.png)
Xiake
Sun
Deploy End to End Super-Resolution Pipeline with OpenVINO™ Model Server
Introduction
In this blog, we will show how to deploy an end-to-end super-resolution pipeline by leveraging OpenVINOTM Model Server with Demultiplexing in DAG and Custom Node features.
OpenVINOTM Model Server (OVMS) is a high-performance system for serving models that uses the same architecture and API as TensorFlow Serving and KServe while applying OpenVINOTM for inference execution. It is implemented in C++ for scalability and optimized for deployment on intel architectures.
Directed Acyclic Graph (DAG) is an OVMS feature that controls the execution of an entire graph of interconnected models defined within the OVMS configuration. The DAG scheduler makes it possible to create a pipeline of models for execution in the server with a single client request.
During the pipeline execution, it is possible to split a request with multiple batches into a set of branches with a single batch. Internally, OVMS demultiplexer will divide the data, process them in parallel and combine the results.
The custom node in OVMS simplifies linking deep learning models into complete pipeline. Custom node can be used to implement all operations on the data which cannot be handled by the neural network model. It is represented by a C++ dynamic library implementing OVMS API defined in custom_node_interface.h.
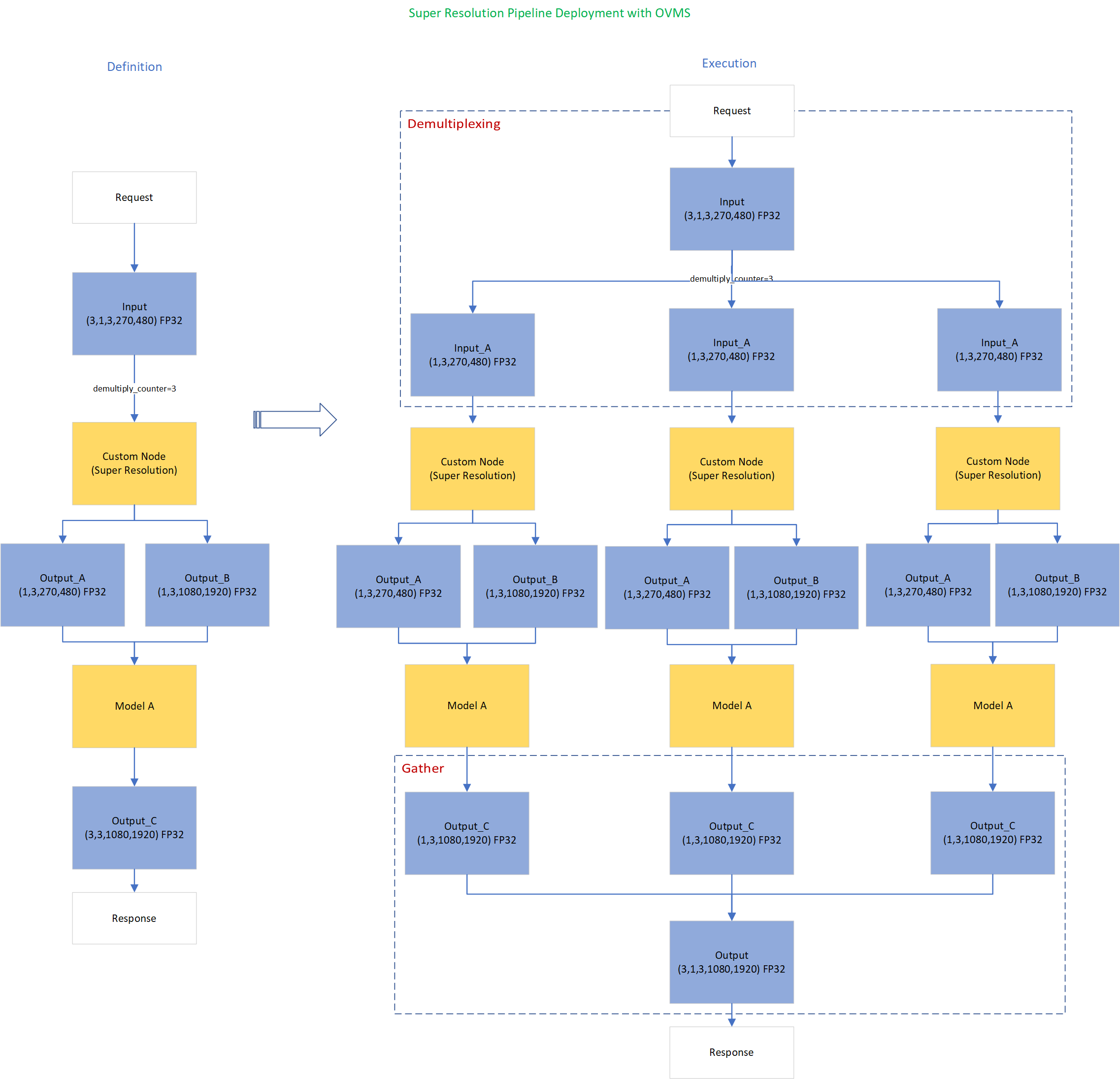
Super-Resolution Pipeline Workflow
Figure1 shows the super-resolution pipeline in a flowchart, where we use "demultiply_counter=3" without loss of generality. The whole pipeline starts with input data from the Request node via gRPC calls. Batched input data with 5D shape(3,1,3,270,480) is split into a single batch by the DAG demultiplexer. Each single batch of data is fed into a custom node for image preprocessing. The two outputs of the custom node serve as inputs for model A inference. In the end, all inference results are gathered as output C, which will be sent by the Response node to the client via gRPC calls.
Here is an example configuration for the super-resolution pipeline deployed with OVMS.
“pipeline_config_list” contains super-resolution pipeline information, data enter from the “request” node, flow to “sr_preprocess_node” for image preprocessing, generated two outputs will serve as inputs in “super_resolution_node” for inference, gathered inference results will be returned by “response” node.
- "demultiply_count": acceptable input data batch size when Demultiplexing in DAG feature enabled, “demultiply_count” with value -1 means OVMS can accept dynamic batch input data.
“model_config_list”: contains the basic configuration for super-resolution deep learning model and OpenVINOTM CPU plugin configuration.
- "nireq": set number of infer requests used in OVMS server for deep learning model
- "NUM_STREAMS": set number of streams used in the CPU plugin
- "INFERENCE_PRECISION_HINT": option to select preferred inference precision in CPU plugin. We can set "INFERENCE_PRECISION_HINT":bf16 on the Xeon platform that supports BF16 precision, such as the 4th Gen Intel® Xeon® Scalable processor (formerly codenamed Sapphire Rapids). Otherwise, we should set "INFERENCE_PRECISION_HINT":f32 as the default value.
“custom_node_library_config_list”: contains the name and path of the custom node dynamic library
Image Preprocessing with libvips in Custom Node
In this blog, we use a single-image-super-resolution model from Open Model Zoo for the super-resolution pipeline. The model requires two inputs according to the model specification. The first input is the original image (shape [1,3,270,480]). The second input is a 4x resized image with bicubic interpolation (shape [1,3,1080,1920]). Both input images expected color space is BGR. Therefore, image preprocessing for input image is required.
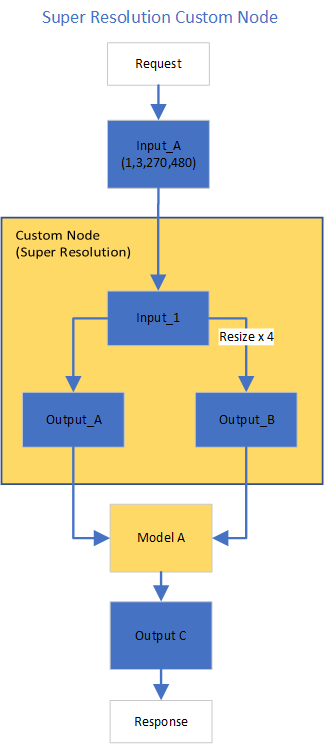
Figure2 shows the custom node designed for image preprocessing in the super-resolution pipeline. The custom node takes the original input image as input data. At first, input data is assigned to output 1 without modification. Besides, the input data is resized 4x with bicubic interpolation and assigned as output 2. The two outputs are passed to the model node for inference. For image processing in the custom node, we utilize libvips – an open-source image processing library that is designed to be fast and efficient with low memory usage. Please see the detailed custom node implementation in super_resolution_nhwc.cpp.
Although libvips is very sufficient for image processing operations with less memory, libvips does not provide functionality for layout (NCHW->NHWC) and color space (RGB->BGR) conversion, which is required by the super-resolution model as inputs. Instead, we can integrate layout and color space conversion into models using OpenVINOTM Preprocessing API.
Integrate Preprocessing with OpenVINOTM Preprocessing API
OpenVINOTM Preprocessing API allows adding custom preprocessing steps into the execution graph of OpenVINOTM models.
Here is a sample code to integrate layout (NCHW-> NHWC) and color space (BRG->RGB) conversion into the super-resolution model with OpenVINOTM Preprocessing API.
In the code snippet above, we first load the original model and initialize the PrePostProcessor object with the original model. Then we modify the model's 1st input element type to “uint8”, change the color format from the default “BGR” to “RGB”, and set the layout from “NCHW” to “NHWC”. In the end, we build a new model and serialize it on the disk. The whole model preprocessing can be done offline, please find details in model_preprocess.py.
Build Model Server Docker Image for Super-Resolution Pipeline
Build OVMS docker image with custom node
Copy compiled custom nodes library to the “models” directory
Setup client environment
Integrate preprocessing with OpenVINOTM Preprocessing API
The resulting model will be saved in the “super_resolution_model_preprocessed/1” directory.
Super-Resolution Pipeline Demo
Start the OpenVINOTM Model Server with docker binding with 8 cores
Run client with command line
Figure 3 shows the original input image (shape 270x480).

Figure 4 shows the resized image (shape 1080x1920) after image preprocessing in the custom node.

Figure 5 shows the inference result of the super-resolution model (shape1080x1920).

Conclusion
In this blog, we demonstrate an end-to-end super-resolution pipeline deployment with OpenVINOTM Model Server. The whole pipeline takes dynamic batched images (RGB, NHWC) as input, demultiplexing into single batch data, preprocess with a custom node, runs an inference with a super-resolution model, send gathered inference results to the client in the end.
This blog provides following examples that utilize OpenVINOTM Model Server and OpenVINOTM features:
- Enable OVMS DAG demultiplexing feature
- Provide custom node for image preprocessing using libvips
- Provide sample code for integrating preprocessing into the model with OpenVINOTM Preprocessing API.
- Support super-resolution end-to-end pipeline with image preprocessing and model inference with OVMS DAG scheduler