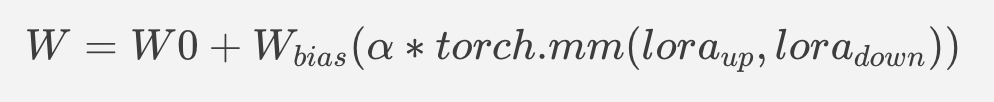Deploying deep-learning capabilities to edge devices can present security challenges like ensuring inference integrity, or providing copyright protection of your deep-learning models. OpenVINO provide a simple method with crypto algorithm to protect model in disk. Model encryption, decryption and authentication are not provided by OpenVINO but can be implemented with third-party tools (i.e., OpenSSL). In this example, we use AES-128-cbc algorithm in OpenSSL to demonstrate the model cryptography.
As you can see the mechanism in below image, there are two part to process:
First is to encrypt your plain IR model into encrypted model.
The second part is to use the same password key and IV which used for encryption before to decrypt model at model loading runtime.
The schema of model encryption and decryption by OpenVINO
Step 1: Encrypt model
Make sure you install the OpenSSL and boost, for example in Ubuntu:
$ sudo apt install openssl libboost-dev
Then use command line to do model encryption by OpenSSL AES-128-CBC algorithm. In this simply example, I use same password for Key and IV, it is hexadecimal of string "openvino encrypt". You can use some online str2hex tool to generate hex representation of your string password.
This blog just provide an example of model encryption by OpenSSL. This method can only protect you model in disk, for total memory crypto, you can refer technologies like OpenVINO™ Security Add-on in virtual machine to provide an isolated environment for security sensitive operations, and use Intel® SGX (Software Guard Extensions) which allows developers to split a computer's memory into private, predefined, highly secure areas called enclaves, which better protect sensitive information.
Latent Consistency Models (LCMs) is the next generation of generative models after Latent Diffusion Models (LDMs). While Latent Diffusion Models (LDMs) like Stable Diffusion are capable of achieving the outstanding quality of generation, they often suffer from the slowness of the iterative image denoising process. LCM is an optimized version of LDM. Inspired by Consistency Models (CM), Latent Consistency Models (LCMs) enabled swift inference with minimal steps on any pre-trained LDMs, including Stable Diffusion. The Consistency Models is a new family of generative models that enables one-step or few-step generation. More details about the proposed approach and models can be found using the following resources: project page, paper, original repository.
This article will demonstrate a C++ application of the LCM model with Intel’s OpenVINO™ C++ API on Linux systems. For model inference performance and accuracy, the C++ pipeline is well aligned with the Python implementation.
To leverage efficient inference with OpenVINO™ runtime on Intel platforms, the original model should be converted to OpenVINO™ Intermediate Representation (IR).
from optimum.intel.openvino import OVLatentConsistencyModelPipeline
model = OVLatentConsistencyModelPipeline.from_pretrained("SimianLuo/LCM_Dreamshaper_v7", export=True)
model.save_pretrained("ov_lcm_model")
Tokenizer
OpenVINO Tokenizers is an extension that adds text processing operations to OpenVINO Inference Engine. In addition, the OpenVINO Tokenizers project has a tool to convert a HuggingFace tokenizer into OpenVINO IR model tokenizer and detokenizer: it provides the convert_tokenizer function that accepts a tokenizer Python object and returns an OpenVINO Model object:
from transformers import AutoTokenizer
from openvino_tokenizers import convert_tokenizer
from openvino import compile_model, save_model
hf_tokenizer = AutoTokenizer.from_pretrained(tokenizer_path)
ov_tokenizer_encoder = convert_tokenizer(hf_tokenizer)
save_model(ov_tokenizer_encoder,"ov_tokenizer.xml")
Note: Currently OpenVINO Tokenizers can be inferred on CPU devices only.
Note: The tutorial assumes that the current working directory is and <openvino.genai repo>/image_generation/lcm_ dreamshaper_v7/cpp all paths are relative to this folder.
Let’s prepare a Python environment and install dependencies:
Now we can use the script scripts/convert_model.py to download and convert models:
cd scripts
python convert_model.py -lcm "SimianLuo/LCM_Dreamshaper_v7" -t FP16
C++ Pipeline
Pipeline flow
Let’s now talk about the logical structure of the LCM model pipeline.
Just like the classic Stable Diffusion pipeline, the LCM pipeline consists of three important parts: - A text encoder to create a condition to generate an image from a text prompt. - U-Net for step-by-step denoising the latent image representation. - Autoencoder (VAE) for decoding the latent space to an image.
The pipeline takes a latent image representation and a text prompt transformed to text embedding via CLIP’s text encoder as an input. The initial latent image representation is generated using random noise generator. LCM uses a guidance scale for getting time step conditional embeddings as input for the diffusion process, while in Stable Diffusion, it used for scaling output latents.
Next, the U-Net iteratively denoises the random latent image representations while being conditioned on the text embeddings. The output of the U-Net, being the noise residual, is used to compute a denoised latent image representation via a scheduler algorithm. LCM introduces its own scheduling algorithm that extends the denoising procedure introduced by denoising diffusion probabilistic models (DDPMs) with non-Markovian guidance. The denoising process is repeated for a given number of times to step-by-step retrieve better latent image representations. When complete, the latent image representation is decoded by the decoder part of the variational auto encoder.
The C++ implementations of the scheduler algorithm and LCM pipeline are available at the following links: LCM Scheduler, LCM Pipeline.
The main idea for LoRA weights enabling, is to append weights onto the OpenVINO LCM models at runtime before compiling the Unet/text_encoder model. The method is to extract LoRA weights from safetensors file, find the corresponding weights in Unet/text_encoder model and insert the LoRA bias weights. The common approach to add LoRA weights looks like:
And finally we’re ready to run the LCM demo. By default the positive prompt is set to: “a beautiful pink unicorn”.
Please note, that the quality of the resulting image depends on the quality of the random noise generator, so there is a difference for output images generated by the C++ noise generator and the PyTorch generator. Use oprion -r to read the PyTorch generated noise from the provided textfiles for the alignment with Python pipeline.
Note: Run ./lcm_dreamshaper -h to see all the available demo options
Let’s try to run the application in a few modes:
Read the numpy latent input and noise for scheduler instead of C++ std lib for the alignment with Python pipeline: ./lcm_dreamshaper -r
Generate image with C++ std lib generated latent and noise : ./lcm_dreamshaper
Generate image with Soulcard LoRa and C++ generated latent and noise: ./lcm_dreamshaper -r -l path/to/soulcard.safetensors
The OpenVINO™ Benchmark Application estimates deep learning inference performance on supported devices for synchronous and asynchronous modes.
NOTE: This guide describes the usage of the C++ implementation of the Benchmark Tool. For the Python implementation, refer to the Benchmark Python Tool page. The Python version is recommended for benchmarking models used in Python applications, and the C++ version is recommended for benchmarking models used in C++ applications.
In this tutorial, we will guide you through building and running the C++ implementation of the Benchmark Tool on Ubuntu with OpenVINO™ 2023.1.0 release and demonstrate its usage by benchmarking the Inception (GoogleNet) V3 deep learning model. The following steps outline the process:
Download and Convert the Model
Install OpenVINO™ Runtime
Build OpenVINO™ C++ Runtime Samples
Run the Benchmark Application
The benchmark application works with models in the OpenVINO™ IR (.xml and .bin), ONNX (.onnx), TensorFlow (*.pb), TensorFlow Lite (*.tflite) and PaddlePaddle (*.pdmodel) formats. Make sure to convert your models if necessary (see "Model conversion to OpenVINO™ IR format" step below).
Requirements
Before getting started, ensure that you have the following requirements in place:
Ubuntu 18.04 or higher
CMake version 3.10 or higher
Step 1: Install OpenVINO™
To get started, first install OpenVINO™ Runtime C++ API.
Download and Setup OpenVINO™ Runtime archive file for Linux for your system. The following steps describe the installation process for Ubuntu 20.04 x86_64 system:
1. Download the archive file, extract the files, rename the extracted folder, and move it to the desired path:
2. Install required system dependencies on Linux. To do this, OpenVINO provides a script in the extracted installation directory. Run the following command:
cd /opt/intel/openvino_2023.1.0sudo -E ./install_dependencies/install_openvino_dependencies.sh
3. For simplicity, it is useful to create a symbolic link as below:
cd /opt/intelsudo ln -s openvino_2023.1.0 openvino_2023
4. Set OpenVINO™ environment variables. Open a terminal window and run the setupvars.sh script to temporarily set your environment variables. If your <INSTALL_DIR> is not /opt/intel/openvino_2023, use the correct one instead:
source /opt/intel/openvino_2023/setupvars.sh
Step 2: Build OpenVINO™ C++ Runtime Samples
In the existing terminal window where the OpenVINO™ environment is set up, navigate to the /opt/intel/openvino_2023.1.0/samples/cpp directory and run the /build_samples.sh script:
cd /opt/intel/openvino_2023.1.0/samples/cpp./build_samples.sh
As a result of a successful build, you'll get the message with a path to the sample binaries:
...[100%] Linking CXX executable ../intel64/Release/benchmark_app[100%] Built target benchmark_app[100%] Built target ie_samplesBuild completed, you can find binaries for all samples in the /home/user/openvino_cpp_samples_build/intel64/Release subfolder.
NOTE: You can also use the -b option to specify the sample build directory and -i to specify the sample install directory, for example:
NOTE: The build_samples.sh script will build all the samples in the /opt/intel/openvino_2023.1.0/samples/cpp folder. Remove the other samples from the folder if you want to build only a few samples or only the benchmark_app.
Step 3: Run the Benchmark Application
NOTE: You can use your model for benchmark running or if necessary download model for demo using the Model Downloader. You can find pre-trained models from either public models or Intel’s pre-trained modelsfrom the OpenVINO™ Open Model Zoo. Following are the steps to install the tools and obtain the IR for the Inception (GoogleNet) V3 PyTorch model:
The googlenet-v3-pytorch IR files will be located at: <CURRENT_DIRECTORY>/public/googlenet-v3-pytorch/FP32
Navigate to the samples binaries folder and run the benchmark_app with the following command:
cd /home/user/openvino_cpp_samples_build/intel64/Release./benchmark_app -m path/to/public/googlenet-v3-pytorch/FP32/googlenet-v3-pytorch.xml
By default, the application will load the specified model onto the CPU and perform inferencing on batches of randomly generated data inputs for 60 seconds. As it loads, it prints information about benchmark parameters. When benchmarking is completed, it reports the minimum, average, and maximum inferencing latency and average the throughput.
NOTE: You can use images from the media files collection available at test_data and infer with specific input data using the -i argument to benchmark_app.
You may be able to improve benchmark results beyond the default configuration by configuring some of the execution parameters for your model. Please find other options for configuring execution parameters here: Benchmark C++ Tool Configuration Options
Model conversion to OpenVINO™ IR format
You can use OpenVINO™ Model Converter to convert your model to Intermediate Representation (IR) when necessary:
1. Install OpenVINO™ for Python which includes the necessary components for utilizing the OpenVINO™ Model Converter.
NOTE: Ensure you install the same version of OpenVINO™ Runtime Package for Python as the OpenVINO™ Runtime C++ API in step 2.
pip install "openvino>=2023.1.0"
2. To convert the model to IR, run Model Converter:
GroundingDINO introduces a language-guided query selection module to enhance object detection using input text. This module selects relevant features from image and text inputs and uses them as decoder queries. In this blog, we provide the OpenVINO™ optimization for GroundingDINO on Intel® platforms.
The public GroundingDINO project is referenced from: GroundingDINO
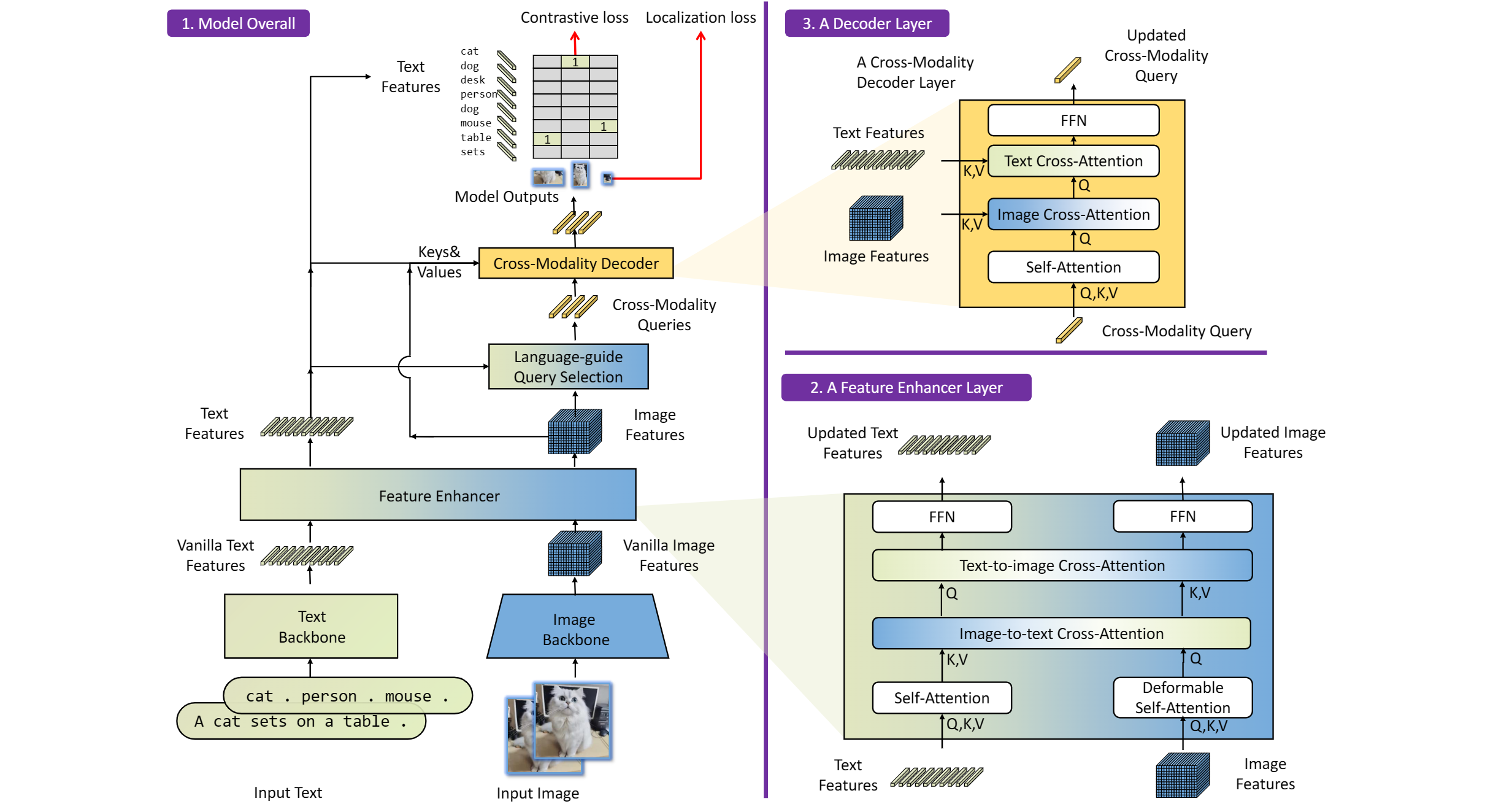
The GroundingDINO refer the model structure in below picture:
Figure 1. The framework of Grounding DINO. We present the overall framework, a feature enhancer layer, and a decoder layer in block 1,block 2, and block 3,respectively.
OpenVINO™ backend on GroundingDINO
In this project, you do not require to download OpenVINO™ and build the library with GroundingDINO project manually. It’s already fully integrated with OpenVINO™ runtime library for downloading, program compiling and linking.
At present, this repository already optimized and validated by OpenVINO™ 2023.1.0.dev20230811 version. Check the operating system which can support OpenVINO™ runtime library directly:
Ubuntu 22.04 long-term support (LTS), 64-bit (Kernel 5.15+)
Ubuntu 20.04 long-term support (LTS), 64-bit (Kernel 5.15+)
Ubuntu 18.04 long-term support (LTS) with limitations, 64-bit (Kernel 5.4+)
Windows* 10
Windows* 11
macOS* 10.15 and above, 64-bit
Red Hat Enterprise Linux* 8, 64-bit
Step 1: Install system dependency and setup environment

.png)