

OpenVINO Blog

Use Encrypted Model with OpenVINO
Deploying deep-learning capabilities to edge devices can present security challenges like ensuring inference integrity, or providing copyright protection of your deep-learning models. OpenVINO provide a simple method with crypto algorithm to protect model in disk. Model encryption, decryption and authentication are not provided by OpenVINO but can be implemented with third-party tools (i.e., OpenSSL). In this example, we use AES-128-cbc algorithm in OpenSSL to demonstrate the model cryptography.
As you can see the mechanism in below image, there are two part to process:
- First is to encrypt your plain IR model into encrypted model.
- The second part is to use the same password key and IV which used for encryption before to decrypt model at model loading runtime.

Step 1: Encrypt model
Make sure you install the OpenSSL and boost, for example in Ubuntu:
Then use command line to do model encryption by OpenSSL AES-128-CBC algorithm. In this simply example, I use same password for Key and IV, it is hexadecimal of string "openvino encrypt". You can use some online str2hex tool to generate hex representation of your string password.
Step 2: Decrypt model
Here provide the sample code to read encrypted model into buffer and decrypt to plain model binary. Then read and compile model.
CMakeLists.txt file like below for compiling:
This blog just provide an example of model encryption by OpenSSL. This method can only protect you model in disk, for total memory crypto, you can refer technologies like OpenVINO™ Security Add-on in virtual machine to provide an isolated environment for security sensitive operations, and use Intel® SGX (Software Guard Extensions) which allows developers to split a computer's memory into private, predefined, highly secure areas called enclaves, which better protect sensitive information.
Reference:
- OpenVINO model protection: https://docs.openvino.ai/2023.1/openvino_docs_OV_UG_protecting_model_guide.html
- OpenVINO™ Security Add-on: https://docs.openvino.ai/2023.1/ovsa_get_started.html
- OpenSSL official website: https://www.openssl.org/
Intel® DL Streamer Optimize Media-AI pipeline on Intel® Data Center Flex dGPU by Docker
Authors Kunda Xu, Wenyi Zou
Introduction
In this blog is about How to use DL-streamer to build a complete Media-AI pipeline (Including: Video Access, Media Decode, AI Inference, Media Encode and Result Export). And the pipeline will be accelerated by OpenVINO™ and optimize to run on Flex dGPU(Intel® Data Center Flex dGPU)
Requirement
- DL-streamer
Intel® Deep Learning Streamer (Intel® DL Streamer)Pipeline Framework is an easy way to construct media analytics pipelines using Intel® Distribution of OpenVINO™ Toolkit. It leverages the open source media framework GStreamer to provide optimized media operations and Deep Learning Inference Engine from OpenVINO™ Toolkit to provide optimized inference.
- OpenVINO
OpenVINO™ is an open-source toolkit for optimizing and deploying AI inference which can boost deep learning performance in computer vision, automatic speech recognition, natural language processing and other common task.
- Docker (Optional)
Docker is an open-source platform that enables developers to build, deploy, run, update, and manage containers—standardized, executable components that combine application source code with the operating system (OS) libraries and dependencies required to run that code in any environment.
Install DL-Streamer and OpenVINO™ via Docker
Images for Intel® Data Center GPU Flex Series
Images 2023.0.0-ubuntu22-gpu682* are intended for Intel® Data Center GPU Flex Series and include
3. Drivers for Intel® Data Center GPU Flex Series, drivers version 682.14
Two images are listed below, images -devel additionally contain samples and development files
Runtime image that includes GStreamer* Pipeline Framework elements, elements built with Intel® oneAPI DPC++/C++ Compiler
Developer image that builds on runtime image containing samples, development files and a model downloader, built with Intel® oneAPI DPC++/C++ Compiler
Taking “dlstreamer:2023.0.0-ubuntu22-gpu682-dpcpp” docker images as a sample to show how to pull the docker image from docker hub.
DL-Streamer Media-AI pipeline quick start example
Make sure the pre-requirement had already installed, there is a very basic introduction to using object detection models(yolov5) to build a DL-streamer pipeline.
Step 1.Download video and yolov5s model file
Download video
Download yolov5s-416_INT8 model from pipeline-zoo-models
Step 2.Enter Docker and copy the files into docker container
Create and enter the docker container
Open another terminal for file copy into container ,copy video and model into docker container
Step 3. Run an object detection Media-AI pipeline
By the following script, we can run pipeline the Media-AI objection detection on the Flex dGPU in the docker container.
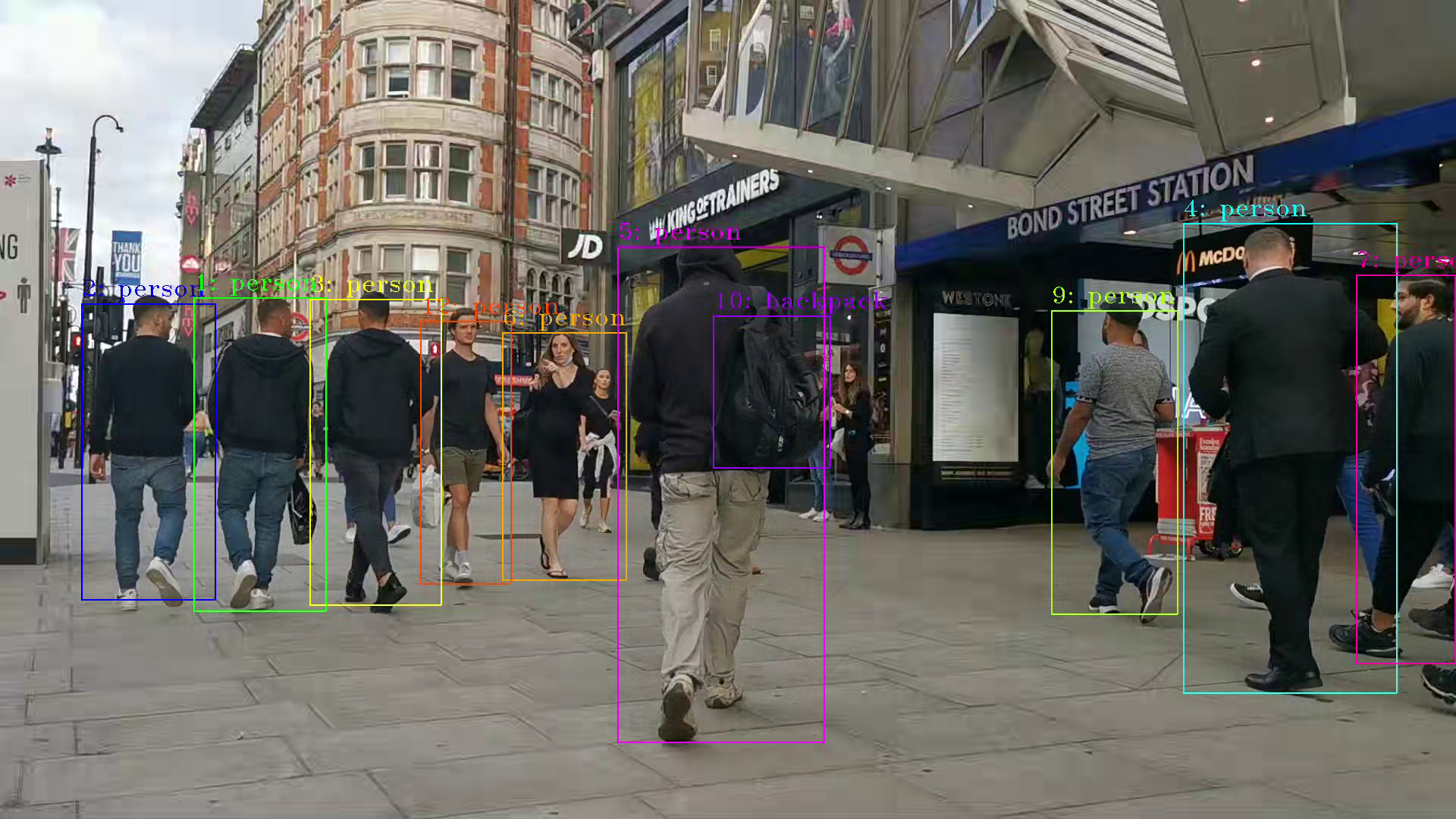
If want to encode the detection result and save as video file, can use the follow script
The encoded video file will save in the container and can be copied out in new terminal.
PS. Instruction about DL-streamer CLI parameter
decodebin: Auto-magically constructs a decoding pipeline using available decoders and demuxers via auto-plugging.
vaapipostproc: Consists in various post processing algorithms to be applied to VA surfaces. For e.g. scaling, deinterlacing (bob, motion-adaptive, motion-compensated), noise reduction or sharpening.
gvadetect: Performs object detection on a full-frame or region of interest (ROI) using object detection models such as YOLO v3-v5, MobileNet-SSD, Faster-RCNN etc. Outputs the ROI for detected objects.
gvatrack: Performs object tracking using zero-term, zero-term-imageless, or short-term-imageless tracking algorithms. Zero-term tracking assigns unique object IDs and requires object detection to run on every frame. Short-term tracking allows to track objects between frames, there by reducing the need to run object detection on each frame. Imageless tracking forms object associations based on the movement and shape of objects, and it does not use image data.
gvafpscounter: Measures frames per second across multiple streams in a single process.
Tuning Tips
Users can refer the different platform using case which were supported by OpenVINO™ and the device profiling API to realize performance tuning of your inference program between CPU, iGPU, dGPU. It will also be helpful to developer finding out the place where has the potential space of performance improvement.
Build OpenVINO on Kylin OS Guide
Authors: Tong Qiu, Wenyi Zou
Kylin is an operating system based on Linux, developed by academics at the National University of Defense Technology in the People's Republic of China. For more information about Kylin OS, please visit the Wikipedia page at Kylin. In the following sections, we will provide a step-by-step guide to building and running OpenVINO on the Kylin Operating System.
System
The version of Kylin OS we are using is “Kylin HostOS V10”, with the specific version being “V10 (Helium)”. You may obtain this information by executing the command:
We build OpenVINO using GCC 10.3.1, CMake 3.26.0, and Python 3.9.9, which can all be installed by default using command lines. Next, we will demonstrate how to install these necessary dependencies.
Install Build Dependencies
Instead of executing the ./install_build_dependencies.sh script referenced in Build OpenVINO™ Runtime for Linux systems, you can directly install the build dependencies using the following command lines:
Setup Python Virtual Environment
The next step is to create and activate a Python virtual environment. While this step is optional, we strongly recommend it to ensure better management of your project's dependencies.
Following the completion of the steps to build OpenVINO within the Python virtual environment, you can activate OpenVINO alongside the Python virtual environment each time by executing the source command.
Build OpenVINO with CMake 3.26.0 and GCC 10.3.1
Now we've reached the step to build OpenVINO. First, clone the OpenVINO repository and update its submodules.
Next, install the Python dependencies that are required for building Python wheels.
Then, create the build directory.
To build OpenVINO with CMake, start by using the command provided below. For enhanced performance, it is recommended to append the -DCMAKE_CXX_FLAGS=-march=native to your command, as this will enable the compiler to optimize the build for your specific hardware by using all supported instruction subsets. Additionally, if you require a Python wheel, include the corresponding build option. Remember to tailor the CMake parameters to fit your particular requirements.
Once the build process is complete, you can install the generated wheel using the pip command.
Quick test for built openvino runtime and openvino-dev tools
You can quickly verify your built and installed OpenVINO setup. Start by creating a model directory and installing the dependencies for the model optimizer.
Next, download the resnet50 pytorch model using omz_downloader.
Then, convert resnet50 pytorch model to OpenVINO FP32 IR via omz_converter.
Finally, execute benchmark_app with resnet50 FP32 IR model on CPU.
Additional Details for OpenVINO Setup
If you prefer to build OpenVINO with a different compiler, such as clang, you can modify the CMake configuration step accordingly. To build with the clang compiler, please refer to the website at Clang - Getting Started for instructions on installation and setup. Below is an example of a CMake generation command that specifies clang as the compiler:

Creating AI Pipeline for Cell Image Analysis: Insights, Challenges, and CHO Use Case (Part 1 of 2, Intel Edge AI in the Realm of Biopharma and Drug Development)
In the ever-evolving landscape of biopharmaceutical technology and drug development, a recent effort in the field of Cell Analytics for Monoclonal Antibody Production has shed light on the crucial role of Edge AI Technology in navigating complex challenges of scaling and producing solutions.
In this 2-part blog series, we will explore the use of Intel Edge AI Technology in biopharma and drug development, addressing challenges and providing insights into the development of AI pipelines for cell segmentation and analysis.
Intel has been involved in this process with a variety of partners. One of Intel’s contributions to the cell image project centers around processing brightfield1 images using an AI pipeline containing multiple deep learning models. The pipeline's purpose is to identify cells and other biological components and provide feedback on dynamic biological characteristics such as cell morphology, viability, and phenotypic changes, among others. Throughout this process, working on cell-AI projects usually brings a unique set of challenges to the forefront.
First, it is an interdisciplinary field and the knowledge gap between data scientists and biopharma experts requires more back-and-forth clear communications for planning and validity checks. Frequently when attempting to implement AI solutions in the laboratory, data scientists and bench scientists struggle to fully grasp the nature and needs of each other’s role. This lack of mutual understanding can also hinder the usability and scalability of an AI solution needing to be integrated into diverse lab environments.
The second challenge is instrument variability. Different plate reader2 microscopes have different hardware, optics, and apertures which cause their produced images not to be consistent. This adds an extra layer of work to assess and address these inconsistencies along the way (like regular tracked calibration and adjustment). Additionally, equipment vendor-to-vendor differences, culture temperature, medium conditions, and genetic modifications can all affect the variability of data and the inherent transferability of the deep learning pipeline. This would drive the need to monitor the performance of DL models at the edge and cloud ML ops components.
The third challenge is obtaining peer-review labels because the process is based on supervised Machine Learning and obtaining clean accurate labels is very costly and time-consuming.
And the last challenge is about the model deployment. In most cases, cloud deployment is not an option due to data size and data privacy. Produced images from plate reader microscopes are huge and transferring data to the cloud and sending the results back would create high latency because a huge amount of data must be streamed (30Gb per hour). And more importantly, laboratories are usually not willing to share the data. Due to these two constraints, cloud deployments are not usually an option, and the pipeline must be deployed at the edge.
Now, let’s talk about a specific application of this technology: the CHO Cell Segmentation Use Case.
CHO Cell Segmentation Use Case
CHO cells, or Chinese Hamster Ovary cells, are a cornerstone in the production of complex protein molecules such as monoclonal antibodies, fusion proteins, hormones, and coagulation factors. Unlike stem cells or CAR-T cells, where the cells themselves are the therapeutic product, in CHO cells, it is the proteins they produce that are of paramount importance. Monitoring the health, viability, and production capability of these cells is a critical step in commercial protein production.
Traditionally, assessing the condition of CHO cells involves a multi-step process that is not only time-consuming but also requires the use of expensive reagents and chemicals. Depending on the process, the workflow can be something like below.
- Culture cells
- Fix cells – wash in expensive reagents to remove the culture medium.
- Permeabilization – wash in more expensive chemicals to permeabilize the cell membrane (to stain for intercellular proteins).
- Blocking – incubate cells in another expensive reagent to prevent binding of no specific antibodies.
- Primary Antibody Incubation – antibody specifically to bind to a protein that is being produced.
- Washing – removing unbound Primary Antibodies using more expensive chemicals.
- Nuclear staining – use nuclear stain like DAPI to visualize cell nuclei then wash with the same chemicals from the washing step
- Mounting – get ready to read in the microscope (plate reader1)
- Imaging – Stained cells …. count them up and determine the state in the protein production cycle and relative cell health (eventually they peter out and stop producing and the batch needs to be flushed. (Cell count, viability number, etc. are the output not the image)
From culturing to imaging, each step plays a vital role in ensuring the quality of the protein product. However, with the advent of AI and deep learning, there is an opportunity to streamline this workflow significantly. Using an AI pipeline including multiple Deep Learning models and data pre and post-processing, we can go from Step 1 directly to Step 9, removing the majority of the labor and latency in getting actionable results out of a staining workflow and bypassing expensive specialty chemicals requirement. Intel has put together a reference implementation for deploying said pipeline and inferencing of these images on the edge as part of the Cell Image project https://www.cellimage.ie/. OpenVINO Toolkit, OpenVINO Model Server, and AI Connect for Scientific Data are used in this design. Let’s briefly talk about each of these wonderful SW packages in part 2 of this article series. Stay tuned!
Conclusion
In conclusion, the integration of Intel Edge AI Technology into the biopharmaceutical sector represents a transformative step towards more efficient and scalable drug development processes. As we have seen in this first installment of our blog series, the deployment of AI pipelines for cell segmentation and analysis in monoclonal antibody production is not without its challenges. These include bridging the interdisciplinary knowledge gap, managing instrument variability, acquiring peer-reviewed labels, and overcoming the hurdles associated with model deployment.
Despite these challenges, the potential benefits of Edge AI in biopharma are substantial. By leveraging Intel's advanced AI technologies, we can significantly reduce the time and cost associated with traditional cell analysis methods, while also enhancing the accuracy and reliability of the results. The use of edge computing addresses the concerns of data size and privacy, allowing for real-time processing and analysis without the need for cloud transfer.
As we move forward in this blog series, we will delve deeper into the specifics of Intel's Edge AI solutions, including the OpenVINO toolkit, OpenVINO Model Server, and AI Connect for Scientific Data. We will explore how these tools are being applied in real-world scenarios to drive innovation and improve outcomes in the realm of biopharma and drug development in the next part of this series.
Reach out to Intel's Health and Life Sciences team at health.lifesciences@intel.com or learn more about what we do at https://www.intel.com/health.

We'd like to hear from you! Let us know in the comments or discuss – which AI use cases in health and life sciences do you think will have the greatest impact on global health?
If you enjoyed hearing from the Health and Life Sciences team and want to hear more, give this post a like and ensure you subscribe to get the latest updates from the team.
About the Author
Nooshin Nabizadeh has Ph.D. in Electrical and Computer Engineering from the University of Miami and works at Intel Corporation as AI Solutions Architect. She enjoys photography, writing poetry, reading about psychology and philosophy, and optimizing solutions to run as fast as possible on a given piece of hardware. Connect with her on LinkedIn https://www.linkedin.com/in/nooshin-nabizadeh/ by mentioning this blog.
- Brightfield microscopy is a widely used technique for observing the morphology of cells and tissues.
- A plate reader is a laboratory instrument used to obtain images from samples in microtiter plates. The reader shines a specific calibrated frequency of light (UV, visible, fluorescence, etc.) through the samples in the wells of the plate. Plate reader microscopy data sets have inherent variability which drives the requirement of regular tracked calibration and adjustment.
Creating AI Pipeline for Cell Image Analysis: Intel Edge AI SW Solutions (Part 2 of 2, Intel Edge AI in the Realm of Biopharma and Drug Development)
Welcome back to our blog series on"Intel Edge AI in the Realm of Biopharma and Drug Development." Inthe first installment, we discussed the importance of Cell Analytics forAntibody Production in biopharmaceutical technology and drug development. Wehighlighted how AI pipelines are used to process brightfield images of cells,providing insights and addressing challenges in this field. Specifically, weexplored the CHO Cell Segmentation Use Case and noted that Intel has developeda reference implementation for deploying the CHO Cell Segmentation pipelineusing Intel edge AI software solutions.
Now, let's delve deeper into thespecifics of these Edge AI solutions: the OpenVINO toolkit, OpenVINO ModelServer, and AI Connect for Scientific Data. We'll explore how each of thesetools can play a crucial role in advancing biopharma and drug development.
OpenVINO™Toolkit
optimizes, tunes, and runscomprehensive deep learning inferencing on general-purpose Intel architecture. Itis an open-source toolkit that accelerates AI inference with lower latency andhigher throughput while maintaining accuracy, reducing model footprint,and optimizing hardware use. It streamlines AI development and integration ofdeep learning in domains like computer vision, large language models (LLM), andgenerative AI.
At the core of the OpenVINOtoolkit, we have the OpenVINO Runtime that loads and runs the models.The run-time employs plugins that are responsible for efficiently executing low-leveloperations that the deep learning model has on Intel HW. We have differentplug-ins for different HW, like CPU plugins, GPU plugins, and heterogeneousplugins.
The CPU plugin achieves a highperformance of neural networks on the CPU, using the Intel® Math Kernel Libraryfor Deep Neural Networks (Intel® MKL-DNN).
The GPU plugin uses the Intel® ComputeLibrary for Deep Neural Networks (clDNN) to infer deep neural networks on GPUs.
The heterogeneous plugin enablescomputing the inference of one network on several devices. The purposes ofexecuting networks in heterogeneous mode are to:
· Utilize the power of accelerators to processthe heaviest parts of the network and to execute unsupported layers on fallbackdevices like the CPU.
· Utilize all available hardware moreefficiently during one inference.
Another part of the OpenVINO toolkitis the model optimizer which optimizes and converts the model frompopular deep learning frameworks like TensorFlow, PyTorch, and ONNX, to OpenVINOintermediate representation format. The models are optimized withtechniques such as quantization, freezing, fusion, and more. Models can bedeployed across a mix of Intel® hardware and environments, on-premise andon-device, in the browser, or the cloud.
Besidesinference, OpenVINO provides the NeuralNetwork Compression Framework (NNCF) tool for implementing compressionalgorithms on models during training.

Figure1: OpenVINO™ overview. For detailed documentation about OpenVINO™ see: https://www.intel.com/content/www/us/en/developer/tools/openvino-toolkit/overview.html.
OpenVINO™ Model Server (OVMS)
When it comes to deployment, youcan use OpenVINO Runtime, or you can use OpenVINO Model Server orOVMS for short.
OVMS is a scalable,high-performance tool for serving AI models and pipelines. It centralizes AI modelmanagement, ensuring consistent AI models across numerous devices, clouds,or compute nodes. Simply put, OVMS is a microservice that loads yourmodels, manages them, and exposes their capabilities through a network API,allowing other system components to interact with and utilize these models.OVMS supports two types of APIs—TensorFlow Serving and KServe compatible—whichprovide inference, model status, and model metadata services via gRPC orRESTful API2.
Why choose OVMS over OpenVINORuntime? There are several scenarios where OVMS is the better option. OpenVINOis a C++ project with an official Python binding, but what if your softwarestack is in another language? Implementing your own interface can be challenging.OVMS simplifies this by integrating OpenVINO into your system with pre-existingcapabilities. Additionally, if your system already operates in a microserviceparadigm, OVMS is an obvious choice. You might also prefer not to integrateOpenVINO directly into the business logic of other components or deal with thecomplexities of building the system. Moreover, if some applications run on lesspowerful devices, such as mobile phones, and you want to offload heavyinferencing to more powerful machines, OVMS can handle this by exposing anetwork API. Your components can run on multiple devices, sending data requeststo OVMS and receiving model outputs in response.
OVMS is ideal for scaling yoursolution. For instance, in a multi-node Kubernetes cluster, you can createmultiple replicas and set a load balancer in front of them, achieving highavailability and throughput beyond the capability of a single node. Thisaggregation is easily managed by OVMS.
For security and privacy, OVMSallows you to host your model server on a trusted machine, ensuring that otherapplications accessing it cannot see the model itself—only the exposed interface.
Besides these, for security andprivacy purposes OVMS enables you to host your model server on a machinethat you trust, and all the other applications that access it from inside oroutside cannot see your model. you just expose its interface with otherapplications and they can’t access or see the model.

Figure2. OpenVINO Model Server
Let’s examine the OVMS structure (Figure2). At the top, we have a network interface with gRPC and RESTful endpointssupporting TF Serving API and KServe API for inference and metadata calls.Metadata provides information on expected model inputs and outputs.
At next level, we haveconfiguration monitoring, scheduler, and model management. OVMS can servemultiple models simultaneously, specified in a configuration file, withbuilt-in model management and versioning. The model files don’t need to resideon a local file system; OVMS supports remote storage systems likeGoogle Cloud, AWS S3, and Azure. For learning more about OVMS please visit here.
AIConnect for Scientific Data (AiCSD)
AI Connect for Scientific Data (AiCSD)is an open-source software sample that connects data from scientificinstruments to AI pipelines and runs workloads at the edge.
It also manages pipelines for imageprocessing and automated image comparisons. AiCSD is a containerizedmicroservices-based solution utilizing open-source EdgeX Services and connectedby a secure Redis Message Broker and various communication APIs, whichmakes it adaptable for different use cases and settings. Figure 3 shows theservices created for this reference implementation.
The architectural components of AiCSDinclude:
· Microservices: Provided by Intel, themicroservices include a user interface and applications for managing files andjobs.
· EdgeX Application Services: AiCSDuses the APIs from the EdgeX Applications Services to communicate and transferinformation.
· EdgeX Services:The services include the database, message broker, and security services.
· Pipeline Execution: AiCSDfurnishes an example pipeline for pipeline management.
· File System: AiCSD stores and manages inputand output files.
· Third-party Input Devices: The devicessupply the images that will be processed. Examples include an opticalmicroscope or conveyor belt camera.
The reference architecture lets imagesbe processed using assigned jobs. The job tracks the movement of the file, thestatus, and any results or outputs from the pipeline. To process a job, sometasks help match information about a job to the appropriate pipeline to run.
The process can be elaborated asbelow:
1. The InputDevice/Imager writes the file to the OEM file system in a directorythat is watched by the File Watcher. When the File Watcher detects thefile, it sends the job (JSON struct of particular fields) to the DataOrganizer via HTTP Request.
2. The DataOrganizer sends the job to the Job Repository to create a new job inthe Redis Database. The job information is then sent to the TaskLauncher to determine if there is a task that matches the job. If there is,the job proceeds to the File Sender (OEM).
3. The FileSender (OEM) is responsible for sending both the job and the file to the FileReceiver (Gateway). Once the File Receiver (Gateway) has written thefile to the Gateway file system, the job is then sent on to the TaskLauncher.
4. The TaskLauncher verifies that there is a matching task for the job before sendingit to the appropriate pipeline using the EdgeX Message Bus (via Redis).The ML pipeline subscribes to the appropriate topic and processes the file inits pipeline. The output file (if there is one) is written to the file systemand the job is sent back to the Task Launcher.
5. The TaskLauncher then decides if there is an output file or if there are just results.In the case of only results and no output file, the Task Launcher marks the jobas complete. If there is an output file, the Task Launcher sends the jobonward to the File Sender (Gateway).
6. The FileSender (Gateway) publishes the job information to the EdgeXMessage Bus via Redis for the File Receiver (OEM) to subscribe andpull. The File Receiver (OEM) sends an HTTP request to the File Sender(Gateway) for the output file(s). The file(s) are sent as part of theresponse and the File Receiver (OEM) writes the output file(s) to thefile system.

Figure 3: Architecture andHigh-level Dataflow
AI Pipeline for CHOCell Segmentation Use Case
Let’s explain AI pipeline for CHOcell segmentation at a high level. As plate readers3 generate cellimages in their local file system, these images need to be transferred toanother device for analysis where AI software and hardware resources areavailable. This separation of data and model locations requires a flexible,microservice-based solution. We use the AiCSD microservice infrastructure totransfer the data to the edge compute device. AiCSD leverages EdgeX FoundryMicroservices to facilitate the automatic detection, management, and transferof scientific data. This microservice flexibility is crucial for addressing theheterogeneous system integration and asymmetric data interfacing inherent inthis project.
The AI pipeline on the edgecompute device includes image preprocessing, inference of multiple DeepLearning models optimized by the OpenVINO toolkit, and image postprocessing.Figure 4 shows an example of using Deep Learning models to process cell images,where UNet is used to mask and count MSC nuclei. These processes arecontainerized using BentoML,an open-source tool. Additionally, the OpenVINO Toolkit accelerates DeepLearning model inference, providing lower latency and higher throughput whilemaintaining accuracy and optimizing hardware usage. OVMS handles model managementand version control. Once the AI pipeline processing job is completed on theedge compute device, the final results are transferred back to the local filesystem of the original scientific device using the AiCSD microserviceinfrastructure to complete the task.
Overall, the integration of IntelEdge AI solutions enables the efficient implementation of the AI pipeline forthe CHO cell segmentation use case.

Figure 4. MSC Nuclei countingusing UNet deep learning model.
Conclusion
In the article, we discussed theimplementation of an AI pipeline for cell image analysis, particularly focusingon the application of Intel Edge AI solutions in processing brightfield cellimages. We highlighted Intel's OpenVINO toolkit as a crucial component foroptimizing the inference of existing Deep Learning models within the cell AIpipeline. Additionally, we explained how the OpenVINO Model Server operates asa microservice, enabling other components within a system to interact with andutilize the models effectively. Furthermore, we explored AI Connect forScientific Data (AiCSD) and its role in the efficient implementation of thebrightfield cell image analysis pipeline.
The journey toward fully realizing thecapabilities of AI in biopharma is ongoing, and Intel's contributions arepaving the way for a future where drug development is more agile, precise, andpatient-centric. Stay tuned for further insights as we continue to explore theexciting intersection of Edge AI technology and biopharmaceutical research.
Reach out to Intel's Health and LifeSciences team at health.lifesciences@intel.com or learn more about what we doat https://www.intel.com/health.
We'd like to hear from you! Let usknow in the comments or discuss – which AI use cases in health and lifesciences do you think will have the greatest impact on global health?
If you enjoyed hearing from the Healthand Life Sciences team and want to hear more, give this post a like andensure you subscribe to get the latest updates from theteam.
About the Author
Nooshin Nabizadeh has Ph.D.in Electrical and Computer Engineering from the University of Miami and worksat Intel Corporation as AI Solutions Architect. She enjoys photography, writingpoetry, reading about psychology and philosophy, and optimizing solutions torun as fast as possible on a given piece of hardware. Connect with her onLinkedIn https://www.linkedin.com/in/nooshin-nabizadeh/ by mentioning thisblog.
References
1. Brightfieldmicroscopy is a widely used technique for observing the morphology of cells andtissues.
2. https://docs.openvino.ai/archive/2023.2/ovms_what_is_openvino_model_server.html
3. A plate reader is a laboratoryinstrument used to obtain images from samples in microtiter plates. The readershines a specific calibrated frequency of light (UV, visible, fluorescence,etc.) through the samples in the wells of the plate. Plate reader microscopydata sets have inherent variability which drives the requirement of regulartracked calibration and adjustment.
OpenVINO Extension operation by SYCL program on CPU
In this blog, we will introduce the path that how OpenVINO support extensibility on CPU platform, and a sample of creating one custom operation by implement a SYCL program on CPU. oneAPI has two programming modes, one is through direct programming by SYCL which is C++ based language; another is based on acceleration libraries. In this sample we will use oneAPI DPC++ compiler to support SYCL program compiling in custom extension library, so that if users familiar with SYCL optimization can refer the OpenVINO extension mechanism to support and optimize their own operation kernel.
First of all, you should understand the interface and invoke scheduling of extension operations through OpenVINO core API. OpenVINO support to create a custom operation which is inherited from ov::op::Op and realize the member function “evaluate()” with SYCL implementation. Then, register this customer operation by “ov::OpExtension” to generate a runtime library of OpenVINO extensions. Finally, we will enable the custom extension library can be called by “add_extension()” function by Core API in runtime.
The next step is to create an IR model with this extension operation. We will introduce a method to create OV model by using OpenVINO opset and modify the layer version to extension make sure Core API can invoke operation registered in the extension library.
System requirement
Please make sure you already correctly install the OpenVINO C++ package from:
https://storage.openvinotoolkit.org/repositories/openvino/packages/
And setup environment variable for OpenVINO by:
Then, install the DPC++ compiler, and source the environment variable:
In this blog, we create a customized “SYCL_Add” operation, the folder and files structure like below:
Step 1: Create custom operation by SYCL kernel.
For example, we create a custom operation to realize the functionality of “Add” and named it as “SYCL_Add”. We define this operation with header “add.hpp”:
Then, we need to override the member functions of this new operation, especially the implementation of “evaluate()”.If this blog, we will show an example of SYCL kernel. To enable SYCL programming on CPU, you are required to install the DPC++ compiler and include the header <sycl/sycl.hpp>. Below is the code implementation of “add.cpp”:
As you can see, in this SYCL kernel implementation, there require creating buffer objects which can be managed on device and create accessors to control the accessing of these buffers. So, it remains buffer type conversion between C++ float pointer and SYCL float buffer. The idea of SYCL programming is like OpenCL for heterogeneous platform like GPU/NPU which remains buffer management and synchronization between host and device. This sample is just for CPU extension, there’s no use with device memory.
Step 2: Register custom operation as extension.
To register the customer operation by “ov::OpExtension”,refer below code of “ov_extension.cpp”:
Then, you can create “CMakeLists.txt” file like below. Make sure use the DPC++ compiler with option “-fsycl”.
Use cmake to compile the runtime library for the extension operation. If you have more operations, just add source files into “add_library()”. Then we can get the runtime library called “libcustom.so”.If you meet any problem about compiler icpx, please make sure you already correctly install the DPC++ compile, and source the environment variable.
Step 3: Create IR model by OpenVINO opset
Here introduces a hack method to create ancustom operation “SYCL_Add” by exist OpenVINO opset. Due to the parameter and nodeinput/output of custom op is same as “ov::op::v1::Add”, thus we can use thismethod.
Firstly, create a python program to build OpenVINO IR model with “ov::op::v1::Add”. You can also use OpenVINO C++ API to create model, here use Python code just for quick verification.
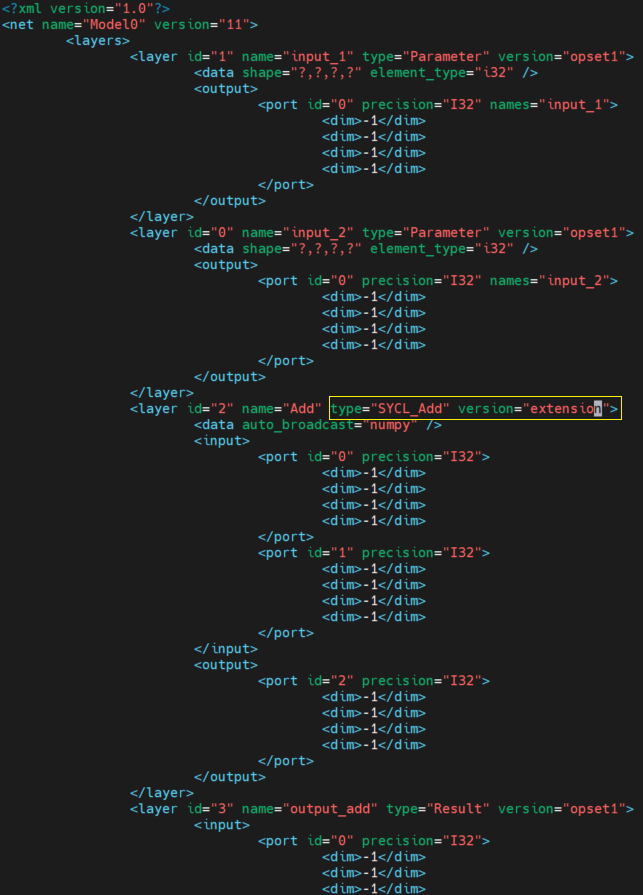
Now, you will get the IR model with OpenVINO “opset.Add”. We can directly modify the “.xml” like below, change the type of this layer to “SYCL_Add” and modify the version of the layer to “extension”.
Step 4: Run and profile the model execution with the SYCLextension library.
Now, you can quick check the workable and performance by OpenVINO benchmark_app sample:
You can check the execution time of yourSYCL kernel:
Please note, the “execType” is using the ref_xxx means your custom reference implementation kernel with the data type.
Summary
This blog just shows the capable way to enable SYCL kernel as the extension of CPU plugin, we will not focusing on guiding the user implement the SYCL kernel like above programming. There are a lot of technic skills of kernel optimization, if you already have an efficient SYCL kernel and want to enable as the CPU extension to workaround some customized operations. We hope this blog will be helpful to you.
Q1'24: Technology Update – Low Precision and Model Optimization
Authors
Alexander Kozlov, Nikita Savelyev, Nikolay Lyalyushkin, Vui Seng Chua, Pablo Munoz, Alexander Suslov, Andrey Anufriev, Liubov Talamanova, Yury Gorbachev, Nilesh Jain, Maxim Proshin
Summary
This quarter we observe paving ultra low-bit Large Language Models (LLMs) weight quantization including ternary quantization where weight can take only three possible values {-1, 0, 1}. Many papers are also focusing on vector quantization of weights when a sequence of weights (2, 4, or 8 elements) is replaced by the index in the lookup table (e.g. based on E8 lattice).
A lot of effort is dedicated to KV-cache optimization of LLMs. Methods such as low-bit quantization and token eviction are getting mainstream in the SW solution designed for LLM inference. And here is the announced Nvidia Blackwell can get a competitive advantage as it supportsFP4 type on the HW level that fits well KV-cache on-the-fly compression/decompression.
Highlights
- The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits by Microsoft Research and University of Chinese Academy of Sciences (https://arxiv.org/pdf/2402.17764.pdf).The paper introduces 1-bit LLM variant called BitNet b1.58, where every parameter is ternary, taking on values of {-1, 0, 1}. BitNet b1.58 retains all the benefits of the original 1-bit BitNet, including new computation paradigm, which requires almost no multiplication operations for matrix multiplication and can be highly optimized. BitNet b1.58 offers two additional advantages. Firstly, its modeling capability is stronger due to its explicit support for feature filtering, made possible by the inclusion of 0 in the model weights, which can significantly improve the performance of 1-bit LLMs. Secondly, experiments show that BitNet b1.58 can match full precision (i.e., FP16) baselines in terms of both perplexity and end-task performance, starting from a 3B size, when using the same configuration.

- QuIP#: Even Better LLM Quantization with Hadamard Incoherence and Lattice Codebooks by Cornell University (https://arxiv.org/pdf/2402.04396.pdf).The paper introduces QuIP#, a weight-only post-training compression method for2, 3, and 4-bit LLM quantization. It uses the Randomized Hadamard Transform(RHT) as a form of outlier suppression and introduces the E8 lattice-based E8Pcodebook to better quantize RHT transformed weights. The E8P codebook is highly symmetric and admits fast inference, allowing a “proof of concept” QuIP# CUDA implementation to achieve over 50% peak memory bandwidth on GPUs. QuIP# also implements inter-layer fine-tuning, further improving quantization. The method achieves superior scaling at 3 bits over 4 bits and similar scaling at 2 bits to higher bitrates. The code is available at https://github.com/Cornell-RelaxML/quip-sharp.

- FP6-LLM: Efficiently Serving Large Language Models Through FP6-Centric Algorithm-System Co-Design by Microsoft (https://arxiv.org/pdf/2401.14112v1.pdf).Authors highlight the key challenges in supporting FP6 quantization on modern GPUs. They propose TC-FPx, the first full-stack GPU kernel design scheme with unified Tensor Core support of float-point weights with various bit-width, in particular, FP6. They also provide new end-to-end inference support for quantized LLMs through the integration of TC-FPx, achieving better trade-offs between inference cost and model quality, and evaluate FP6-LLM on various LLM models demonstrating that it substantially outperforms the baseline.

- Dynamic Memory Compression: Retrofitting LLMs for Accelerated Inference by Nvidia, University of Wrocław, University of Edinburgh. (https://arxiv.org/pdf/2403.09636.pdf). DMC proposes to bake in online KV cache compression capability to pretrained LLM through an uptraining approach. The core idea to is determine if an incoming KV pair should be accumulated into an existing KV pair aggregated over successive timesteps or appended as a new KV segment of aggregation. To facilitate this, the authors propose a predictor module that is integrated into each attention head, utilizing solely the first feature of the current Q and K projections to produce the binary decision and the accumulation factor. With no overhead learning parameters, continued pretraining as low as 2-4% of original learning attains significant dynamic cache compression. DMC, applied across Llama2 7-70B size, preserves the original downstream task quality with up to 4× cache compression, translating throughput improvement up to 3.4× on A100 and 3.7× on H100. The reader is encouraged to consult the full paper for training solutions for the non-differentiability and dynamic KV management during training.

Papers with notable results
Quantization
- Extreme Compression of Large Language Models via Additive Quantization by HSE University, Yandex Research, Skoltech, IST Austria, Neural Magic (https://arxiv.org/pdf/2401.06118.pdf).The paper proposes a practical adaptation of Additive Quantization to the task of post-training quantization of LLMs. Authors adapt the optimization problem to be instance-aware, taking layer calibration input and output activations into account. They also complement the layer-wise optimization with an efficient intra-layer tuning technique, which optimizes quantization parameters jointly over several layers, using only the calibration data. The method shows promising results in a 2, 3,4-bit weight compression settings achieving significantly better accuracy than GPTQ. The code is available at https://github.com/vahe1994/AQLM.
- Enhanced Distribution Alignment for Post-Training Quantization of Diffusion Models by Chinese Academy of Sciences (https://arxiv.org/pdf/2401.04585.pdf).Authors identify two levels of mismatch in diffusion models, including the calibration sample level and the reconstruction output level, which result in the low performance of PTQ. Based on this, they propose an alignment method to address the calibration sample level mismatch as well as a technique to eliminate the reconstruction output level mismatch. Results show that, with theW4A8 precision setting, the quantized models can compare to the full-precision models, and the method is robust to the inference space, resolution, and guidance conditions of diffusion models.
- KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization by UC Berkeley (https://arxiv.org/pdf/2401.18079.pdf). The work facilitates low-precision KV cache quantization by incorporating several novel methods: (i) Per-Channel Key Quantization, where the dimension is adjusted along which the Key activations are quantized to better match the distribution; (ii) Pre RoPE Key Quantization, where Key activations are quantized before the rotary positional embedding to mitigate its impact on quantization; (iii) Non-Uniform KV Cache Quantization, where per-layer sensitivity-weighted non-uniform datatypes are derived that better represent the distributions; (iv)Per-Vector Dense-and-Sparse Quantization, where outliers are isolated separately for each vector to minimize skews in quantization ranges; and (v) Q-Norm, where quantization centroids are normalized to mitigate distribution shift, providing additional benefits for 2-bit quantization. The method helps to achieve < 0.1 perplexity degradation with 3-bitquantization on both Wikitext-2 and C4 and enables serving LLaMA-7B with a context length of up to 1 million on a singleA100-80GB GPU and up to 10 million on an 8-GPU system.
- BiLLM: Pushing the Limit of Post-Training Quantization for LLMs by The University of Hong Kong, Beihang University, ETH Zurich (https://arxiv.org/pdf/2402.04291.pdf).The paper presents 1-bitpost-training quantization scheme tailored for pretrained LLMs. Based on the weight distribution of LLMs, the method first identifies and structurally selects salient weights, and minimizes the compression loss through an effective binary residual approximation strategy. Moreover, considering the bell-shaped distribution of the non-salient weights, authors propose a splitting search to group and binarize them accurately. The method achieves8.41 perplexity on LLaMA2-70B (with 3.32baseline) with 1.08-bit weights across.
- DB-LLM: Accurate Dual-Binarization for Efficient LLMs by The Beihang University, The University of Sydney, Harbin Institute of Technology, Shenzhen and Jiangsu University (https://arxiv.org/pdf/2402.11960.pdf). The paper analyzes properties of LLM weight distribution and proposes a method consisted of two parts: 1) Flexible Dual Binarization of weights which effectively uses two binary matrices instead of one in conventional binarization method, allowing to use 4 quantization levels instead of 2 and preserve zero values after the quantization. 2) Deviation-Aware Distillation which prioritizes uncertain samples by utilizing a pair of teacher-student entropy as a difficulty indicator using a data-free distillation approach. The method achieves 4.64 perplexity onLLaMA2-70B (with 3.32 baseline) outperforming BiLLM method (with 8.41perplexity) in terms of metrics.
- Accurate LoRA-Finetuning Quantization of LLMs via Information Retention by Beihang University, ETH Zurich, Byte dance AI Lab (https://arxiv.org/pdf/2402.05445.pdf).The paper proposes two methods to improve accuracy of LLMs during weight quantization: (1) statistics-based Information Calibration Quantization allows the quantized parameters of LLM to retain original information accurately; (2)finetuning-based Information Elastic Connection makes LoRA utilizes elastic representation transformation with diverse information. The method helps improve accuracy under 2-4 bit-widths, e.g., 4- bit LLaMA-7B achieves 1.4% improvement on MMLU compared with the state-of-the-art methods. The significant performance gain requires only a tiny 0.31% additional time consumption, revealing the satisfactory efficiency of our IR QLoRA The code is available at https://github.com/htqin/ir-qlora.
- GPTVQ: The Blessing of Dimensionality for LLM Quantization by Qualcomm AI Research (https://arxiv.org/html/2402.15319v1).The paper introduces a post-training method for vector quantization of LLM weights. The method interleaves quantization of one or more columns with updates to the remaining unquantized weights, using information from the Hessian of the per-layer output reconstruction MSE. Quantization codebooks are initialized using a data-aware version of the EM algorithm. The codebooks are then updated, and further compressed by using integer quantization and SVD-based compression. The method achieves good results on very large models such as aLlamav2-70B and improved latency compared to using a 4-bit integer format with on-device timings for decompression on a mobile CPU. The source code will be available at https://github.com/qualcomm-ai-research/gptvq.
- L4Q: Parameter Efficient Quantization-Aware Training on Large Language Models via LoRA-wise LSQ by Seoul National University, Sungkyunkwan University (https://arxiv.org/pdf/2402.04902.pdf).Authors propose quantization-aware training scheme applicable to both full-precision or pre-quantized LLMs that acts as a shortcut of LoRA fine-tuning on pre-quantized models. The method demonstrates good performance within a limited number of training steps. Experiments highlight a capability to fine-tune a 33B model using a single A100 GPU with 80G memory. Additionally, authors show that the joint training of quantization parameters not only significantly reduces memory requirements but also preserves model quality.
- EasyQuant: An Efficient Data-free Quantization Algorithm for LLMs by Tencent (https://arxiv.org/pdf/2403.02775.pdf).Authors show that the outliers in weights are more critical to the model’s performance compared to the normal elements. Beyond this, they propose to use a gradient-based method for optimizing the quantization range. These two strategies can also be used in other scenarios, such as weight-activation quantization and quantization-aware training (QAT). The method is fast and does not have generalization problems as it is data-free.
- OneBit: Towards Extremely Low-bit Large Language Models by Tsinghua University and Harbin Institute of Technology (https://arxiv.org/pdf/2403.02775.pdf). This paper introduces a method that quantizes the weight matrices of LLMs to 1-bit. Authors introduce a 1-bit quantization-aware training (QAT) framework named OneBit, including a novel 1-bit parameter representation method to better quantize LLMs as well as an effective parameter initialization method based on matrix decomposition to improve the convergence speed of the QAT framework. Experimental results indicate that OneBit achieves good performance (at least 83% of then on-quantized performance) with robust training processes.
- GEAR: An Efficient KV Cache Compression Recipe for Near-Lossless Generative Inference of LLM by Georgia Tech, Intel, and University of Maryland (https://arxiv.org/pdf/2403.05527.pdf).The paper proposes a method to tackle the problem of KV-cache compression of text-generation transformer models. The method first applies quantization to the majority of entries of similar magnitudes to ultra-low precision. It then employs a low-rank matrix to approximate the quantization error, and a sparse matrix to remedy individual errors from outlier entries. Experiments demonstrate the proposed approach achieves near-lossless 4-bit KV cache compression with up to 2.38× throughput improvement while reducing peak-memory size up to 2.29×.The code is available at https://github.com/HaoKang-Timmy/GEAR.
- AFPQ: Asymmetric Floating Point Quantization for LLMs by China Universities and Microsoft Research Asia (https://arxiv.org/pdf/2311.01792.pdf).Authors propose accurate asymmetric schema for the floating-point quantization. Instead of using typical asymmetric schema with scale and zero point, they use just2 scales: one is for positive values and another - for negative ones. It gives better accuracy NF4/NF3 quantization on different LLAMA models with no memory overhead. Code is available: https://github.com/zhangsichengsjtu/AFPQ.
- AFFINEQUANT: AFFINETRANSFORMATION QUANTIZATION FOR LARGE LANGUAGE MODELS by Xiamen University, Byte Dance and Peng Cheng Laboratory (https://arxiv.org/pdf/2403.05527.pdf).Authors propose an affine transform in PTQ, which minimizes quantization error, especially under low-bit quantization of LLMs. They propose an optimization algorithm that guarantees invertibility throughout the process, utilizing the Levy-Desplanques theorem, and simultaneously reduces computational costs. The method obtains good performance for large language model quantization, especially on low-bit or small models. Without additional overhead, on the w4a4 configuration of LLaMA2-7B, our perplexity on the C4dataset is 15.76 (2.26↓ vs 18.02 in OmniQuant). The code is available at: https://github.com/bytedance/AffineQuant.
- QAQ: Quality Adaptive Quantization for LLM KV Cache by Nanjing University (https://arxiv.org/pdf/2403.04643.pdf).The paper focuses on the KV-cache compression problem of LLMs Authors and claims that existing methods primarily rely on various hypotheses, such as sorting the KV cache based on attention scores for replacement or eviction, to compress the KV cache and improve model throughput. However, heuristics used by these strategies may wrongly evict essential KV cache, which can significantly degrade model performance. Authors propose a scheme for the KV cache and theoretically demonstrate that key cache and value cache exhibit distinct sensitivities to quantization, leading to the formulation of separate quantization strategies for their non-uniform quantization. Through the integration of dedicated outlier handling, as well as an improved attention-aware approach, the method achieves up to 10× the compression ratio of the KV cache size with a moderate impact on model performance.
- Get More with LESS: Synthesizing Recurrence with KV Cache Compression for Efficient LLM Inference by CMU, UT Austin and Meta (https://arxiv.org/pdf/2402.09398.pdf). Authors propose a simple integration of a constant sized cache with eviction-based cache methods, such that all tokens can be queried at later decoding steps. Low-rank caches in the method occupy constant memory with respect to the sequence length, and in the experiments, the extra storage to accommodate is nearly free, taking up the equivalent space of only 4 extra KV pairs in our experiments. Inspired by recurrent networks, the low-rank state stores new information by recursive updates rather than concatenation. As each sample has its own cache, the method provides the same proportional cache reduction for small and large batch sizes. Its ability to retain information throughout time shows merit on a variety of tasks where we demonstrate it can help reduce the performance gap from caching everything, some times even matching it, all while being efficient. Code can be found at https://github.com/hdong920/LESS.
- KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache by Rice University et. al. (https://arxiv.org/pdf/2402.02750.pdf)This paper analyzes methodically into extreme 2-bit quantization of KV cache and uncovers that the optimal scheme is per channel on key cache and value cache by token. Due to the streaming nature of caching and per-channel quantization coupling key cache across tokens, the authors propose grouping within the key and value caches. Quantization is performed only upon the completion of each group and maintained in FP16 otherwise. Extensive set of task benchmarks have demonstrated KIVI’s great retention of FP16 quality across Llama, Falcon, Mistral families. With tailored GPU implementation, KIVI can serve Llama2-7B with up to 4× larger batch size and achieves 2.35× ∼3.47× increased throughput on A100 (80GB). Code is available at https://github.com/jy-yuan/KIVI.
Pruning
- RockEngine: Sparse and Efficient Fine-tuning in a Pocket by MIT, UCAD and NVidia (https://arxiv.org/pdf/2310.17752.pdf).Authors introduce PockEngine: a sparse and efficient engine to enable fine-tuning on various edge devices. PockEngine supports sparse backpropagation: it prunes the backward graph and sparsely updates the model with measured memory saving and latency reduction while maintaining the model quality. PockEngine is compilation first: the entire training graph is derived at compile-time, which reduces the runtime overhead and brings opportunities for graph transformations. It also integrates a rich set of training graph optimizations, thus can further accelerate the training cost, including operator reordering and backend switching. PockEngine supports diverse applications, frontends and hardware backends: it flexibly compiles and tunes models defined in PyTorch/TensorFlow/Jax and deploys binaries to mobile CPU/GPU/DSPs. It achieves up to 15x speedup over off-the-shelf TensorFlow(Raspberry Pi), 5.6x memory saving back-propagation (Jetson AGX Orin).Remarkably, PockEngine enables fine-tuning LLaMav2-7B on NVIDIA Jetson AGX Orinat 550 tokens/s, 7.9x faster than the PyTorch.
- SLICEGPT: COMPRESS LARGELANGUAGE MODELS BY DELETING ROWS AND COLUMNS by ETH Zurich and Microsoft (https://arxiv.org/pdf/2401.15024.pdf). The paper introduces a post-training sparsification scheme that makes transformer networks (including LLMs) smaller by first applying orthogonal transformations to each transformer layer that leave the model unchanged, and then slicing off the least significant rows and columns (chosen by the eigenvalue decay) of the weight matrices. The model structure is left unchanged, but each weight matrix is replaced by a smaller (dense) weight matrix, reducing the embedding dimension of the model. This results in speedups(without any additional code optimization) and a reduced memory footprint. The method can remove up to 25% of the model for LLAMA-270B, OPT 66B, and Phi-2 models while maintaining 99%, 99%, and 90% zero-shot task performance respectively. Code is available at: https://github.com/microsoft/TransformerCompression.
- Not All Experts are Equal: Efficient Expert Pruning and Skipping for Mixture-of-Experts Large Language Models by CUHK MMlab, Shanghai Jiao Tong University, Shanghai Artificial Intelligence Laboratory (https://arxiv.org/pdf/2402.14800.pdf). One of the first attempts to prune MoE models. The method works post-training and statistically estimates contribution each expert. Then, it gradually removes the less used experts from the model. The code will be available at https://github.com/Lucky-Lance/Expert_Sparsity.
- ProSparse: Introducing and Enhancing Intrinsic Activation Sparsity within Large Language Models by Tsinghua University, ICT Academy China and Tencent (http://arxiv.org/abs/2402.13516). The work extends the training-based activation sparsification, Relufication with progressive regularization and concluding with ReLU threshold adjustment. In particular, it employs L1 regularization after the initial Relufication, incrementally by annealing regularization factor following a sine function. The final technique is a calibration of positive threshold for ReLU to enhance sparsity. Under a given budget of training tokens, the efficacy of increasing sparsity while attaining better task quality is demonstrated on Llama2-7B &13B and benchmarked against recipes including vanilla, shifted Relufication, and fixed L1 factor. On acceleration, a set of CUDA Sparse kernel is developed. Up to 70% of additional speedup can be achieved on top of the Relufied models. Kernel codes can be found here: https://github.com/Raincleared-Song/sparse_gpu_operator.
- Keyformer: KV Cache reduction through key tokens selection for Efficient Generative Inference by University of British Columbia. (https://arxiv.org/pdf/2403.09054.pdf). This work investigates the task inaccuracies caused by token pruning techniques in KV cache compression. It was observed that the attention scores in subsequent decoding steps is highly distorted, causing spurious token importance assessment and elimination. To counter this, Keyformer proposes a regularization approach on attention score by substituting the softmax inattention with Gumbel softmax. By calibrating hyperparameters (noise and temperature) of Gumbel softmax empirically, Keyformer outperforms Heavy-Hitter Oracle in Pareto efficiency on generation tasks, such as conversation and summarization across GPT-J, Celebras-GPT, and MPT which utilize varied position embeddings.
- Shears: Unstructured Sparsity with Neural Low-rank Adapter Search by Intel Labs (https://arxiv.org/abs/2404.10934). Recently, several approaches successfully demonstrated that weight-sharing Neural Architecture Search (NAS) can effectively explore a search space of elastic low-rank adapters (LoRA), allowing the parameter-efficient fine-tuning (PEFT) and compression of large language models. In this paper, researchers introduce a novel approach called Shears, demonstrating how the integration of cost-effective sparsity and a proposed Neural Low-rank adapter Search (NLS) algorithm can further improve the efficiency of PEFT approaches. Results demonstrate the benefits of Shears compared to other methods, reaching high sparsity levels while improving or with little drop in accuracy, utilizing a single GPU for a pair of hours.
Other
- MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases by Meta (https://arxiv.org/pdf/2402.14905.pdf). Authors propose deep and thin architectures, coupled with embedding sharing and grouped-query attention mechanisms, and establish a strong baseline network denoted as MobileLLM, which attains a 2.7%/4.3%accuracy boost over the preceding 125M/350M state-of-the-art models. Additionally, they proposed an immediate block-wise weight-sharing approach with no increase in model size and only marginal latency overhead. The resultant models, denoted as MobileLLM-LS, demonstrate a further accuracy enhancement of 0.7%/0.8% than MobileLLM 125M/350M.
- MobileCLIP: Fast Image-Text Models through Multi-Modal Reinforced Training by Apple (https://arxiv.org/pdf/2311.17049.pdf).Authors design a new family of mobile-friendly CLIP models, MobileCLIP. They use hybrid CNN-transformer architectures with structural reparametrization in image and text encoders to reduce the size and latency. Authors introduce multi-modal reinforced training, a novel training strategy that incorporates knowledge transfer from a pre-trained image captioning model and an ensemble of strong CLIP models to improve learning efficiency. They also introduce two variants of our reinforced datasets: DataCompDR-12M and DataCompDR-1B. Using DataCompDR, they demonstrate 10x-1000x learning efficiency in comparison to DataComp. MobileCLIP family obtains state-of-the-art latency-accuracy tradeoff on zero-shot tasks ,including marking a new best ViT-B/16 based CLIP model.
- Speculative Streaming: FastLLM Inference without Auxiliary Models by Apple (https://arxiv.org/pdf/2402.11131.pdf). The paper proposes a single-model speculative decoding method that fuses drafting into the target model by changing the fine-tuning objective from next token prediction to future n-gram prediction. Author also introduced a parallel tree draft pruning layer, which prunes some of the tokens from the input tree draft based on transition probability between parent and immediate child tokens. The method achieves on-par/higher speed-ups than Medusa-style architectures while using∼10000X fewer extra parameters.
- LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression by Microsoft and Tsinghua University (https://arxiv.org/pdf/2403.12968.pdf).Code is available at https://aka.ms/LLMLingua-2. Authors propose a data distillation procedure to derive knowledge from an LLM to compress prompts without losing crucial information and introduce an extractive text compression dataset. They formulate prompt compression as a token classification problem and use a Transformer encoder as the base architecture to capture all essential information for prompt compression from the full bidirectional context. The approach leads to lower latency by explicitly learning the compression objective with smaller models such as XLM-RoBERTa large and mBERT. They evaluate their method on both in-domain and out-of-domain datasets, including MeetingBank, LongBench, ZeroScrolls, GSM8K,and BBH. Despite its small size, our model shows significant performance gains over strong baselines and demonstrates robust generalization ability across different LLMs. Additionally, the model is 3x-6x faster than existing prompt compression methods, while accelerating the end-to-end latency by 1.6x-2.9xwith compression ratios of 2x-5x.
How to use OpenVINO Extension to enable custom operation on GPU
Authors: Kunda,Xu Song, Bell
This chapter introduces the extension mechanism of OpenVINO on GPU. And combine thecode snippets to explain how a custom operation should be expanded on the GPU.
First, we need to understand the OpenVINO Extensibility Mechanism, Custom operations, which are not included in the list, are not recognized by OpenVINO out-of-the-box. The need for custom operation may appearin two cases:
- A new or rarely used regular framework operation is notsupported in OpenVINO yet.
- A new user operation that was created for some specific modeltopology by the author of the model using framework extension capabilities.
Importing models with such operations requires additional steps. This guide illustrates the workflow for running inference on models featuring custom operations.
Introduction
How to implement custom operations by OpenVINO Extensibility API
OpenVINO Extensibility API enables adding support for those custom operations and using one implementation for Model Optimizer and OpenVINO Runtime.
Defining a new custom operation basically consists of two parts:
- Definition of operation semantics in OpenVINO, the code that describes how this operation should be inferred consuming input tensor(s) andproducing output tensor(s). The implementation of execution kernels for GPU is described in separate guides.
- Mapping rule that facilitates conversion of framework operation representation to OpenVINO defined operation semantics.
The first part is required for inference. Thesecond part is required for successful import of a model containing suchoperations from the original framework model format.
How to implement GPU custom operations
To enable operations not supported by OpenVINO™ out of the box, you may need an extension for OpenVINO operation set, and a custom kernel for the device you will target. This article describes custom kernel supportfor the GPU device.
The GPU code path abstracts many details about OpenCL. Youneed to provide the kernel code in OpenCL C and an XML configuration file that connects the kernel and its parameters to the parameters of the operation.
The process of GPU operation extension is the same as theoverall process of CPU operation, but because OpenVINO GPU operations are defined using OpenCL, additional files are required to provide interface and function definitions for custom ops.

In the above figure, custom_op.cl and custom_op.xml areadditional files required by the GPU extension than the CPU extension.
- custom_op.cl is the function definition of custom operation using OpenCL
- custom_op.xml is an extended function of OpenVINO GPU and provides the interface definition of custom operation function.
And need call the core.set_property() method from yourapplication with the "CONFIG_FILE" key and the configuration filename as a value before loading the network that uses custom operations to the plugin.


Quick Start
Similarto the OpenVINO CPU Extension process, the GPU extension process is as follows, there are several options to implement each part. The following sections will describe them in detail.
It is recommended to familiarize yourself with the implementation of the OpenVINO extension on the CPU first, so that you can better understand it when using GPU custom operations.
Definition of Operation Semantics
There aretwo ways to define custom operations,
- OpenVINO operation set combination. If thecustom operation can be mathematically represented as a combination of exiting OpenVINO operations and such decomposition gives desired performance.
- Implementing custom operation by C++/OpenCL. General advice, try to decompose the operation by OpenVINO operation set first, If such decomposition is not possible or appears too bulkywith a large number of constituent operations that do not perform well, then a new class for the custom operation should be implemented
- Custom Operation Guide Reference Link: https://docs.openvino.ai/2023.3/openvino_docs_Extensibility_UG_add_openvino_ops.html
Here wetake a simple OpenCL custom op as an example to illustrate.

Mapping from Framework Operation
Mapping of custom operation is implemented differently,depending on model format used for import. If a model is represented in the ONNX (including models exported from PyTorch in ONNX), TensorFlow Lite,PaddlePaddle or TensorFlow formats.
Frontend Extension API Reference Link: https://docs.openvino.ai/2024/documentation/openvino-extensibility/frontend-extensions.html
Registering Extensions
A custom operation class and a new mapping frontend extensionclass object should be registered to be usable in OpenVINO runtime.

Create a Library with Extensions
To create an extension library, for example, to load the extensions into OpenVINO Inference engine, perform the following:
CMake file define.

Build the extension library, running the commands below

OpenVINOGPU extension code snippets
