.png)
Devang
Aggarwal
Leverage the power of Model Caching in your AI Applications
Authors: Devang Aggarwal, Eddy Kim, Preetha Veeramalai
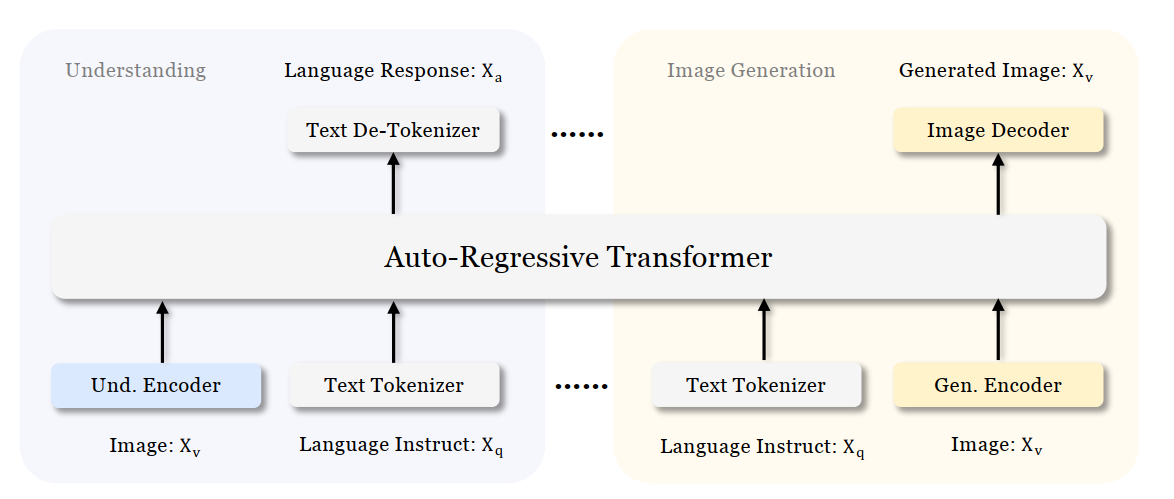
Choosing the right type of hardware for deep learning tasks is a critical step in the AI development workflow. Here at Intel, we provide developers, like yourself, with a variety of hardware options to meet your compute requirements. From Intel® CPUs to Intel® GPUs, there are a wide array of hardware platforms available to meet your needs. When it comes to inferencing on different hardware, the little things matter. For example, the loading of deep learning models, which can be a lengthy process and can lead to a difficult user experience on application startup.
Are there ways to achieve faster model loading time on such devices?
Short answer is, yes, there are ways; one way is to handle the model loading time. Model loading performs several time-consuming device-specific optimizations and network compilations, which can also result in developers seeing a relatively higher first inference latency. These delays can lead to a difficult user experience during application startup. This problem can be solved through a mechanism called Model Caching. Model Caching solves the issue of model loading time by caching the final optimized model directly into a file. Reusing cached networks can significantly reduce the model loading time.
Model Caching
With OpenVINO 2022.3, model caching is currently implemented as a preview feature. To accelerate first inference latency on Intel® GPU, not only should the kernel source code be compiled in a form that can be executed on the GPU, but also various optimization passes must be performed. Kernel caching reuses only the kernels, but model caching reuses even the output of the optimization passes, so the model loading time can be further reduced. Before model caching, kernel caching was used in the same manner: by setting the CACHE_DIR configuration key to a folder where the cache should be stored. Now, to use the preview feature of model caching, set the OV_GPU_CACHE_MODEL environment variable to 1. Since the extension of the cache file created by kernel caching is “cl_cache” and the extension of the cache file created by model caching is “blob”, it is possible to check whether model caching is activated through this.
Note: Currently this is a preview feature with OpenVINO 2022.3. This feature will be fully available in OpenVINO 2023.0.
Developers can now also leverage this preview feature from OpenVINO™ Toolkit in OpenVINO™ Execution Provider for ONNX Runtime, a product that accelerates inferencing of ONNX models using ONNX Runtime API’s while using the OpenVINO™ toolkit as a backend. With the OpenVINO™ Execution Provider, ONNX Runtime delivers better inferencing performance on the same hardware compared to generic acceleration on Intel® CPU, GPU, and VPU. Additionally, by using model caching, OpenVINO™ Execution Provider can speed up the first inference latency of deep learning models on Intel® GPU.
In OpenVINO™ Execution Provider for ONNX Runtime, the model caching feature can been abled by setting the ONNX Runtime config option ‘use_compiled_network’ to True while using the C++/Python API’s. This config option acts like a switch to enable and disable the model caching feature that saves the final optimized model into a .blob file during the very first inference of the model on Intel® hardware.
The blobs are loaded from a directory named ‘ov_compiled_blobs’ relative to the executable path by default. This path however can be overridden using the ONNX Runtime config option ‘blob_dump_path’ which is used to explicitly specify the path where you would like to dump and load the blobs files from when already using theuse_compiled_network (model caching) setting.
Refer to Configuration Options for more information about using these options.
Conclusion
With the Model Caching feature, the deep learning model loading time should significantly decrease. You can now utilize this feature in both the Intel® Distribution of OpenVINO™ Toolkit and OpenVINO™ Execution Provider for ONNX Runtime and experience better first inference latency for your AI models.
Notices & Disclaimers
Intel technologies may require enabled hardware, software or service activation.
No product or component can be absolutely secure.
Your costs and results may vary.
©Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or itssubsidiaries. Other names and brands maybe claimed as the property of others.