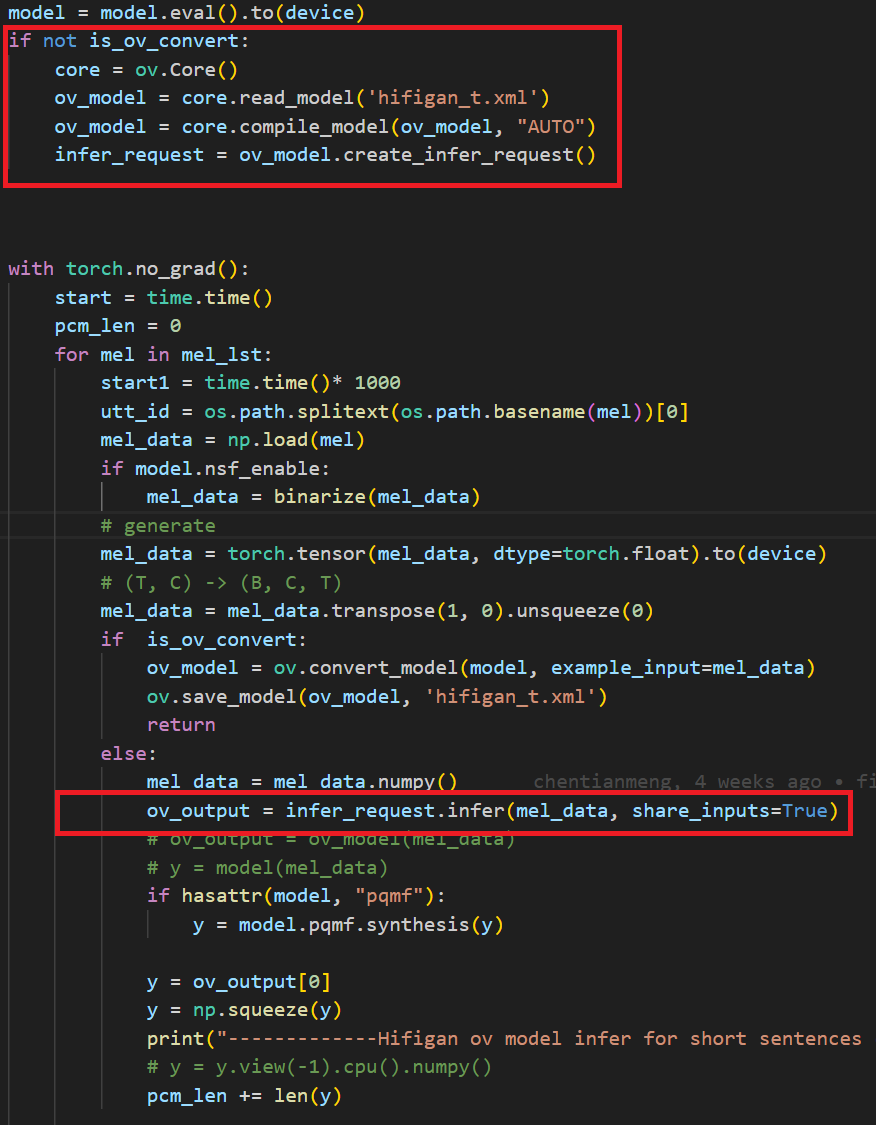
Aftera few minutes, you will get two converted OpenVINOTM model sambert_encoder.xml sambert_encoder.bin and hifigan_t.xml hifigan_t.bin.
In the code after we load the model and get the inputs, we add the following code to convert the loaded PyTorch backend model to OpenVINOTM backend model and save it.
Example code of SAMBERT pipeline
Example code of HifiGAN pipeline
Run the inferencewith OpenVINOTM model
Before running the inference, the res folder should be renamed to allow for comparisons later.
After a few minutes, you will get the wav file in res/test_male_ptts_syn. For example in test.txt we write a random sentence:
After running pipeline, we will get a 7 seconds wav file under res folder:
In the code we modified the original pytorch banckend inference code so that pipeline uses openvino backend for inference.
Example code of SAMBERT pipeline
Example code of HifiGAN pipeline
Summary
This blog describes about how to run the SAMBERT-HifiGANpipeline using the OpenVINOTM Python API, please see the source code formore details and modifications.
The integration of Ollama and OpenVINO delivers a powerful dual-engine solution for the management and inference of large language models (LLMs). Ollama offers a streamlined model management toolchain, while OpenVINO provides efficient acceleration capabilities for model inference across Intel hardware (CPU/GPU/NPU). This combination not only simplifies the deployment and invocation of models but also significantly enhances inference performance, making it particularly suitable for scenarios demanding high performance and ease of use.
You can find more information on github repository:
1. Streamlined LLM Management Toolchain: Ollama provides a user-friendly command-line interface, enabling users to effortlessly download, manage, and run various LLM models.
2. One-Click Model Deployment: With simple commands, users can quickly deploy and invoke models without complex configurations.
3. Unified API Interface: Ollama offers a unified API interface, making it easy for developersto integrate into various applications.
4. Active Open-Source Community: Ollama boasts a vibrant open-source community, providing users with abundant resources and support.
Limitations of Ollama
Currently, Ollama only supports llama.cpp as itsbackend, which presents some inconveniences:
1. Limited Hardware Compatibility: llama.cpp is primarily optimized for CPUs and NVIDIA GPUs, and cannot fully leverage the acceleration capabilities of Intel GPUs or NPUs, resulting in suboptimal performance in high-performance computing scenarios.
2.Performance Bottlenecks: For large-scale models or high-concurrency scenarios, the performance of llama.cpp may fall short, especially when handling complex tasks, leading to slower inference speeds.
Breakthrough Capabilities of OpenVINO
1. Deep Optimization for Intel Hardware (CPU/iGPU/Arc dGPU/NPU): OpenVINO is deeply optimized for Intel hardware, fully leveraging the performance potential of CPUs, iGPUs, dGPUs, and NPUs.
2. Cross-Platform Heterogeneous Computing Support: OpenVINO supports cross-platform heterogeneous computing, enabling efficient model inference across different hardware platforms.
3. Model Quantization and Compression Toolchain: OpenVINO provides a comprehensive toolchain for model quantization and compression, significantly reducing model size and improving inference speed.
4. Significant Inference Performance Improvement: Through OpenVINO's optimizations, model inference performance can be significantly enhanced, especially for large-scale models and high-concurrency scenarios.
5. Extensibility and Flexibility Support: OpenVINO GenAI offers robust extensibility and flexibility for Ollama-OV, supporting pipeline optimization techniques such as speculative decoding, prompt-lookup decoding, pipeline parallelization, and continuous batching, laying a solid foundation for future pipeline serving optimizations.
Developer Benefits of Integration
1.Simplified Development Experience: Retains Ollama's CLI interaction features, allowing developers to continue using familiar command-line tools for model management and invocation.
2.Performance Leap: Achieves hardware-level acceleration through OpenVINO, significantly boosting model inference performance, especially for large-scale models and high-concurrency scenarios.
3.Multi-Hardware Adaptation and Ecosystem Expansion: OpenVINO's support enables Ollama to adapt to multiple hardware platforms, expanding its application ecosystem and providing developers with more choices and flexibility.
For Windows systems, first extract the downloaded OpenVINO GenAI package to the directory openvino_genai_windows_2025.2.0.0.dev20250320_x86_64, then execute the following commands:
cd openvino_genai_windows_2025.2.0.0.dev20250320_x86_64
setupvars.bat
3. Set Up cgocheck
Windows:
set GODEBUG=cgocheck=0
Linux:
export GODEBUG=cgocheck=0
At this point, the executable files have been downloaded, and the OpenVINO GenAI, OpenVINO, and CGO environments have been successfully configured.
Custom Model Deployment Guide
Since the Ollama Model Library does not support uploading non-GGUF format IR models, we will create an OCI image locally using OpenVINO IR that is compatible with Ollama. Here, we use the DeepSeek-R1-Distill-Qwen-7B model as an example:
With these steps, we have successfully created the DeepSeek-R1-Distill-Qwen-7B-int4-ov:v1 model, which is now ready for use with the Ollama OpenVINO backend.
Janus is a unified multimodal understanding and generation model developed by DeepSeek. Janus proposed decoupling visual encoding to alleviate the conflict between multimodal understanding and generation tasks. Janus-Pro further scales up the Janus model to larger model size (deepseek-ai/Janus-Pro-1B & deepseek-ai/Janus-Pro-7B) with optimized training strategy and training data, achieving significant advancements in both multimodal understanding and text-to-image tasks.
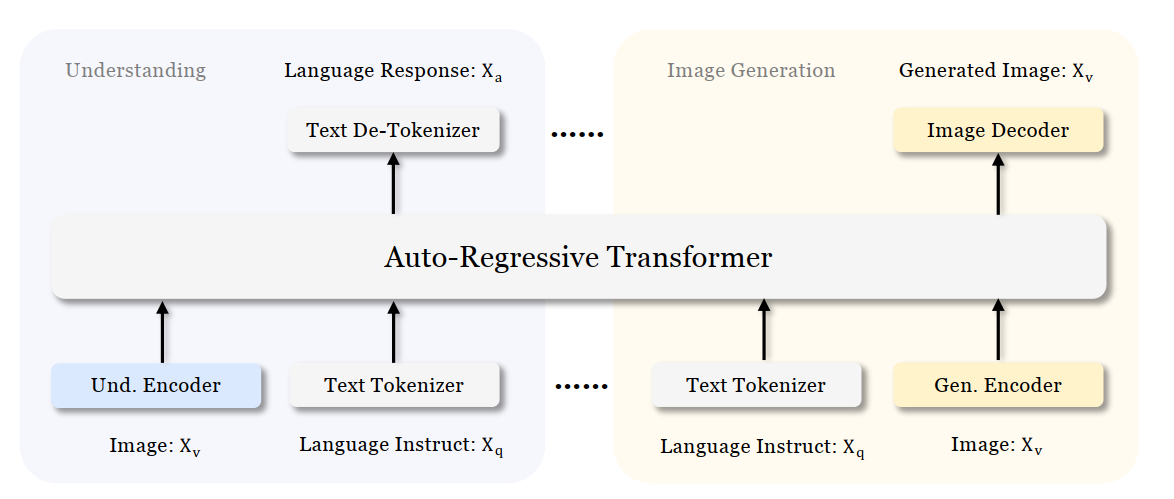
Figure 1: Overview of Janus-Pro Architecture
Figure 1 shows the architecture of Janus-Pro, which decouples visual encoding for multimodal understanding and visual generation. “Und. Encoder” and “Gen. Encoder” are abbreviations for “Understanding Encoder” and “Generation Encoder”. For the multimodal understanding task, SigLIP vision encoder used to extract high-dimensional semantic features from the image, while for the vision generation task, VQ tokenizer used to map images to discrete IDs. Both the understanding adaptor and the generation adaptor are two-layer MLPs to map the embeddings to the input space of LLM.
In this blog, we will introduce how to deploy Janus-Pro model with OpenVINOTM runtime on the intel platform.
2. Janus-Pro Pytorch Model to OpenVINOTM Model Conversion
The converted OpenVINO will be saved in Janus-Pro-1B-OV directory for deployment.
3. Janus-Pro Inference with OpenVINOTM Demo
In this section, we provide several examples to show Janus-Pro for multimodal understanding and vision generation tasks.
3.1. Multimodal Understanding Task – Image Caption with OpenVINOTM
$ python run_janus_vlm_ov.py -m Janus-Pro-1B-OV -p "Describe image in det
ails" -i images/cat_in_box.png -d GPU
Prompt: Describe image in details
Input image:
Generated Output:
The image shows a gray tabby cat lying inside an open cardboard box on a carpeted floor. The cat is lying on its back with its belly exposed, looking relaxed and comfortable. The background includes a beige-colored sofa and a light-colored curtain,
suggesting a cozy indoor setting. The cat's tail is curled around its body, and it appears to be enjoying itself.
3.2. Multimodal Understanding Task – Equation Description with OpenVINOTM
$ python run_janus_vlm_ov.py -m Janus-Pro-1B-OV -p "Generate the latex code of this formula" -i images/equation.png -d GPU
Prompt: Generate the latex code of this formula
Input Image:
Generated Output:
\[ A_n = a_0 \begin{bmatrix} 1 & + \frac{3}{4} \sum_{k=1}^{n} \begin{bmatrix} 4 \\ 9 \end{bmatrix}^k \end{bmatrix} \]
This formula represents the cumulative sum of the first \( n \) terms of the sequence \( a_n \), where \( a_n \) is the sequence of \( a_0 \), \( \frac{3}{4} \), and \( \begin{bmatrix} 4 \\ 9 \end{bmatrix}^k \). The first term \( a_0 \) is the first term of the sequence, the second term is the sum of the first \( n-1 \) terms, and the third term is the sum of the first \( n \) terms. The sequence \( \begin{bmatrix} 4 \\ 9 \end{bmatrix}^k \) represents the \( k \)-th term of the sequence. The
formula calculates the cumulative sum of the sequence \( a_n \).
This formula can be used to calculate the cumulative sum of the sequence \( a_n \) for any given \( n \).
3.3. Multimodal Understanding Task – Code Generation with OpenVINOTM
$ python run_janus_vlm_ov.py -m Janus-Pro-1B-OV -p "Generate the matplotlib pyplot code for this plot" -i images\pie_chart.png -d GPU
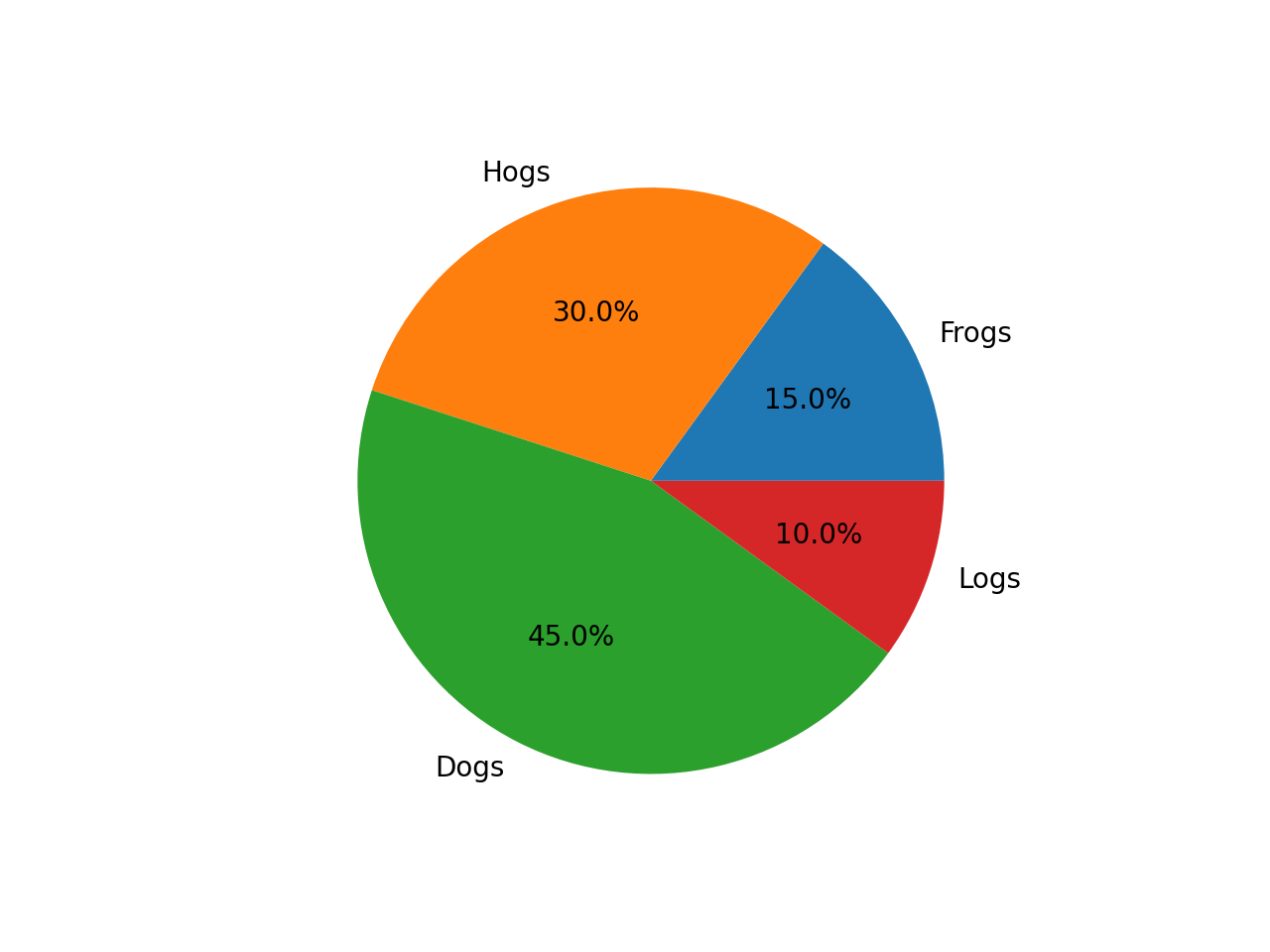
Prompt: Generate the matplotlib pyplot code for this plot
Input Image:
Generated Output:
The attention mask is not set and cannot be inferred from input because pad token is same as eos token. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Sure, here is the code to generate the matplotlib plot based on the information in the image:
```python
import matplotlib.pyplot as plt
# Data
data = {
'Hogs': 30,
'Frogs': 15,
'Logs': 10,
'Dogs': 45
}
# Create the plot
plt.figure(figsize=(10, 6))
# Pie chart
for key, value in data.items():
# Calculate the percentage of the pie chart
percentage = value / 100
# Add the pie slice
plt.pie(percentage, labels=data.keys(), autopct='%1.1f%%')
# Title and labels
plt.title('Pie chart')
plt.xlabel('Categories')
plt.ylabel('Percentage')
# Show the plot
plt.show()
```
This code will create a pie chart based on the data provided in the image.
Input Prompt: A cute and adorable baby fox with big brown eyes, autumn leaves in the background enchanting, immortal, fluffy, shiny mane, Petals, fairyism, unreal engine 5 and Octane Render, highly detailed, photorealistic, cinematic, natural colors.
We also provide benchmark scripts to evaluate Janus-Pro model performance and memory usage with OpenVINOTM inference, you may specify model name and device for your target platform.
4.1. Benchmark Janus-Pro for Multimodal Understanding Task with OpenVINOTM
Here are some arguments for benchmark script for Multimodal Understanding Task:
--model_id: specify the Janus OpenVINOTM model directory
--prompt: specify input prompt for multimodal understanding task
--image_path: specify input image for multimodal understanding task
--niter: specify number of test iteration, default is 5
--device: specify which device to run inference
--max_new_tokens: specify max number of generated tokens
By default, the benchmark script will run 5 round multimodal understanding tasks on target device, then report pipeline initialization time, average first token latency (including preprocessing), 2nd+ token throughput and max RSS memory usage.
4.2. Benchmark Janus-Pro for Text-to-Image Task with OpenVINOTM
Here are some arguments for benchmark scripts for Text-to-Image Task
--model_id: specify the Janus OpenVINO TM model directory
--prompt: specify input prompt for text-to-image generation task
--niter: specify number of test iteration
--device: specify which device to run inference
By default, the benchmark script will run 5 round image generation tasks on target device, then report the pipeline initialization time, average image generation latency and max RSS memory usage.
5. Conclusion
In this blog, we introduced how to enable Janus-Pro model with OpenVINOTM runtime, then we demonstrated the Janus-Pro capability for various multimodal understanding and image generation tasks. In the end, we provide python script for performance & memory usage evaluation for both multimodal understanding and image generation task on target platform.
LoRA, or Low-Rank Adaptation, reduces the number of trainable parameters by learning pairs of rank-decompostion matrices while freezing the original weights. This vastly reduces the storage requirement for large language models adapted to specific tasks and enables efficient task-switching during deployment all without introducing inference latency. Thus for a basic large model, the task scenarios of the model can be changed by different LoRAs. In a previous blog, it has been described how to convert the LoRAs-fused base model from pytorch to OpenVINO IR, but this method has the shortcoming of not being able to dynamically switch between LoRAs, which happen to be famous for their flexibility.
This blog will introduce how to implement the dynamic switching of LoRAs in a trick way. Specifically, for most of the tasks, the structure of the base model and LoRAs is unchanged, what changes is the task-specific LoRAs weights, and we can use these LoRAs weights as inputs to the model to achieve the dynamic switching function. All the code involved in this blog can be found here.
you should first change the lora file path and configs at first around line 478 in ov_model_export.py, after run python ov_model_ export.py, you will get related OpenVINO IR model. Then you can run ov_model_infer.py.
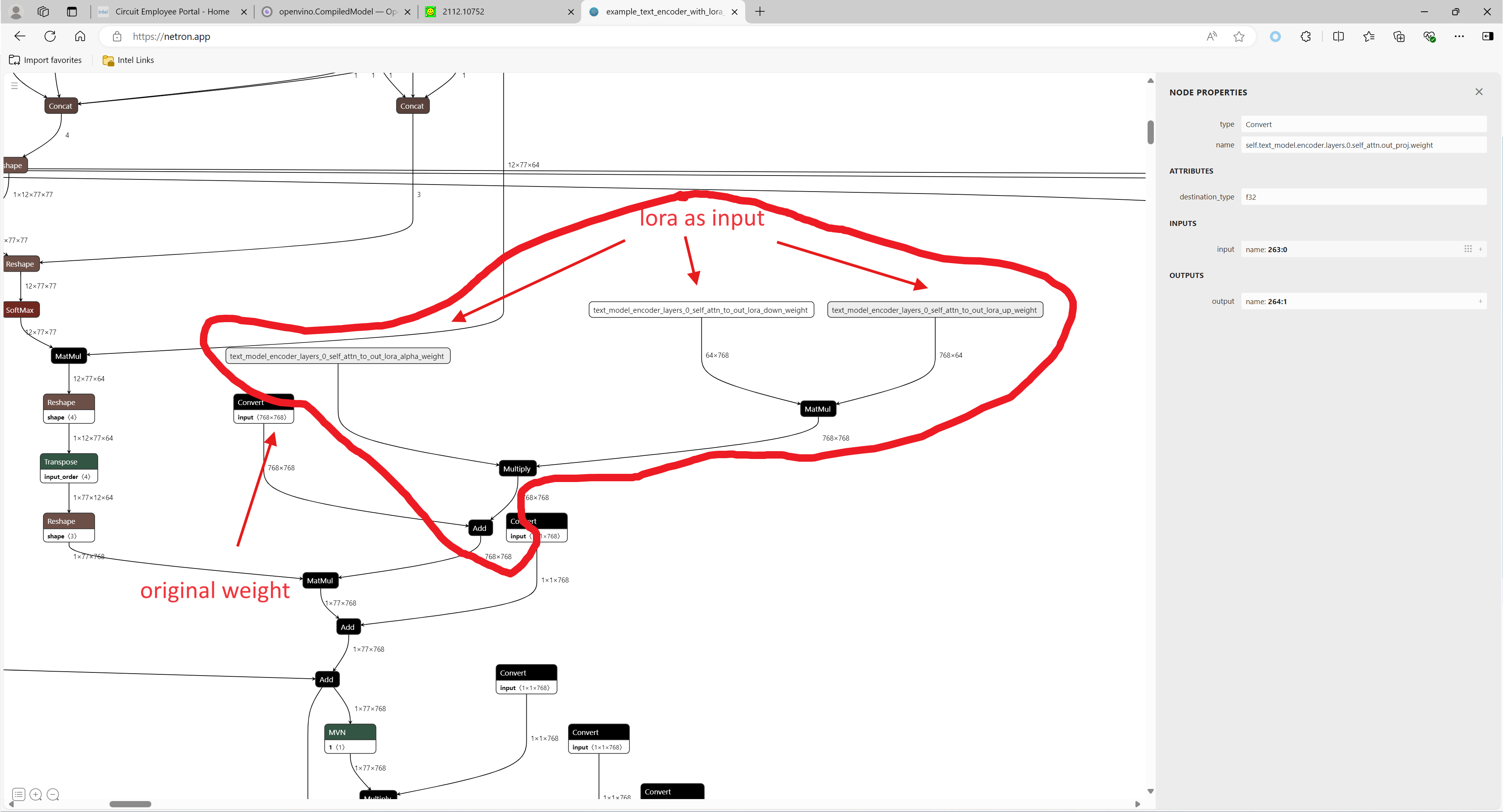
The most important part is the code in util.py, which is used to modify the model graph and load lora.
Function load_lora(lora_path, DEVICE_NAME) is used to load lora, get lora's shape and weights per layers and modify each layer's name.
def load_lora(lora_path, DEVICE_NAME):
state_dict = load_file(lora_path)
if DEVICE_NAME =="CPU":
for key, value in state_dict.items():
if isinstance(value, torch.Tensor):
value_fp32 = value.type(torch.float32)
state_dict[key] = value_fp32
layers_per_block = 2#TODO
state_dict = _maybe_map_sgm_blocks_to_diffusers(state_dict, layers_per_block)
state_dict, network_alphas = _convert_non_diffusers_lora_to_diffusers(state_dict)
# now keys in format like: "unet.up_blocks.0.attentions.2.transformer_blocks.8.ff.net.2.lora.down.weight"'
new_state_dict = {}
for key , value in state_dict.items():
if len(value.shape)==4:
# new_value = torch.reshape(value, (value.shape[0],value.shape[1]))
new_value = torch.squeeze(value)
else:
new_value = value
new_state_dict[key.replace('.', '_').replace('_processor','')] = new_value
# now keys in format like: "unet_up_blocks_0_attentions_2_transformer_blocks_8_ff_net_2_lora_down_weight"' LORA_PREFIX_UNET = "unet" LORA_PREFIX_TEXT_ENCODER = "text_encoder" LORA_PREFIX_TEXT_2_ENCODER = "text_encoder_2" lora_text_encoder_input_value_dict = {}
lora_text_encoder_2_input_value_dict = {}
lora_unet_input_value_dict = {}
lora_alpha = collections.Counter(network_alphas.values()).most_common()[0][0]
for key in new_state_dict.keys():
if LORA_PREFIX_TEXT_ENCODER in key and "lora_down"in key and LORA_PREFIX_TEXT_2_ENCODER not in key:
layer_infos = key.split(LORA_PREFIX_TEXT_ENCODER + "_")[-1]
lora_text_encoder_input_value_dict[layer_infos] = new_state_dict[key]
lora_text_encoder_input_value_dict[layer_infos.replace("lora_down", "lora_up")] = new_state_dict[key.replace("lora_down", "lora_up")]
elif LORA_PREFIX_TEXT_2_ENCODER in key and "lora_down"in key:
layer_infos = key.split(LORA_PREFIX_TEXT_2_ENCODER + "_")[-1]
lora_text_encoder_2_input_value_dict[layer_infos] = new_state_dict[key]
lora_text_encoder_2_input_value_dict[layer_infos.replace("lora_down", "lora_up")] = new_state_dict[key.replace("lora_down", "lora_up")]
elif LORA_PREFIX_UNET in key and "lora_down"in key:
layer_infos = key.split(LORA_PREFIX_UNET + "_")[-1]
lora_unet_input_value_dict[layer_infos] = new_state_dict[key]
lora_unet_input_value_dict[layer_infos.replace("lora_down", "lora_up")] = new_state_dict[key.replace("lora_down", "lora_up")]
#now the keys in format without prefix
return lora_text_encoder_input_value_dict, lora_text_encoder_2_input_value_dict, lora_unet_input_value_dict, lora_alpha
Function add_param(model, lora_input_value_dict) is used to add input parameter per names of related layers, which will be connected to model with manager.register_pass(InsertLoRAUnet(input_param_dict)) and manager.register_pass(InsertLoRATE(input_param_dict)), in these two classes, we search the whole model graph to find the related layers by their names and connect them with lora.

.png)