

OpenVINO Blog

Use Metrics to Scale Model Serving Deployments in Kubernetes
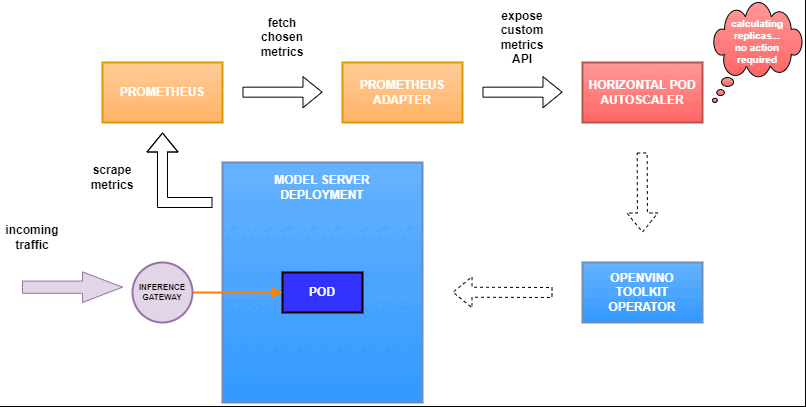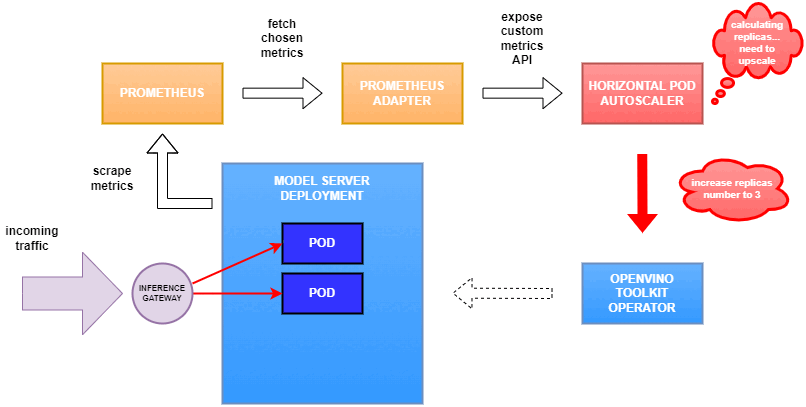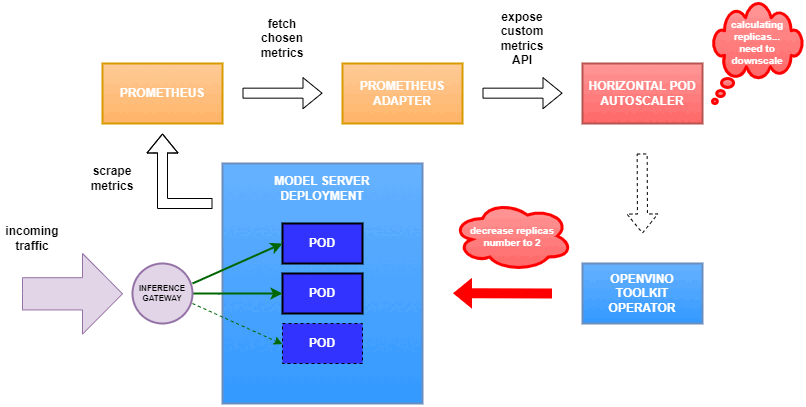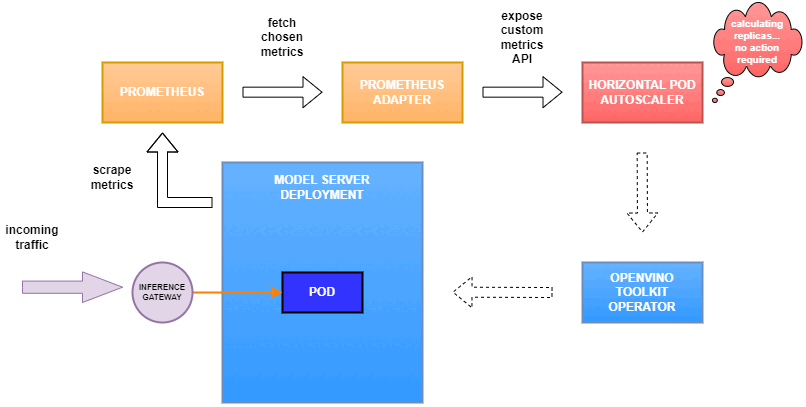
In this blog you will learn how to set up horizontal autoscaling in Kubernetes using inference performance metrics exposed by OpenVINO™ Model Server. This will enable efficient scaling of model serving pods for inference on Intel® CPUs and GPUs.
Why use custom metrics?
OpenVINO™ Model Server provides high performance AI inference on Intel CPUs and GPUs that can be scaled in Kubernetes. However, when it comes to automatic scaling in Kubernetes, the Horizontal Pod Autoscaler by default, relies on CPU utilization and memory usage metrics only. Although resource consumption indicates how busy the application is, it does not clearly say whether serving provides expected quality of service to the clients or not. Since OpenVINO Model Server exposes performance metrics, we can automatically scale based on service quality rather than resource utilization.
The first metric that comes to mind when thinking about service performance is the duration of request processing, otherwise known as latency. For example, mean or median over a specified period or latency percentiles. OpenVINO Model Server provides such metrics but setting autoscaling based on latency requires specific knowledge about each model and the environment where the inference is running in order to properly set thresholds that trigger scaling.
While autoscaling based on latency works and may be a good choice when you have model-specific knowledge, we will instead focus on a more generic metric using ovms_requests_streams_ratio. Let’s dive into what this means.
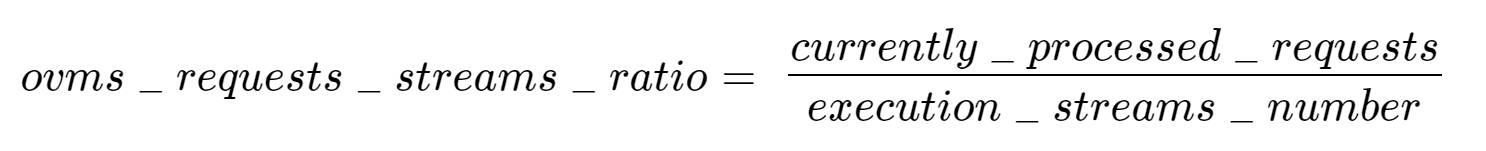
In the equation above:
- currently_processed_requests - number of inference requests to a model being processed by the service at a given time.
- execution_streams_number – number of execution streams. (When a model is loaded on the device, its computing units are divided into streams. Each stream independently handles inference requests, meaning that the number of streams defines how many inferences can be run on the device in parallel. Note that the more streams there are, the less powerful they are, so we get more throughput at a cost of higher minimal latency / inference time.)
In this equation, for any model exceeding a value of 1 indicates that requests are starting to queue up. Setting the autoscaler threshold for the ovms_requests_streams_ratio metric is somewhat of an arbitrary decision that should be made by a cluster administrator. Setting the threshold too low will result in underutilization of nodes and setting it too high will force the system to work with insufficient resources for extended periods of time. Now that we have chosen a metric for autoscaling, let’s start setting it up.
Deploy Model Server with Autoscaling Metrics
First, we need to create a deployment of OpenVINO Model Server in Kubernetes. To do this, follow instructions to install the OpenVINO Operator in your Kubernetes cluster. Then create a configuration where we can specify the model to be served and enable metrics:
Create ConfigMap:
With the configuration in place, we can deploy OpenVINO Model Server instance:
Create ModelServer resource:
Deploy and Configure Prometheus
Next, we need to read serving metrics and expose them to the Horizontal Pod Autoscaler. To do this we will deploy Prometheus to collect serving metrics and the Prometheus Adapter to expose them to the autoscaler.
Deploy Prometheus Monitoring Tool
Let’s start with Prometheus. In the example below we deploy a simple Prometheus instance via the Prometheus Operator. To deploy the Prometheus Operator, run the following command:
Next, we need to configure role-based access control to give Prometheus permission to access the Kubernetes API:
The last step is to create a Prometheus instance by deploying Prometheus resource:
If the deployment was successful, a Prometheus service should be running on port 9090. You can set up a port forward for this service, enabling access to the web interface via localhost on your machine:
Now, when you open http://localhost:9090 in a browser you should see the Prometheus user interface. Next, we need to expose the Model Server to Prometheus by creating a ServiceMonitor resource:
Once it’s ready, you should see a demo-ovms target in the Prometheus UI:
Now that the metrics are available via Prometheus, we need to expose them to the Horizonal Pod Autoscaler. To do this, we deploy the Prometheus Adapter.
Deploy Prometheus Adapter
Prometheus Adapter can be quickly installed via helm or step-by-step via kubectl. For the sake of simplicity, we will use helm3. Before deploying the adapter, we will prepare a configuration that tells it how to expose the ovms_requests_streams_ratio metric:
Create a ConfigMap:
Now that we have a configuration, we can install the adapter:
Keep checking until custom metrics are available from the API:
Once you see the output above, you can configure the Horizontal Pod Autoscaler to use these metrics.
Set up Horizontal Pod Autoscaler
As mentioned previously, we will set up autoscaling based on the ovms_requests_streams_ratio metric and target an average value of 1. This will try to keep all streams busy all the time while preventing requests from queueing up. We will set minimum and maximum number of replicas to 1 and 3, respectively, and the stabilization window for both upscaling and downscaling to 120 seconds:
Create HorizontalPodAutoscaler:
Once deployed, you can generate some load for your model and see the results. Below you can see how Horizontal Pod Autoscaler scales the number of replicas by checking its status:

This data can also be visualized with a Grafana dashboard:
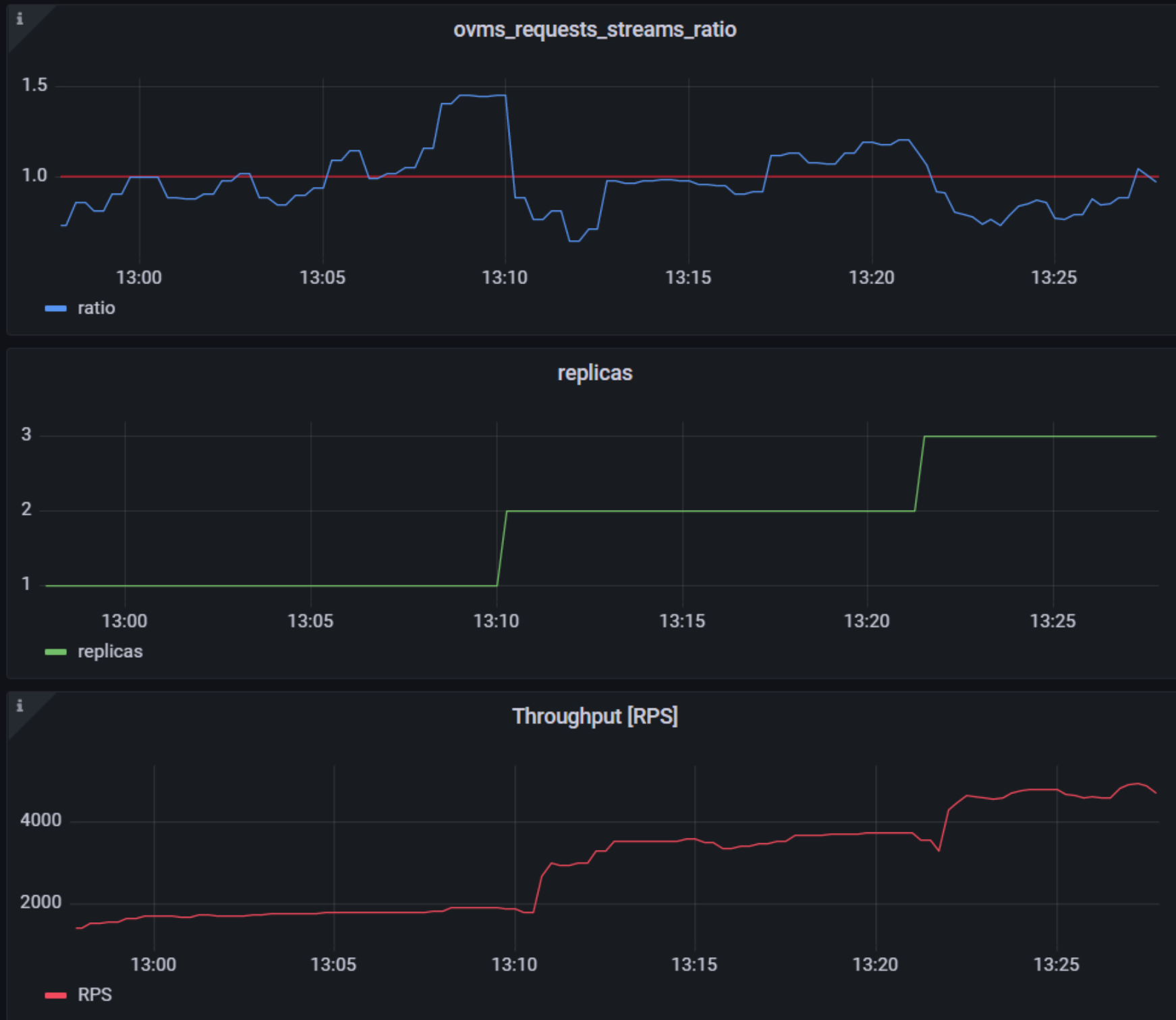
As you can see, with OpenVINO Model Server metrics, you can quickly set up inferencing system with monitoring and autoscaling for any model. Moreover, with custom metrics, you can set up autoscaling for inference on any Intel CPUs and GPUs.
See also:
- Load Balancing OpenVINO Model Server Deployments with Red Hat
- Kubernetes Device Plugin for Intel GPU
- OpenVINO Model Server metrics

Deploy AI Inference with OpenVINO™ and Kubernetes
Introduction
Model servers play a vital role in bringing AI models from development to production. Models are served via network endpoints which expose APIs to run predictions. These microservices abstract inference execution while providing scalability and efficient resource utilization.
In this blog, you will learn how to use key features of the OpenVINO™ Operator for Kubernetes. We will demonstrate how to deploy and use OpenVINO Model Server in two scenarios:
1. Serving a single model
2. Serving a pipeline of multiple models

Kubernetes provides an optimal environment for deploying model servers but managing these resources can be challenging in larger-scale deployments. Using our Operator for Kubernetes makes this easier.
Install via OperatorHub
The OpenVINO Operator can be installed in a Kubernetes cluster from the OperatorHub. Just search for OpenVINO and click the 'Install' button.
Serve a Single OpenVINO Model in Kubernetes
Create a new instance of OpenVINO Model Server by defining a custom resource called ModelServer using the provided CRD. All parameters are explained here.
In the sample below, a fully functional model server is deployed along with a ResNet-50 image classification model pulled from Google Cloud storage.
A successful deployment will create a service called ovms-sample.
Now that the model is deployed and ready for requests, we can use the ovms-sample service with our Python client known as ovmsclient.
Send Inference Requests to the Service
The example below shows how to use the ovms-sample service inside the same Kubernetes cluster where it’s running. To create a client container, launch an interactive session to a pod with Python installed:
From inside the client container, we will connect to the model server API endpoints. A simple curl command lists the served models with their version and status:
Additional REST API calls are described in the documentation.
Now let’s use the ovmsclient Python library to process an inference request. Create a virtual environment and install the client with pip:
Download a sample image of a zebra:

The Python code below collects the model metadata using the ovmsclient library:
The code above returns the following response:
Now create a simple Python script to classify the JPEG image of the zebra :
The detected class from imagenet is 341, which represents `zebra`.
Serve a Multi-Model Pipeline
Now that we have run a simple example of serving a single model, let’s explore the more advanced scenario of a multi-model vehicle analysis pipeline. This pipeline leverages the Directed Acyclic Graph feature in OpenVINO Model Server.
The remaining steps in this demo require `mc` minio client binary and access to an S3-compatible bucket. See the quick start with MinIO for more information about setting up S3 storage in your cluster.
First, prepare all dependencies using the vehicle analysis pipeline example below:
The command above downloads the required models and builds a custom library to run the pipeline, then places these files in the workspace directory. Copy these files to a shared S3-compatible storage accessible within the cluster (like MinIO). In the example below, the S3 server alias is mys3:
To use the previously created model server config file in `workspace/config.json`, we need to adjust the paths to models and the custom node library. The commands below change the model paths to use our S3 bucket and the custom node library to `/config` directory which will be mounted as a Kubernetes configmap.
Next, add both the config file and the custom name library to a Kubernetes config map:
Now we are ready to deploy the model server with the pipeline configuration. Use kubectl to apply the following ovms-pipeline.yaml configuration:
This creates the model serving service
To test the pipeline, we can use the same client container as the previous example with a single model. From inside the client container shell, download a sample image to analyze:

Run a prediction using the following command:
The sample code above returns a list of the pipeline outputs without data interpretation. More complete client code samples for vehicle analysis are available on GitHub.
Conclusion
OpenVINO Model Server makes it easy to deploy and manage inference as a service in Kubernetes environments. In this blog, we learned how to run predictions using the ovmsclient Python library with both a single model scenario and with multiple models using a DAG pipeline.
Learn more about the OpenVINO Operator: https://github.com/openvinotoolkit/operator
Check out our other model serving demos.
Deploy AI Workloads with OpenVINO™ Model Server across CPUs and GPUs
Authors: Xiake Sun, Kunda Xu
1. Introduction
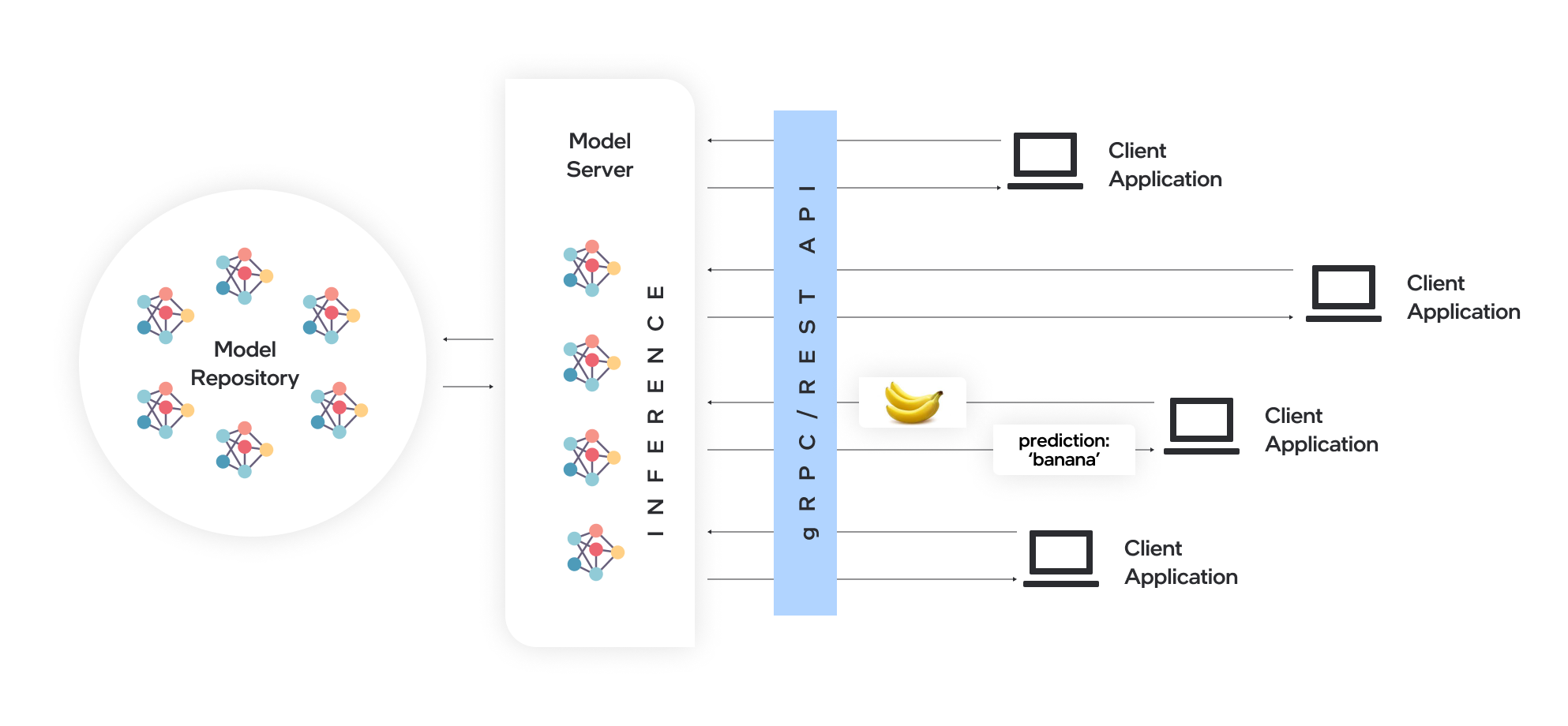
OpenVINO™ Model Server (OVMS) is a high-performance system for serving models. Implemented in C++ for scalability and optimized for deployment on Intel® architectures, the model server uses the same architecture and API as TensorFlow Serving and KServe while applying OpenVINO™ for inference execution. Inference service is provided via gRPC or REST API, making deploying new algorithms and AI experiments easy.
Docker is the recommended way to deploy OpenVINO™ Model Server. Pre-built container images are available on Docker Hub and Red Hat Ecosystem Catalog.
In this blog, we will introduce how to leverage OpenVINO™ Model Server to deploy AI workload across various hardware platforms, including Intel® CPU, Intel® GPU, and Nvidia GPU.
2. OpenVINO™ Model Server Pre-built Docker Image for Intel® CPU
Pull the latest pre-built OVMS docker image hosted in Docker Hub:
Verify OVMS docker image and OpenVINO™ backend version:
Here is an example output of the command line above:

Download a model and create an appropriate directory structure. For example, a person-vehicle-bike-detection model from Intel’s Open Model Zoo:
where a model directory structure looks like that:

After the model repository preparation, let’s start OVMS to host a person-vehicle-bike-detection-2000 model in the Model Server with Intel® CPU as target device.
The parameter “--target_device CPU” specified workload to allocate on Intel® CPU. “--port 30001” set up the gRPC server port as 30001, and “--rest_port 30001” set up the REST server port as 30002. The parameter “--model_path” specified the model directory path in the docker image, while “--model_name” specified which model to host in the model server.
3. Build OpenVINO™ Model Server Benchmark Client
OpenVINO™ Model Server provides a useful tool - Benchmark Client to generate traffic and measure the performance of the model served in OpenVINO™ Model Server. In this blog, you could use Benchmark Client to verify OpenVINO™ model server functionality quickly.
To build the docker image and tag it as benchmark_client as follow:
Here is an example to use benchmark_client to generate 8 requests and send them via gRPC API, then receive the severed model performance data:
In the output, "window_netto_frame_rate" measures the overall performance of a service - how many frames per second the model server processed. Please note, model serving example above was set up with default parameters, see the performance tuning section for more details.
4. Build OpenVINO™ Model Server from Source Code
Download the model server source code as follows:
OVMS provides a “Makefile” to build the docker image with environment parameters, which you can pass via the command line for the building process.
- BASE_OS: base OS docker image used to build OVMS docker image, current supported values are “ubuntu” (by default) and “redhat”.
- OV_USE_BINARY: control whether to use a pre-built OpenVINO™ binary package for building OVMS docker image. If "OV_USE_BINARY=1", OVMS use a pre-built OpenVINO™ binary package. If "OV_USE_BINARY=0", OpenVINO™ will be built from source code during OVMS building process.
- DLDT_PACKAGE_URL: If "OV_USE_BINRAY=1", "DLDT_PACKAGE_URL" is used to set the URL path to the pre-built OpenVINO™ binary package
- GPU: control whether to enable OVMS support for Intel® GPU. By default, “GPU=0” disables OVMS support for Intel® GPU. If "GPU=1", OVMS support for intel® GPU will be enabled.
- NVIDIA: control whether to enable OVMS support for Nvidia GPU. By default, "NVIDIA=0" disables OVMS support for Nvidia GPU. If "NVIDIA=1", OVMS support for Nvidia GPU will be enabled, which requires building OpenVINO from the source code.
- OV_SOURCE_BRANCH: If "OV_USE_BINARY=0", "OV_SOURCE_BRANCH" is used to set the target branch or commit hash of OpenVINO source code. The default value is “master”
- OV_CONTRIB_BRANCH: If "NVIDIA=1", "OV_CONTRIB_BRANCH" is used to set the target branch or commit hash of OpenVINO contrib source code. The default value is “master"
Here is an example of building OVMS with the "releases/2022/3" branch of OpenVINO™ GitHub source code with target device Intel® CPU.
Built docker image will be available in the host as “openvino/model_server:latest”.
5. Build OpenVINO™ Model Server with Intel® GPU Support
Since OpenVINO™ 2022.3 release, OpenVINO™ added full support for Intel’s integrated GPU, Intel’s discrete graphics cards, such as Intel® Data Center GPU Flex Series, and Intel® Arc™ GPU for DL inferencing workloads in the intelligent cloud, edge, and media analytics workloads. OpenVINO™ Model Server 2022.3 also added support for Intel® GPU. The pre-built OpenVINO™ Model Server docker image with GPU driver for Intel® GPU is available in Docker Hub:
Here is an example of building OVMS with Intel® GPU support based on the OpenVINO™ source code:
The default GPU driver (version 22.8 for RedHat 8.7 or version 22.35 for Ubuntu 20.04) will be installed during the building process. Built docker image will be available in the host as “openvino/model_server:latest-gpu”.
Here is an example to launch the OVMS docker image with Intel® GPU as target device:
The parameter “--target_device GPU” specified workload to allocate on Intel® GPU. The parameter “--device /dev/dri” is used to pass the device context. The parameter “--group-add=$(stat -c"%g" /dev/dri/render\* | head -n 1) -u $(id -u):$(id -g)” is used to ensure the model server process security context account with correct permissions to run inference on Intel® GPU.
Here is an example to verify the severed model performance on Intel® GPU with benchmark_client:
6. Build OpenVINO™ Model Server with Nvidia GPU Support
OpenVINO™ Model Server can also support Nvidia GPU cards by using NVIDIA plugin from the GitHub repo openvino_contrib. Here is an example of building OVMS with Nvidia GPU support step by step:
First, pull the Nvidia docker base image with the GPU driver, e.g.,“docker.io/nvidia/cuda:11.8.0-runtime-ubuntu20.04”, please ensure to install same GPU driver version in the local host environment.
Install Nvidia Container Toolkit to expose the GPU driver to docker and restart docker.
Build OVMS docker image with Nvidia GPU support.“NVIDIA=1” enables to build OVMS with Nvidia GPU support, and “OV_USE_BINARY=0” enables building OpenVINO from the source code. Besides, “OV_SOURCE_BRANCH=releases/2022/3” refer to the OpenVINO™ GitHub "releases/2022/3" branch, while “OV_CONTRIB_BRANCH=releases/2022/3” refer to the OpenVINO contrib GitHub "releases/2022/3" branch.
Built docker image will be available in the host as “openvino/model_server-cuda:latest”.
Here is an example to launch the OVMS docker image with Nvidia GPU as target device:
The parameter “--target_device NVIDIA” is specified to allocate workload on NVIDIA GPU. The parameter “--gpu all” flag is used to access all GPU resources available in the host system.
Here is an example to verify the severed model performance on Nvidia GPU with benchmark_client:
7. Migration from Triton Inference Server to OpenVINO™ Model Server
KServe, as a robust and extensible cloud-native model server for Kubernetes, is widely adopted by model servers including Triton Inference Server. Since the 2022.3 release, OpenVINO™ Model Server added KServer API that supports REST and gRPC calls. Therefore, OVMS with Nvidia GPU support is fully compatible to receive requests from Triton Inference Client and run inference on Nvidia GPU.
Here is an example to pull the Triton Inference Server docker image:
Then you could use perf_client tools in the docker image to send generated workload as requests to OVMS via KServe API with gRPC port, then receive measured performance data on Nvidia GPU.
The simple example above shows how smoothly developers can migrate their own AI service workload from Triton Inference Server to OpenVINO™ Model Server without any change from the client.
Leverage the power of Model Caching in your AI Applications
Authors: Devang Aggarwal, Eddy Kim, Preetha Veeramalai
Choosing the right type of hardware for deep learning tasks is a critical step in the AI development workflow. Here at Intel, we provide developers, like yourself, with a variety of hardware options to meet your compute requirements. From Intel® CPUs to Intel® GPUs, there are a wide array of hardware platforms available to meet your needs. When it comes to inferencing on different hardware, the little things matter. For example, the loading of deep learning models, which can be a lengthy process and can lead to a difficult user experience on application startup.
Are there ways to achieve faster model loading time on such devices?
Short answer is, yes, there are ways; one way is to handle the model loading time. Model loading performs several time-consuming device-specific optimizations and network compilations, which can also result in developers seeing a relatively higher first inference latency. These delays can lead to a difficult user experience during application startup. This problem can be solved through a mechanism called Model Caching. Model Caching solves the issue of model loading time by caching the final optimized model directly into a file. Reusing cached networks can significantly reduce the model loading time.
Model Caching
With OpenVINO 2022.3, model caching is currently implemented as a preview feature. To accelerate first inference latency on Intel® GPU, not only should the kernel source code be compiled in a form that can be executed on the GPU, but also various optimization passes must be performed. Kernel caching reuses only the kernels, but model caching reuses even the output of the optimization passes, so the model loading time can be further reduced. Before model caching, kernel caching was used in the same manner: by setting the CACHE_DIR configuration key to a folder where the cache should be stored. Now, to use the preview feature of model caching, set the OV_GPU_CACHE_MODEL environment variable to 1. Since the extension of the cache file created by kernel caching is “cl_cache” and the extension of the cache file created by model caching is “blob”, it is possible to check whether model caching is activated through this.
Note: Currently this is a preview feature with OpenVINO 2022.3. This feature will be fully available in OpenVINO 2023.0.
Developers can now also leverage this preview feature from OpenVINO™ Toolkit in OpenVINO™ Execution Provider for ONNX Runtime, a product that accelerates inferencing of ONNX models using ONNX Runtime API’s while using the OpenVINO™ toolkit as a backend. With the OpenVINO™ Execution Provider, ONNX Runtime delivers better inferencing performance on the same hardware compared to generic acceleration on Intel® CPU, GPU, and VPU. Additionally, by using model caching, OpenVINO™ Execution Provider can speed up the first inference latency of deep learning models on Intel® GPU.
In OpenVINO™ Execution Provider for ONNX Runtime, the model caching feature can been abled by setting the ONNX Runtime config option ‘use_compiled_network’ to True while using the C++/Python API’s. This config option acts like a switch to enable and disable the model caching feature that saves the final optimized model into a .blob file during the very first inference of the model on Intel® hardware.
The blobs are loaded from a directory named ‘ov_compiled_blobs’ relative to the executable path by default. This path however can be overridden using the ONNX Runtime config option ‘blob_dump_path’ which is used to explicitly specify the path where you would like to dump and load the blobs files from when already using theuse_compiled_network (model caching) setting.
Refer to Configuration Options for more information about using these options.
Conclusion
With the Model Caching feature, the deep learning model loading time should significantly decrease. You can now utilize this feature in both the Intel® Distribution of OpenVINO™ Toolkit and OpenVINO™ Execution Provider for ONNX Runtime and experience better first inference latency for your AI models.
Notices & Disclaimers
Intel technologies may require enabled hardware, software or service activation.
No product or component can be absolutely secure.
Your costs and results may vary.
©Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or itssubsidiaries. Other names and brands maybe claimed as the property of others.
An end-to-end workflow with training on Habana® Gaudi® Processor and post-training quantization and Inference using OpenVINO™ toolkit
Authors: Sachin Rastogi, Maajid N Khan, Akhila Vidiyala
Background:
Brain tumors are abnormal growths of braincells and can be benign (non-cancerous) or malignant (cancerous). Accurate diagnosis and treatment of brain tumors are critical for the patient's prognosis, and one important step in this process is the segmentation of the tumor in medical images. This involves identifying the boundaries of the tumor and separating it from the surrounding healthy brain tissue.
MRI is a non-invasive imaging technique that uses a strong magnetic field and radio waves to produce detailed images of the brain. MRI scans can provide high-resolution images of the brain, including the location and size of tumors. Traditionally, trained professionals, such as radiologists or medical image analysts, perform manual segmentation of brain tumors. However, this process is time-consuming and subject to human error, leading to the development of automated methods using machine learning.
Introduction:
As demand for deep learning applications grows for medical imaging, so does the need for cost-effective cloud solutions that can efficiently train Deep Learning models. With the Amazon EC2 DL1 instances powered by Gaudi® accelerators from Habana® Labs (An Intel® company), you can train deep learning models for medical image segmentation at a reduced cost of up to 40% than the current generation GPU-based EC2 instances.
Medical Imaging AI solutions often need to be deployed on various hardware platforms, including both new and older systems. The usage of Intel® Distribution of OpenVINO™ toolkit makes it easier to deploy these solutions on systems with Intel® Architecture.
This reference implementation demonstrates how this toolkit can be used to detect and distinguish between healthy and cancerous tissue in MRI scans. It can be used on a range of Intel® Architecture platforms, including CPUs, integrated GPUs, and VPUs, with no need to modify the code when switching between platforms. This allows developers to choose the hardware that meets their needs in terms of performance, cost, and power consumption.
The Challenge:
Identify and separate cancerous tumors from healthy tissue in an MRI scan of the brain with the best price performance.
The Solution:
One approach to brain tumor segmentation using machine learning is to use supervised learning, where the algorithm is trained on a dataset of labelled brain images, with the tumor regions already identified by experts. The algorithm can then learn to identify these tumor regions in new images.
Convolutional neural networks (CNNs) are a type of machine learning model that has been successful in image classification and segmentation tasks and are often used for brain tumor segmentation. In a CNN, the input image is passed through multiple layers of filters that learn to recognize specific features in the image. The output of the CNN is a segmented image, with each pixel classified as either part of the tumor or healthy tissue.
Another approach to brain tumor segmentation is to use unsupervised learning, where the algorithm is not given any labelled examples and must learn to identify patterns in the data on its own. One unsupervised method for brain tumor segmentation is to use clustering algorithms, which can group similar pixels together and identify the tumor region as a separate cluster. However, unsupervised learning is not commonly used for brain tumor segmentation due to the complexity and variability of the data.
Regardless of the approach used, the performance of brain tumor segmentation algorithms can be evaluated using metrics such as dice coefficient, Jaccard index, and sensitivity.
Our medical imaging AI solution is designed to be used widely and in a cost-effective manner. Our approach ensures that the accuracy of the model is not compromised while still being affordable. We have used a U-Net 2D model that can be trained using the Habana® Gaudi® platform and the Medical Decathlon dataset (BraTS 2017 Brain Tumor Dataset) to achieve the best possible accuracy for image segmentation. The model can then be used for inferencing with the OpenVINO™ on Intel® Architecture.
This reference implementation provides an AWS*cloud-based generic AI workflow, which showcases U-Net-2D model-based image segmentation with the medical decathlon dataset. The reference implementation is available for use by Docker containers and Helm chart.

Training:
Primarily, we are leveraging AWS* EC2 DL1workflows to train U-Net 2D models for the end-to-end pipeline. We are consistently seeing cost savings compared to existing GPU-based instances across model types, enabling us to achieve much better Time-to-Market for existing models or training much larger and more complex models.
AWS*DL1 instances with Gaudi® accelerators offer the best price-performance savings compared to other GPU offerings in the market. The models were trained using the Pytorch framework.
The reference training code with detailed instructions is available here.
Inference and Optimization:
Intel® OpenVINO™ is an inference solution that optimizes and accelerates the computation of AI workloads on Intel® hardware. The trained Pytorch models were converted to ONNX (Open Neural Network Exchange) model representation format and then further optimized to the OpenVINO™ format or Intermediate representation (IR) of OpenVINO™ using the Model Optimizer tool from OpenVINO™.
TheFP32-optimized IR models outperformed using OpenVINO™ runtime in terms of throughput compared to other Deep Learning framework runtimes on the same Intel® hardware.
Asa next step, the FP32 IR model was further optimized and converted to lower8-bit precision with post-training quantization using the default quantization algorithm from the Post Training Optimization Tool (POT) from the OpenVINO™ toolkit. This inherently leads to a jump in the model’s performance, in terms of its processing speed and throughput, for you get a higher FPS when dealing with video streams with very negligible loss in accuracy.
TheINT8 IR models performed extremely well for inference on Intel® CPU(Central Processing Unit) 3rd Generation Intel® Xeon.
The reference inference code with detailed instructions is available here.
GitHub: https://github.com/intel/cv-training-and-inference-openvino/tree/main/gaudi-segmentation-unet-ptq
Developer Catalog: https://www.intel.com/content/www/us/en/developer/articles/reference-implementation/gaudi-processor-training-and-inference-openvino.html
Inference Result:
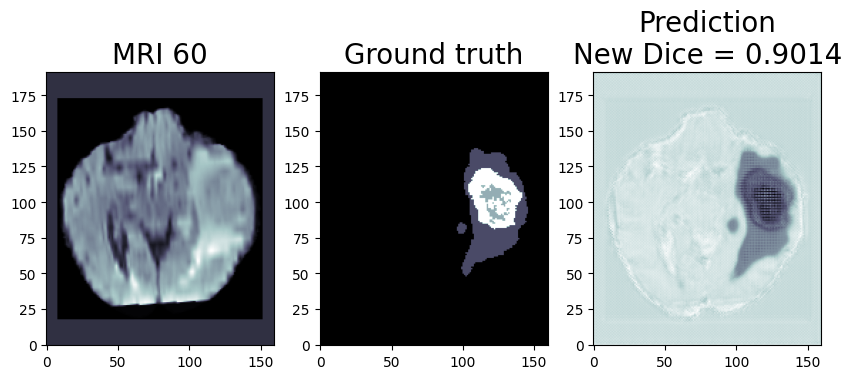
We are using OpenVINO™ Model Optimizer(MO) to convert the trained ONNX FP32 model to FP32 OpenVINO™ or Intermediate Representation(IR) format. The FP32prediction shown here is from a test image from the training dataset which was never used for training. The prediction is from a trained model which was trained for 8 epochs with 8 HPU multi-card training on an AWS* EC2 DL1 Instance with 400/484 images from the training folder.
Quantization (Recommended to use if you need the better performance of the model)
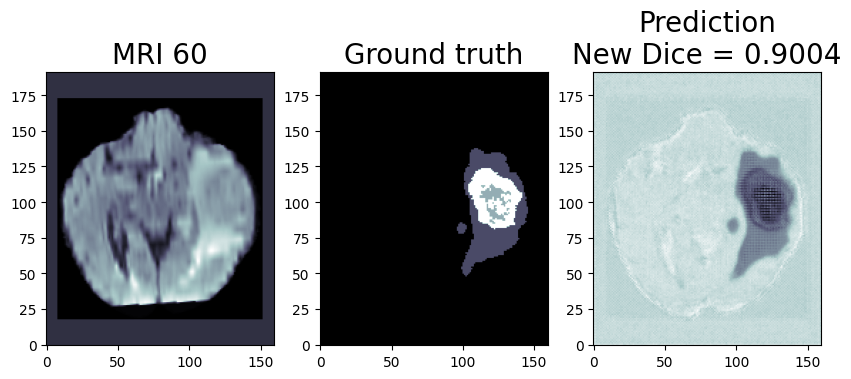
Quantization is the process of converting a deep learning model’s weight to a lower precision requiring less computation. This inherently leads to an increase in model performance, in terms of its processing speed and throughput, you will see a higher throughput(FPS) when dealing with video streams. We are using OpenVINO™ POT for the Default Quantization Algorithm to quantize the FP32 OpenVINO™ format model into the INT8 OpenVINO™ format model.
The INT8 prediction shown here is from a testimage from a training dataset that was never used for training. The predictionis from a quantized model which we quantized using POT with a calibrationdataset of 300 samples.
This application is available on the Intel® Developer Catalog for the developers to use as it is or use as a base code to bootstrap their customized solution. Intel® Developer Catalog offers reference implementations and software packages to build modular applications using containerized building blocks. Using the containerized building blocks the developers can rapidly develop deployable solutions.
Conclusion:
In conclusion, brain tumor segmentation using machine learning can help improve the accuracy and efficiency of the diagnosis and treatment of brain tumors.
There are several challenges and limitations to using machine learning for brain tumor segmentation. One of the main challenges is the limited availability of annotated data, as it is time consuming and expensive to annotate large datasets of medical images. In addition, there is a high degree of variability and complexity in the data, as brain tumors can have different shapes, sizes, and intensity patterns on MRI scans. This can make it difficult for the machine learning algorithm to generalize and accurately classify tumors in new data.
Another challenge is the potential for bias in the training data, as the dataset may not be representative of the entire population. This can lead to inaccurate or biased results if the algorithm is not properly trained or validated.
While there are still challenges to be overcome, the use of machine learning in medical image analysis shows great promise for improving patient care.
Notices & Disclaimers:
Intel technologies may require enabled hardware, software or service activation.
No product or component can be absolutely secure.
Your costs and results may vary.
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
Build OpenVINO™ Docker Image on CentOS 7
Authors: Xiake Sun, Su Yang
For OpenVINO™ 2022.1 on CentOS 7.6, we provide the dockerfile based on the docker_ci and usage instructions in this blog.
At present, OpenVINO™ officially only provides a docker image of OpenVINO™ 2021.3 for CentOS 7 on DockerHub. To deploy a docker image with the OpenVINO™ toolkit, OpenVINO™ provides the DockerHub CI named docker_ci. However, docker_ci doesn’t support CentOS 7.
Here are the steps to build the OpenVINO™ 2022.1.0 Docker Image on CentOS 7.6 with Python 3.6. In this instruction, we use Python 3.6 in the docker image as an example. If upgrading the version, the user needs to solve problems with yum and related tools.
Setup of OpenVINO™
0. Build OpenVINO™ 2022.1.0 with CMake 3.18.4 and GCC 8.3.1
Install docker on CentOS 7 and setup proxy (if any):
https://docs.docker.com/engine/install/centos/
https://docs.docker.com/engine/install/linux-postinstall/#manage-docker-as-a-non-root-user
https://docs.docker.com/config/daemon/systemd/
1. Download CMake 3.18.4
2. Install devtoolset-8 and Setup Environment
3. Build OpenVINO™ 2022.1.0 docker image with CMake 3.18.4 and GCC 8.3.1
4. Compress pre-built OpenVINO™ 2022.1.0 install package as .tgz
Setup of Docker Image
1. Build OpenVINO™ dev docker image for CentOS 7

2. Start Docker image
3. Test docker image with OpenVINO™ tools
Build OpenVINO on CentOS 7 with Script
Authors: Xiake Sun, Su Yang
We provide a script to help users easily install and test OpenVINO™ on CentOS 7.6. This script is a practice and supplement to the Building OpenVINO™ on CentOS 7 Guide in the OpenVINO™ wiki. The installation of OpenVINO™ 2022.1.0 and 2022.2.0 has been verified under the following eight configurations of CentOS 7.6 (GCC:7.3.1, 8.3.1 and Python: 3.6,3.7, 3.8, 3.9). The script could also be used for the newer version of OpenVINO with some modifications in the future.
CentOS 7 is an open-source server operating system released by the CentOS project. It was officially released on July 7, 2014. CentOS 7 is an enterprise-level Linux distribution, which is redistributed from the free and open-source code of RedHat, and its stability is trustworthy. The CentOS community and RedHat have announced that CentOS 8 will end on December 31, 2021, and CentOS 7 will end on June 30, 2024. Therefore, CentOS 7 is still the mainstream operating system of most cloud platforms.
However, CentOS 7 default GCC 4.8.5 and CMake 2.8.12 does not meet the OpenVINO software requirement for building on a Linux system. Since OpenVINO™ release 2022.1, the binary and python wheel installation packages will not be provided on CentOS 7. To help users with the verification and integration of the OpenVINO™ new version, Here we provide the installation guide and script.
Script Usage
1.Download OpenVINO™ and Script:
2.Usage Example:
3.Script Execution Time:
The environment configuration and dependency library download time are dependent on the network environment and will not be downloaded repeatedly. Compile time depends on the hardware. Every time the script is run, the user needs clean up the previous compilation-related folders (install, build, temp) and recompile.
4.Hints:
Contents
The script steps are similar to the Building OpenVINO™ on CentOS 7 Guide. Here are the contents with some comments. For details, please refer to the script and wiki guide.
0. Install system dependencies setup on CentOS 7.6 and install Anaconda
To test more Python version, we use Anaconda instead of Miniconda. Anaconda silent installation is recommended to avoid manually agreeing to the certificate and restarting bash (the script part is as shown below).
1. Download CMake
Download the pre-built CMake 3.18.4 and add environment variables: no need to change the existing CMake version of the system and no need to compile.
2. Install devtoolset and setup environment
Because CentOS7 was released too early, the default GCC version is 4.8.5, which does not support the compilation of OpenVINO™. Using devtoolset can install a higher version of GCC without changing the system GCC version.
The library Wheel is one of Python dependencies. Wheel 0.37.1 is recommended for OpenVINO 2022.1.0 and 2022.2.0. The higher version of Wheel is not suitable.
3. Build OV with CMake
Create a Python environment with conda and check the name of Python library and header folder.
4. Install Python Wheels
Install the two generated wheels.(runtime and development tool)
5.Model evaluation with benchmark_app and OpenVINO™ CLI usage
Install the specified version of dependencies, for ONNX 1.12 not support python3.6.
Quickly download and convert models from OpenVINO™ Toolkit - Open Model Zoo repository.
C++/Python benchmark_app: The C++ version requires additional compilation, with the Python version by default.
In the end, the script will show the OpenVINO™ usage example as below.
Q4'22: Technology update – low precision and model optimization
Authors
Alexander Kozlov, Pablo Munoz, Vui Seng Chua, Nikolay Lyalyushkin, Nikita Savelyev, Yury Gorbachev, Nilesh Jain
Summary
We still observe a lot of attention to the quantization and the problem of recovering accuracy after quantization. We highly recommend reading SmoothQuantpaper from the Highlights published by Song Han Lab about improving the accuracy of quantized Transformer models.
Highlights
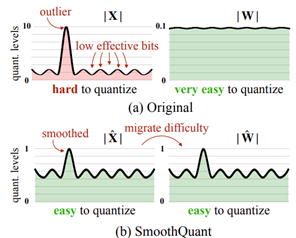
- SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models by MIT and Nvidia (https://arxiv.org/pdf/2211.10438.pdf). A training-free, accuracy preserving, and general-purpose post-training quantization (PTQ) solution to enable 8-bit weight, 8-bit activation (W8A8)quantization for LLMs that can be implemented efficiently. SmoothQuant smooths the activation outliers by migrating the quantization difficulty from activations to weights with a mathematically equivalent transformation. Concretely, they compute activation statistics using a few sequences and then use these to scale down the activations and scale up the weights such that the worst-case outliers are minimized. Demonstrate up to 1.56× speedup and 2× memory reduction for LLMs with negligible loss in accuracy
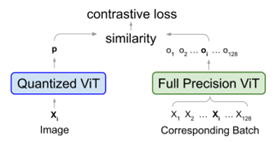
- CPT-V: A Contrastive Approach to Post-Training Quantization of Vision Transformers by University of Texas at Austin and ARM Inc. (https://arxiv.org/pdf/2211.09643.pdf). The method finds the optimal set of quantization scales that globally minimizes a contrastive loss without changing weights. CPT-V proposes a block-wise evolutionary search to minimize a global contrastive loss objective, allowing for accuracy improvement of existing vision transformer (ViT) quantization schemes. CPT-V improves the top-1 accuracy of a fully quantized ViT-Base by 10:30%, 0:78%, and 0:15% for 3-bit,4-bit, and 8-bit weight quantization levels.
Papers with notable results
Quantization
- SUB-8-BIT QUANTIZATION FORON-DEVICE SPEECH RECOGNITION: A REGULARIZATION-FREE APPROACH by Amazon Alexa AI (https://arxiv.org/pdf/2210.09188.pdf). The paper introduces a method for ASR models compression that enables on-centroid weight aggregation without augmented regularizes. Instead, it leverages Softmax annealing to impose soft-to-hard quantization on centroids from the µ-Law constrained space. The method supports different quantization modes for a wide range of granularity: different bit depths can be specified for different kernels/layers/modules. The method allows compressing a Conformer into sub-5-bit with more than 6x model size reduction and Bifocal RNN-T into5-bit that reduces the memory footprint by 30.73% and P90 user-perceived latency by 31.30% compared to INT8.
- Outlier Suppression: Pushing the Limit of Low-bit Transformer Language Models by SenseTime Research and Chinese Universities (https://arxiv.org/pdf/2209.13325.pdf). Propose an outlier suppression framework including two components: Gamma Migration and Token-Wise Clipping. The Gamma Migration produces a more quantization-friendly model by migrating the outlier amplifierγ of LayerNorm into subsequent modules in an equivalent transformation and bringing more robust activation for quantization without extra computation burden. The Token-Wise Clipping further efficiently finds a suitable clipping range with minimal final quantization loss in a coarse-to-fine procedure. The coarse-grained stage, which leverages the fact that those less important outliers only belong to a few tokens, can obtain a preliminary clipping range quickly in a token-wise manner. The fine-grained stage then optimizes it. However, it onlysucceeds on small language models such as BERT, RoBERTa, BART and fails to maintain the accuracy for LLMs. The PyTorch implementation is available: https://github.com/wimh966/outlier_suppression.
- GPTQ: ACCURATE POST-TRAININGQUANTIZATION FOR GENERATIVE PRE-TRAINED TRANSFORMERS by ETH Zurich and IST Austria (https://arxiv.org/pdf/2210.17323.pdf). The paper introduces a method for low-bit quantization of transformer models. Essentially, the method combines Layer-wise fine-tuning of quantization parameters with Optimal Brain Quantization method for bit-width selection. The Code is available here: https://github.com/IST-DASLab/gptq.
- NoisyQuant: Noisy Bias-Enhanced Post-Training Activation Quantization for Vision Transformers by Nanji, Peking and Berkeley universities (https://arxiv.org/pdf/2211.16056.pdf).Authors provide a theoretical justification for a way to reduce the quantization error of heavy-tailed distributions with a fixed additive noisy bias. They propose a method for a quantizer-agnostic enhancement for post-training quantization (PTQ) performance on activation quantization. The method is applied on top of existing PTQ quantizers and shows superior results for Vision Transformer models trained on ImageNet dataset: up to 1.7% improvement for a linear quantization scheme up to 0.7% for a nonlinear one.
- Exploiting the Partly Scratch-off Lottery Ticket for Quantization-Aware Training by Tencent and Chinese Universities (https://arxiv.org/pdf/2211.08544.pdf). In this paper, the authors claim the phenomenon that a large portion of quantized weights reaches the optimal quantization level after a few training epochs. Based on this observation, they zero out gradient calculations of these weights in the remaining training period to avoid meaningless updating. To find the ticket, authors develop a heuristic method that freezes a weight once the distance between the full-precision one and its quantization level is smaller than a controllable threshold. The method helps to eliminate 30%-60%weight updating and 15%-30% FLOPs of the backward pass, while keeping the baseline performance. For example, it improves 2-bit ResNet-18 by 1.41%,eliminating 56% weight updating and 28% FLOPs of the backward pass. Code is at https://github.com/zysxmu/LTS.
- QFT: Post-training quantization via fast joint finetuning of all degrees of freedom by Hailo AI (https://arxiv.org/pdf/2212.02634.pdf).The paper proposes a modification of the layer-wise/channel-wise post-training quantization method where all the parameters are trained jointly including the layer weights, quantization scales, cross-layer factorization parameters to reduce the overall quantization error. The training setup is common and uses the original model as a teacher for layer-wise KD. The method achieves results in a4-bit, 8-bit quantization setup.
- Make RepVGG Greater Again: A Quantization-aware Approach by Meituan (https://arxiv.org/pdf/2212.01593.pdf). An interesting read about the challenges in the quantization of RepVGG model. Authors analyze what exactly leads to the significant accuracy degradation when quantizing this model to 8-bits. They found a high variance in activations of some layers which is induced by the model architecture. They propose several tricks (essentially normalization and regularization changes) that can be applied along with QAT. With such changes, they can achieve < 2% of accuracy degradation. BTW, OpenVINO team finding is that using FP8 data types it is possible to stay within ~1% of accuracy drop compared to FP32 baseline without bells and whistles. Only scaling and Bias Correction are required.
- A Closer Look at Hardware-Friendly Weight Quantization by Google Research (https://arxiv.org/pdf/2210.03671.pdf). Authors study the two quantization scale estimation methods to identify the sources of performance differences between the two classes, namely, sensitivity to outliers and convergence instability of the quantizer scaling factor. It is done in strong HW constraints: uniform, per-tensor, symmetric quantization. They propose various techniques to improve the performance of both quantization methods - they fix the optimization instability issues present in the MSQE-based methods during the quantization of MobileNet models and allow us to improve the validation performance of the gradient-based methods. The proposed method achieves superior results in those constraints.
- CSMPQ: CLASS SEPARABILITYBASED MIXED-PRECISION QUANTIZATION by universities of China (https://arxiv.org/pdf/2212.10220.pdf). The paper introduces the class separability of layer-wise feature maps to search for optimal quantization bit-width. Essentially, authors leverage the TF-IDF metric from NLP to measure the class separability of layer-wise feature maps that are averaged across spatial dimensions. The method can be applied on top of the existing quantization algorithms, such as BRECQ and delivers good results, e.g. 71.30% top-1 acc with only 1.5Mb on MobileNetV2.
Pruning
- Structured Pruning Adapters by Aarhus University and Cactus Communications (https://arxiv.org/pdf/2211.10155.pdf). The paper introduces task-switching network adapters that accelerate and specialize networks for downstream tasks. Authors propose channel- and block-based adaptors and evaluate them with a suite of pruning methods on both computer vision and natural language processing benchmarks. The method achieves comparable results when downstream ResNEt-50 ImageNet to CIFAR, Flowers, Cats and Dogs and BERT to SQuAD v1.1. The code is available at: https://github.com/lukashedegaard/structured-pruning-adapters.
- HeatViT: Hardware-Efficient Adaptive Token Pruning for Vision Transformers by Northeastern University, Simon Fraser University, and CoCoPIE LLC (https://arxiv.org/pdf/2211.08110.pdf). The paper introduces an algorithm and FPGA co-design for a token selector to enable image adaptive token pruning in Visual Transformers. Authors also propose a latency-aware multi-stage training strategy to learn the insertion of token selectors in ViTs. They also replace non-linearities inside ViT models with polynomial approximations and stack token pruning with 8-bit quantization. The method can achieve 28.4%∼65.3% computation reduction, for various widely used ViTs on the ImageNet, and 3.46×∼4.89× speedup with a trivial resource utilization overhead on FPGA.
- Soft Masking for Cost-Constrained Channel Pruning by Stanford University and Nvidia (https://arxiv.org/pdf/2211.02206.pdf). Authors propose a filter pruning method with a soft mask re-parameterization of the network weights so that channel sparsity can be adaptively rewired. They also apply a scaling technique for the batch normalization weights to mitigate gradient instability at high channel pruning ratios. To perform channel pruning subject to a cost constraint, authors reformulate it as the multiple-choice knapsack problem. The method achieves SOTA results on ImageNet and VOC tasks. The code is available at: https://github.com/NVlabs/SMCP.
- Pruning’s Effect on Generalization Through the Lens of Training and Regularization by MIT, University of Toronto, Mosaic ML, and Google Brain (https://arxiv.org/pdf/2210.13738.pdf). Authors study the impact of model pruning on the generalization capabilities. Even though the study is conducted on toy examples, it’s quite extensive and proves known facts that pruning can be considered as an additional regularization and can lead to better training results.
- oViT: An Accurate Second-Order Pruning Framework for Vision Transformers by Yandex, Neural Magic, and IST Austria (https://arxiv.org/pdf/2210.09223.pdf). Authors introduce an approximate second-order pruner for Vision Transformer models that estimates sparsity ratios for different parts of the model. They also provide a set of general sparse fine-tuning recipes, enabling accuracy recovery at reasonable computational budgets. In addition, the authors propose a pruning framework that produces sparse accurate models for a sequence of sparsity targets in a single run, accommodating various deployments under a fixed compute budget. The method is evaluated on various ViT models including classical ViT, DeiT, XCiT, EfficientFormer and Swin, and shows SOTA results(e.g. 75% of sparsity at <1% of accuracy drop).
- A Fast Post-Training Pruning Framework for Transformers by UC Berkeley and Samsung (https://arxiv.org/pdf/2204.09656.pdf). The proposed method prunes Transformer models without any fine-tuning. When applied to BERT and DistilBERT authors achieve 2.0x reduction in FLOPs and 1.56x speedup in inference latency while maintaining < 1% accuracy loss. Notably, the whole pruning process finishes in less than 3 minutes on a single GPU. The method consists of three main stages: (1) a lightweight mask search algorithm finds which Transformer heads and filters to prune based on the Fisher information (2) mask rearrangement that improves binary masks produced by the previous stage and (3) mask tuning tweaks some of the 1's in the mask by making them real-valued.
- Fast DistilBERT on CPUs by Intel (https://arxiv.org/pdf/2211.07715.pdf). The work proposes a new pipeline to apply Prune-OFA with block-wise structured pruning, jointly with quantize-aware training and distillation. The work also provides an advanced Int8 sparse GEMM inference engine which is friendly to Intel VNNI instructions as a companion runtime to accelerate the resultant model from the proposed pipeline. DistilBERT/SQuADv1.1 optimized by the pipeline and deployed with the new engine outperforms Neural Magic’s proprietary sparse inference engine in throughput performance (under production latency constraint) by 50% and 4.1X over low-precision performance of ONNXRuntime. Source code can be found at https://github.com/intel/intel-extension-for-transformers.
Neural Architecture Search
- EZNAS: Evolving Zero-Cost Proxies for Neural Architecture Scoring by Intel Labs (https://openreview.net/forum?id=lSqaDG4dvdt). Authors propose a genetic programming approach to automate the discovery of zero-cost neural architecture scoring metrics. The discovered metrics outperform existing hand-crafted metrics and generalize well across neural architecture design spaces. Two search spaces are explored using EZNAS:NASBench-201 and Network Design Spaces (NDS), demonstrating the strong generalization capabilities of the discovered zero-cost metrics.
- Resource-Aware Heterogenous Federated Learning using Neural Architecture Search by Iowa State University and Intel Labs (https://arxiv.org/pdf/2211.05716.pdf). This paper proposes a framework for Resource-aware Federated Learning (RaFL). The framework uses Neural Architecture Search (NAS)to enable on-demand specialized model deployment for resource-diverse edge devices. Furthermore, the framework uses a novel model architecture fusion scheme to allow for the aggregation of the distributed learning results. RaFL demonstrates superior resource efficiency and reduction in communication overhead compared to state-of-the-art solutions.
- NAS-LID: Efficient Neural Architecture Search with Local Intrinsic Dimension by Nvidia and universities of China, India, and GB (https://arxiv.org/pdf/2211.12759.pdf). Authors first apply the so-called local intrinsic dimension (LID) method that evaluates the geometrical properties of sampled model architectures by calculating the low-cost LID features layer-by-layer, and the similarity characterized by LID. The method can be embedded into the existing NAS frameworks, e.g. OFA of Proxyless NAS. The method significantly accelerates architecture search time and shows comparable performance on public benchmarks. The code is available: https://github.com/marsggbo/NAS-LID.
- Automatic Subspace Evoking for Efficient Neural Architecture Search by Hisense and universities of China (https://arxiv.org/pdf/2210.17180.pdf). A method that proposes to decouple architecture search into global and local search steps that are aimed at enhancing the performance of NAS. Specifically, we first perform a global search to find promising subspaces and then perform a local search to obtain the resultant architectures. The method exploits GNN and RNN models in the search algorithm that are trained jointly. The method shows superior results compared to some well-known NAS frameworks.
- AUTOMOE: NEURAL ARCHITECTURESEARCH FOR EFFICIENT SPARSELY ACTIVATED TRANSFORMERS by Microsoft Research and University of British Columbia (https://arxiv.org/pdf/2210.07535.pdf). Authors introduce heterogeneous search space for Transformers consisting of variable number, FFN size and placement of experts in both encoders and decoders; variable number of layers, attention heads and intermediate FFN dimension of standard Transformer modules. They extend Supernet training to this new search space which combines all possible sparse architectures into a single graph and jointly trains them via weight-sharing. They also use an evolutionary algorithm to search for optimal sparse architecture from Supernet with the best possible performance on a downstream task. The method shows better results compared to dense NAS methods for Transformers.
Other
- GhostNetV2: Enhance Cheap Operation with Long-Range Attention by Huawei, Peking University, and University of Sydney (https://arxiv.org/pdf/2211.12905.pdf). In this paper, authors propose a hardware-friendly attention mechanism (dubbed DFC attention) and GhostNetV2 architecture for mobile applications. The proposed DFC attention is aimed at capturing the dependence between long-range pixels. They also revisit the expressiveness bottleneck in previous GhostNet and propose to enhance expanded features so that a GhostNetV2 block can aggregate local and long-range information simultaneously. The approach shows good results, 75.3% top-1 accuracy on ImageNet with 167M FLOPs. The code is available at https://github.com/huawei-noah/Efficient-AI-Backbones/tree/master/ghostnetv2_pytorch.
Deep Learning Software
- Nivida open-sourced Transformer Engine – a plugin that helps to train Transformers in FP8 data types: https://github.com/NVIDIA/TransformerEngine.
- Accelerate your models with HuggingFace Optimum Intel and OpenVINO: A blog post about new API capabilities to run Transformer models on Intel CPU and GPU with OpenVINO and optimize with NNCF – https://huggingface.co/blog/openvino.
Deep Learning Hardware
- Faster Training and Inference: Habana Gaudi®-2 vs Nvidia A100 80GB: A post about Habana Gaudi 2 accelerating model training and inference in AWS – https://huggingface.co/blog/habana-gaudi-2-benchmark.
- Alibaba Cloud unveils the new Arm server chip - Yitian 710, with the 5nm process, withInt8 MatMul, BFloat16.